Mengying Wang, Cuixia Lee, Zhenhao Wei, Hong Ji, Yingyun Yang, Cheng Yang
{"title":"基于电子病历的肺结核临床辅助决策模型","authors":"Mengying Wang, Cuixia Lee, Zhenhao Wei, Hong Ji, Yingyun Yang, Cheng Yang","doi":"10.1186/s13040-023-00328-y","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Tuberculosis is a dangerous infectious disease with the largest number of reported cases in China every year. Preventing missed diagnosis has an important impact on the prevention, treatment, and recovery of tuberculosis. The earliest pulmonary tuberculosis prediction models mainly used traditional image data combined with neural network models. However, a single data source tends to miss important information, such as primary symptoms and laboratory test results, that is available in multi-source data like medical records and tests. In this study, we propose a multi-stream integrated pulmonary tuberculosis diagnosis model based on structured and unstructured multi-source data from electronic health records. With the limited number of lung specialists and the high prevalence of tuberculosis, the application of this auxiliary diagnosis model can make substantial contributions to clinical settings.</p><p><strong>Methods: </strong>The subjects were patients at the respiratory department and infectious cases department of a large comprehensive hospital in China between 2015 to 2020. A total of 95,294 medical records were selected through a quality control process. Each record contains structured and unstructured data. First, numerical expressions of features for structured data were created. Then, feature engineering was performed through decision tree model, random forest, and GBDT. Features were included in the feature exclusion set as per their weights in descending order. When the importance of the set was higher than 0.7, this process was concluded. Finally, the contained features were used for model training. In addition, the unstructured free-text data was segmented at the character level and input into the model after indexing. Tuberculosis prediction was conducted through a multi-stream integration tuberculosis diagnosis model (MSI-PTDM), and the evaluation indices of accuracy, AUC, sensitivity, and specificity were compared against the prediction results of XGBoost, Text-CNN, Random Forest, SVM, and so on.</p><p><strong>Results: </strong>Through a variety of characteristic engineering methods, 20 characteristic factors, such as main complaint hemoptysis, cough, and test erythrocyte sedimentation rate, were selected, and the influencing factors were analyzed using the Chinese diagnostic standard of pulmonary tuberculosis. The area under the curve values for MSI-PTDM, XGBoost, Text-CNN, RF, and SVM were 0.9858, 0.9571, 0.9486, 0.9428, and 0.9429, respectively. The sensitivity, specificity, and accuracy of MSI-PTDM were 93.18%, 96.96%, and 96.96%, respectively. The MSI-PTDM prediction model was installed at a doctor workstation and operated in a real clinic environment for 4 months. A total of 692,949 patients were monitored, including 484 patients with confirmed pulmonary tuberculosis. The model predicted 440 cases of pulmonary tuberculosis. The positive sample recognition rate was 90.91%, the false-positive rate was 9.09%, the negative sample recognition rate was 96.17%, and the false-negative rate was 3.83%.</p><p><strong>Conclusions: </strong>MSI-PTDM can process sparse data, dense data, and unstructured text data concurrently. The model adds a feature domain vector embedding the medical sparse features, and the single-valued sparse vectors are represented by multi-dimensional dense hidden vectors, which not only enhances the feature expression but also alleviates the side effects of sparsity on the model training. However, there may be information loss when features are extracted from text, and adding the processing of original unstructured text makes up for the error within the above process to a certain extent, so that the model can learn data more comprehensively and effectively. In addition, MSI-PTDM also allows interaction between features, considers the combination effect between patient features, adds more complex nonlinear calculation considerations, and improves the learning ability of the model. It has been verified using a test set and via deployment within an actual outpatient environment.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"11"},"PeriodicalIF":4.0000,"publicationDate":"2023-03-16","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10022184/pdf/","citationCount":"0","resultStr":"{\"title\":\"Clinical assistant decision-making model of tuberculosis based on electronic health records.\",\"authors\":\"Mengying Wang, Cuixia Lee, Zhenhao Wei, Hong Ji, Yingyun Yang, Cheng Yang\",\"doi\":\"10.1186/s13040-023-00328-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Tuberculosis is a dangerous infectious disease with the largest number of reported cases in China every year. Preventing missed diagnosis has an important impact on the prevention, treatment, and recovery of tuberculosis. The earliest pulmonary tuberculosis prediction models mainly used traditional image data combined with neural network models. However, a single data source tends to miss important information, such as primary symptoms and laboratory test results, that is available in multi-source data like medical records and tests. In this study, we propose a multi-stream integrated pulmonary tuberculosis diagnosis model based on structured and unstructured multi-source data from electronic health records. With the limited number of lung specialists and the high prevalence of tuberculosis, the application of this auxiliary diagnosis model can make substantial contributions to clinical settings.</p><p><strong>Methods: </strong>The subjects were patients at the respiratory department and infectious cases department of a large comprehensive hospital in China between 2015 to 2020. A total of 95,294 medical records were selected through a quality control process. Each record contains structured and unstructured data. First, numerical expressions of features for structured data were created. Then, feature engineering was performed through decision tree model, random forest, and GBDT. Features were included in the feature exclusion set as per their weights in descending order. When the importance of the set was higher than 0.7, this process was concluded. Finally, the contained features were used for model training. In addition, the unstructured free-text data was segmented at the character level and input into the model after indexing. Tuberculosis prediction was conducted through a multi-stream integration tuberculosis diagnosis model (MSI-PTDM), and the evaluation indices of accuracy, AUC, sensitivity, and specificity were compared against the prediction results of XGBoost, Text-CNN, Random Forest, SVM, and so on.</p><p><strong>Results: </strong>Through a variety of characteristic engineering methods, 20 characteristic factors, such as main complaint hemoptysis, cough, and test erythrocyte sedimentation rate, were selected, and the influencing factors were analyzed using the Chinese diagnostic standard of pulmonary tuberculosis. The area under the curve values for MSI-PTDM, XGBoost, Text-CNN, RF, and SVM were 0.9858, 0.9571, 0.9486, 0.9428, and 0.9429, respectively. The sensitivity, specificity, and accuracy of MSI-PTDM were 93.18%, 96.96%, and 96.96%, respectively. The MSI-PTDM prediction model was installed at a doctor workstation and operated in a real clinic environment for 4 months. A total of 692,949 patients were monitored, including 484 patients with confirmed pulmonary tuberculosis. The model predicted 440 cases of pulmonary tuberculosis. The positive sample recognition rate was 90.91%, the false-positive rate was 9.09%, the negative sample recognition rate was 96.17%, and the false-negative rate was 3.83%.</p><p><strong>Conclusions: </strong>MSI-PTDM can process sparse data, dense data, and unstructured text data concurrently. The model adds a feature domain vector embedding the medical sparse features, and the single-valued sparse vectors are represented by multi-dimensional dense hidden vectors, which not only enhances the feature expression but also alleviates the side effects of sparsity on the model training. However, there may be information loss when features are extracted from text, and adding the processing of original unstructured text makes up for the error within the above process to a certain extent, so that the model can learn data more comprehensively and effectively. In addition, MSI-PTDM also allows interaction between features, considers the combination effect between patient features, adds more complex nonlinear calculation considerations, and improves the learning ability of the model. It has been verified using a test set and via deployment within an actual outpatient environment.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"16 1\",\"pages\":\"11\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2023-03-16\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10022184/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-023-00328-y\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00328-y","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Clinical assistant decision-making model of tuberculosis based on electronic health records.
Background: Tuberculosis is a dangerous infectious disease with the largest number of reported cases in China every year. Preventing missed diagnosis has an important impact on the prevention, treatment, and recovery of tuberculosis. The earliest pulmonary tuberculosis prediction models mainly used traditional image data combined with neural network models. However, a single data source tends to miss important information, such as primary symptoms and laboratory test results, that is available in multi-source data like medical records and tests. In this study, we propose a multi-stream integrated pulmonary tuberculosis diagnosis model based on structured and unstructured multi-source data from electronic health records. With the limited number of lung specialists and the high prevalence of tuberculosis, the application of this auxiliary diagnosis model can make substantial contributions to clinical settings.
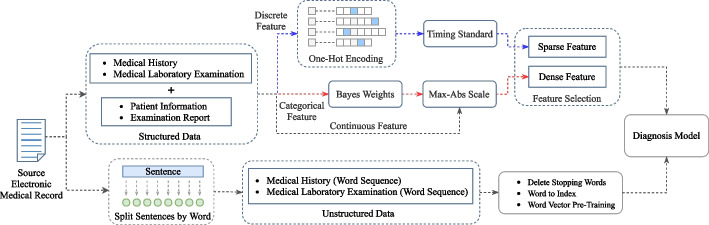
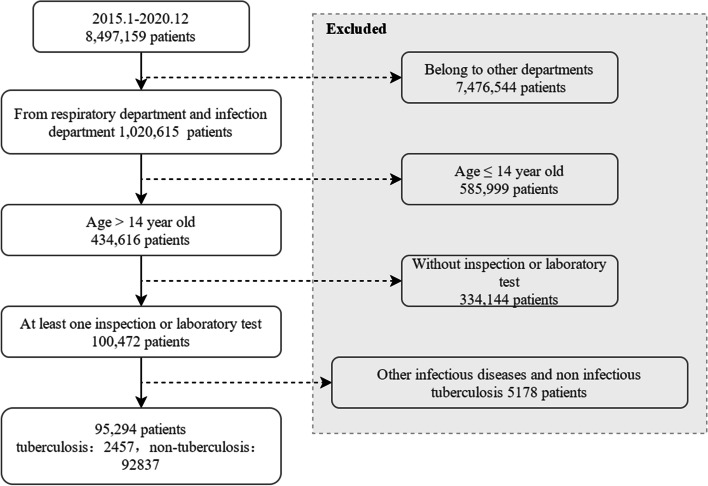
Methods: The subjects were patients at the respiratory department and infectious cases department of a large comprehensive hospital in China between 2015 to 2020. A total of 95,294 medical records were selected through a quality control process. Each record contains structured and unstructured data. First, numerical expressions of features for structured data were created. Then, feature engineering was performed through decision tree model, random forest, and GBDT. Features were included in the feature exclusion set as per their weights in descending order. When the importance of the set was higher than 0.7, this process was concluded. Finally, the contained features were used for model training. In addition, the unstructured free-text data was segmented at the character level and input into the model after indexing. Tuberculosis prediction was conducted through a multi-stream integration tuberculosis diagnosis model (MSI-PTDM), and the evaluation indices of accuracy, AUC, sensitivity, and specificity were compared against the prediction results of XGBoost, Text-CNN, Random Forest, SVM, and so on.
Results: Through a variety of characteristic engineering methods, 20 characteristic factors, such as main complaint hemoptysis, cough, and test erythrocyte sedimentation rate, were selected, and the influencing factors were analyzed using the Chinese diagnostic standard of pulmonary tuberculosis. The area under the curve values for MSI-PTDM, XGBoost, Text-CNN, RF, and SVM were 0.9858, 0.9571, 0.9486, 0.9428, and 0.9429, respectively. The sensitivity, specificity, and accuracy of MSI-PTDM were 93.18%, 96.96%, and 96.96%, respectively. The MSI-PTDM prediction model was installed at a doctor workstation and operated in a real clinic environment for 4 months. A total of 692,949 patients were monitored, including 484 patients with confirmed pulmonary tuberculosis. The model predicted 440 cases of pulmonary tuberculosis. The positive sample recognition rate was 90.91%, the false-positive rate was 9.09%, the negative sample recognition rate was 96.17%, and the false-negative rate was 3.83%.
Conclusions: MSI-PTDM can process sparse data, dense data, and unstructured text data concurrently. The model adds a feature domain vector embedding the medical sparse features, and the single-valued sparse vectors are represented by multi-dimensional dense hidden vectors, which not only enhances the feature expression but also alleviates the side effects of sparsity on the model training. However, there may be information loss when features are extracted from text, and adding the processing of original unstructured text makes up for the error within the above process to a certain extent, so that the model can learn data more comprehensively and effectively. In addition, MSI-PTDM also allows interaction between features, considers the combination effect between patient features, adds more complex nonlinear calculation considerations, and improves the learning ability of the model. It has been verified using a test set and via deployment within an actual outpatient environment.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


