{"title":"用人工智能算法预测新诊断的2型糖尿病患者发生终末期肾脏疾病的风险","authors":"Shuo-Ming Ou, Ming-Tsun Tsai, Kuo-Hua Lee, Wei-Cheng Tseng, Chih-Yu Yang, Tz-Heng Chen, Pin-Jie Bin, Tzeng-Ji Chen, Yao-Ping Lin, Wayne Huey-Herng Sheu, Yuan-Chia Chu, Der-Cherng Tarng","doi":"10.1186/s13040-023-00324-2","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>Type 2 diabetes mellitus (T2DM) imposes a great burden on healthcare systems, and these patients experience higher long-term risks for developing end-stage renal disease (ESRD). Managing diabetic nephropathy becomes more challenging when kidney function starts declining. Therefore, developing predictive models for the risk of developing ESRD in newly diagnosed T2DM patients may be helpful in clinical settings.</p><p><strong>Methods: </strong>We established machine learning models constructed from a subset of clinical features collected from 53,477 newly diagnosed T2DM patients from January 2008 to December 2018 and then selected the best model. The cohort was divided, with 70% and 30% of patients randomly assigned to the training and testing sets, respectively.</p><p><strong>Results: </strong>The discriminative ability of our machine learning models, including logistic regression, extra tree classifier, random forest, gradient boosting decision tree (GBDT), extreme gradient boosting (XGBoost), and light gradient boosting machine were evaluated across the cohort. XGBoost yielded the highest area under the receiver operating characteristic curve (AUC) of 0.953, followed by extra tree and GBDT, with AUC values of 0.952 and 0.938 on the testing dataset. The SHapley Additive explanation summary plot in the XGBoost model illustrated that the top five important features included baseline serum creatinine, mean serum creatine within 1 year before the diagnosis of T2DM, high-sensitivity C-reactive protein, spot urine protein-to-creatinine ratio and female gender.</p><p><strong>Conclusions: </strong>Because our machine learning prediction models were based on routinely collected clinical features, they can be used as risk assessment tools for developing ESRD. By identifying high-risk patients, intervention strategies may be provided at an early stage.</p>","PeriodicalId":48947,"journal":{"name":"Biodata Mining","volume":"16 1","pages":"8"},"PeriodicalIF":4.0000,"publicationDate":"2023-03-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10007785/pdf/","citationCount":"5","resultStr":"{\"title\":\"Prediction of the risk of developing end-stage renal diseases in newly diagnosed type 2 diabetes mellitus using artificial intelligence algorithms.\",\"authors\":\"Shuo-Ming Ou, Ming-Tsun Tsai, Kuo-Hua Lee, Wei-Cheng Tseng, Chih-Yu Yang, Tz-Heng Chen, Pin-Jie Bin, Tzeng-Ji Chen, Yao-Ping Lin, Wayne Huey-Herng Sheu, Yuan-Chia Chu, Der-Cherng Tarng\",\"doi\":\"10.1186/s13040-023-00324-2\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>Type 2 diabetes mellitus (T2DM) imposes a great burden on healthcare systems, and these patients experience higher long-term risks for developing end-stage renal disease (ESRD). Managing diabetic nephropathy becomes more challenging when kidney function starts declining. Therefore, developing predictive models for the risk of developing ESRD in newly diagnosed T2DM patients may be helpful in clinical settings.</p><p><strong>Methods: </strong>We established machine learning models constructed from a subset of clinical features collected from 53,477 newly diagnosed T2DM patients from January 2008 to December 2018 and then selected the best model. The cohort was divided, with 70% and 30% of patients randomly assigned to the training and testing sets, respectively.</p><p><strong>Results: </strong>The discriminative ability of our machine learning models, including logistic regression, extra tree classifier, random forest, gradient boosting decision tree (GBDT), extreme gradient boosting (XGBoost), and light gradient boosting machine were evaluated across the cohort. XGBoost yielded the highest area under the receiver operating characteristic curve (AUC) of 0.953, followed by extra tree and GBDT, with AUC values of 0.952 and 0.938 on the testing dataset. The SHapley Additive explanation summary plot in the XGBoost model illustrated that the top five important features included baseline serum creatinine, mean serum creatine within 1 year before the diagnosis of T2DM, high-sensitivity C-reactive protein, spot urine protein-to-creatinine ratio and female gender.</p><p><strong>Conclusions: </strong>Because our machine learning prediction models were based on routinely collected clinical features, they can be used as risk assessment tools for developing ESRD. By identifying high-risk patients, intervention strategies may be provided at an early stage.</p>\",\"PeriodicalId\":48947,\"journal\":{\"name\":\"Biodata Mining\",\"volume\":\"16 1\",\"pages\":\"8\"},\"PeriodicalIF\":4.0000,\"publicationDate\":\"2023-03-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10007785/pdf/\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biodata Mining\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1186/s13040-023-00324-2\",\"RegionNum\":3,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biodata Mining","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1186/s13040-023-00324-2","RegionNum":3,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Prediction of the risk of developing end-stage renal diseases in newly diagnosed type 2 diabetes mellitus using artificial intelligence algorithms.
Objectives: Type 2 diabetes mellitus (T2DM) imposes a great burden on healthcare systems, and these patients experience higher long-term risks for developing end-stage renal disease (ESRD). Managing diabetic nephropathy becomes more challenging when kidney function starts declining. Therefore, developing predictive models for the risk of developing ESRD in newly diagnosed T2DM patients may be helpful in clinical settings.
Methods: We established machine learning models constructed from a subset of clinical features collected from 53,477 newly diagnosed T2DM patients from January 2008 to December 2018 and then selected the best model. The cohort was divided, with 70% and 30% of patients randomly assigned to the training and testing sets, respectively.
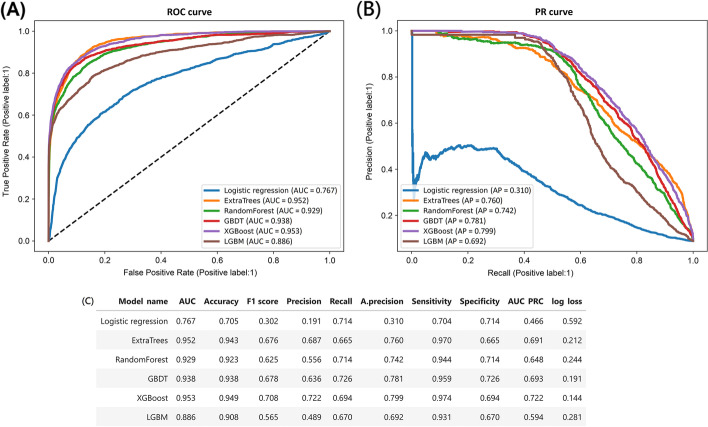
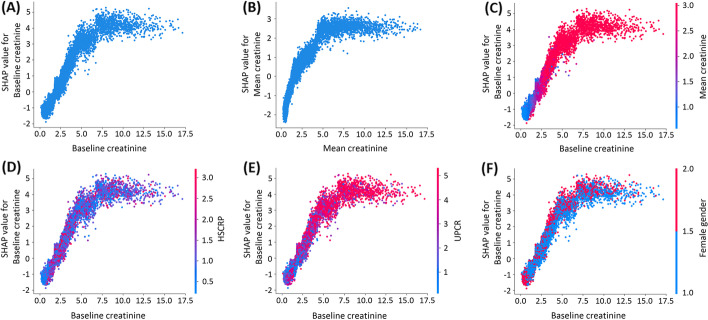
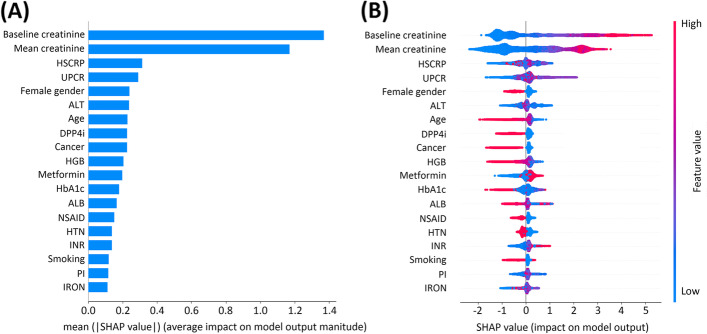
Results: The discriminative ability of our machine learning models, including logistic regression, extra tree classifier, random forest, gradient boosting decision tree (GBDT), extreme gradient boosting (XGBoost), and light gradient boosting machine were evaluated across the cohort. XGBoost yielded the highest area under the receiver operating characteristic curve (AUC) of 0.953, followed by extra tree and GBDT, with AUC values of 0.952 and 0.938 on the testing dataset. The SHapley Additive explanation summary plot in the XGBoost model illustrated that the top five important features included baseline serum creatinine, mean serum creatine within 1 year before the diagnosis of T2DM, high-sensitivity C-reactive protein, spot urine protein-to-creatinine ratio and female gender.
Conclusions: Because our machine learning prediction models were based on routinely collected clinical features, they can be used as risk assessment tools for developing ESRD. By identifying high-risk patients, intervention strategies may be provided at an early stage.
期刊介绍:
BioData Mining is an open access, open peer-reviewed journal encompassing research on all aspects of data mining applied to high-dimensional biological and biomedical data, focusing on computational aspects of knowledge discovery from large-scale genetic, transcriptomic, genomic, proteomic, and metabolomic data.
Topical areas include, but are not limited to:
-Development, evaluation, and application of novel data mining and machine learning algorithms.
-Adaptation, evaluation, and application of traditional data mining and machine learning algorithms.
-Open-source software for the application of data mining and machine learning algorithms.
-Design, development and integration of databases, software and web services for the storage, management, retrieval, and analysis of data from large scale studies.
-Pre-processing, post-processing, modeling, and interpretation of data mining and machine learning results for biological interpretation and knowledge discovery.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


