{"title":"SegViT v2:用普通视觉转换器探索高效连续的语义分割","authors":"Bowen Zhang, Liyang Liu, Minh Hieu Phan, Zhi Tian, Chunhua Shen, Yifan Liu","doi":"10.1007/s11263-023-01894-8","DOIUrl":null,"url":null,"abstract":"<p>This paper investigates the capability of plain Vision Transformers (ViTs) for semantic segmentation using the encoder–decoder framework and introduce <i>SegViTv2</i>. In this study, we introduce a novel Attention-to-Mask (ATM) module to design a lightweight decoder effective for plain ViT. The proposed ATM converts the global attention map into semantic masks for high-quality segmentation results. Our decoder outperforms popular decoder UPerNet using various ViT backbones while consuming only about <span>\\(5\\%\\)</span> of the computational cost. For the encoder, we address the concern of the relatively high computational cost in the ViT-based encoders and propose a <i>Shrunk</i>++ structure that incorporates edge-aware query-based down-sampling (EQD) and query-based up-sampling (QU) modules. The Shrunk++ structure reduces the computational cost of the encoder by up to <span>\\(50\\%\\)</span> while maintaining competitive performance. Furthermore, we propose to adapt SegViT for continual semantic segmentation, demonstrating nearly zero forgetting of previously learned knowledge. Experiments show that our proposed SegViTv2 surpasses recent segmentation methods on three popular benchmarks including ADE20k, COCO-Stuff-10k and PASCAL-Context datasets. The code is available through the following link: https://github.com/zbwxp/SegVit.</p>","PeriodicalId":13752,"journal":{"name":"International Journal of Computer Vision","volume":"31 6","pages":""},"PeriodicalIF":11.6000,"publicationDate":"2023-10-27","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"SegViT v2: Exploring Efficient and Continual Semantic Segmentation with Plain Vision Transformers\",\"authors\":\"Bowen Zhang, Liyang Liu, Minh Hieu Phan, Zhi Tian, Chunhua Shen, Yifan Liu\",\"doi\":\"10.1007/s11263-023-01894-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>This paper investigates the capability of plain Vision Transformers (ViTs) for semantic segmentation using the encoder–decoder framework and introduce <i>SegViTv2</i>. In this study, we introduce a novel Attention-to-Mask (ATM) module to design a lightweight decoder effective for plain ViT. The proposed ATM converts the global attention map into semantic masks for high-quality segmentation results. Our decoder outperforms popular decoder UPerNet using various ViT backbones while consuming only about <span>\\\\(5\\\\%\\\\)</span> of the computational cost. For the encoder, we address the concern of the relatively high computational cost in the ViT-based encoders and propose a <i>Shrunk</i>++ structure that incorporates edge-aware query-based down-sampling (EQD) and query-based up-sampling (QU) modules. The Shrunk++ structure reduces the computational cost of the encoder by up to <span>\\\\(50\\\\%\\\\)</span> while maintaining competitive performance. Furthermore, we propose to adapt SegViT for continual semantic segmentation, demonstrating nearly zero forgetting of previously learned knowledge. Experiments show that our proposed SegViTv2 surpasses recent segmentation methods on three popular benchmarks including ADE20k, COCO-Stuff-10k and PASCAL-Context datasets. The code is available through the following link: https://github.com/zbwxp/SegVit.</p>\",\"PeriodicalId\":13752,\"journal\":{\"name\":\"International Journal of Computer Vision\",\"volume\":\"31 6\",\"pages\":\"\"},\"PeriodicalIF\":11.6000,\"publicationDate\":\"2023-10-27\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International Journal of Computer Vision\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11263-023-01894-8\",\"RegionNum\":2,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International Journal of Computer Vision","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11263-023-01894-8","RegionNum":2,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE","Score":null,"Total":0}
SegViT v2: Exploring Efficient and Continual Semantic Segmentation with Plain Vision Transformers
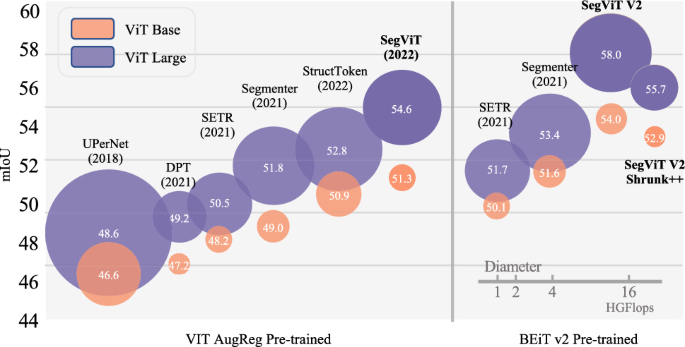
This paper investigates the capability of plain Vision Transformers (ViTs) for semantic segmentation using the encoder–decoder framework and introduce SegViTv2. In this study, we introduce a novel Attention-to-Mask (ATM) module to design a lightweight decoder effective for plain ViT. The proposed ATM converts the global attention map into semantic masks for high-quality segmentation results. Our decoder outperforms popular decoder UPerNet using various ViT backbones while consuming only about \(5\%\) of the computational cost. For the encoder, we address the concern of the relatively high computational cost in the ViT-based encoders and propose a Shrunk++ structure that incorporates edge-aware query-based down-sampling (EQD) and query-based up-sampling (QU) modules. The Shrunk++ structure reduces the computational cost of the encoder by up to \(50\%\) while maintaining competitive performance. Furthermore, we propose to adapt SegViT for continual semantic segmentation, demonstrating nearly zero forgetting of previously learned knowledge. Experiments show that our proposed SegViTv2 surpasses recent segmentation methods on three popular benchmarks including ADE20k, COCO-Stuff-10k and PASCAL-Context datasets. The code is available through the following link: https://github.com/zbwxp/SegVit.
期刊介绍:
The International Journal of Computer Vision (IJCV) serves as a platform for sharing new research findings in the rapidly growing field of computer vision. It publishes 12 issues annually and presents high-quality, original contributions to the science and engineering of computer vision. The journal encompasses various types of articles to cater to different research outputs.
Regular articles, which span up to 25 journal pages, focus on significant technical advancements that are of broad interest to the field. These articles showcase substantial progress in computer vision.
Short articles, limited to 10 pages, offer a swift publication path for novel research outcomes. They provide a quicker means for sharing new findings with the computer vision community.
Survey articles, comprising up to 30 pages, offer critical evaluations of the current state of the art in computer vision or offer tutorial presentations of relevant topics. These articles provide comprehensive and insightful overviews of specific subject areas.
In addition to technical articles, the journal also includes book reviews, position papers, and editorials by prominent scientific figures. These contributions serve to complement the technical content and provide valuable perspectives.
The journal encourages authors to include supplementary material online, such as images, video sequences, data sets, and software. This additional material enhances the understanding and reproducibility of the published research.
Overall, the International Journal of Computer Vision is a comprehensive publication that caters to researchers in this rapidly growing field. It covers a range of article types, offers additional online resources, and facilitates the dissemination of impactful research.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


