{"title":"实现持续学习的持久表征","authors":"Alaa El Khatib, Fakhri Karray","doi":"10.1007/s43674-021-00022-8","DOIUrl":null,"url":null,"abstract":"<div><p>Continual learning models are known to suffer from <i>catastrophic forgetting</i>. Existing regularization methods to countering forgetting operate by penalizing large changes to learned parameters. A significant downside to these methods, however, is that, by effectively freezing model parameters, they gradually suspend the capacity of a model to learn new tasks. In this paper, we explore an alternative approach to the continual learning problem that aims to circumvent this downside. In particular, we ask the question: instead of forcing continual learning models to remember the past, can we modify the learning process from the start, such that the learned representations are less susceptible to forgetting? To this end, we explore multiple methods that could potentially encourage durable representations. We demonstrate empirically that the use of unsupervised auxiliary tasks achieves significant reduction in parameter re-optimization across tasks, and consequently reduces forgetting, without explicitly penalizing forgetting. Moreover, we propose a distance metric to track internal model dynamics across tasks, and use it to gain insight into the workings of our proposed approach, as well as other recently proposed methods.</p></div>","PeriodicalId":72089,"journal":{"name":"Advances in computational intelligence","volume":"2 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2021-12-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s43674-021-00022-8.pdf","citationCount":"0","resultStr":"{\"title\":\"Toward durable representations for continual learning\",\"authors\":\"Alaa El Khatib, Fakhri Karray\",\"doi\":\"10.1007/s43674-021-00022-8\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Continual learning models are known to suffer from <i>catastrophic forgetting</i>. Existing regularization methods to countering forgetting operate by penalizing large changes to learned parameters. A significant downside to these methods, however, is that, by effectively freezing model parameters, they gradually suspend the capacity of a model to learn new tasks. In this paper, we explore an alternative approach to the continual learning problem that aims to circumvent this downside. In particular, we ask the question: instead of forcing continual learning models to remember the past, can we modify the learning process from the start, such that the learned representations are less susceptible to forgetting? To this end, we explore multiple methods that could potentially encourage durable representations. We demonstrate empirically that the use of unsupervised auxiliary tasks achieves significant reduction in parameter re-optimization across tasks, and consequently reduces forgetting, without explicitly penalizing forgetting. Moreover, we propose a distance metric to track internal model dynamics across tasks, and use it to gain insight into the workings of our proposed approach, as well as other recently proposed methods.</p></div>\",\"PeriodicalId\":72089,\"journal\":{\"name\":\"Advances in computational intelligence\",\"volume\":\"2 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2021-12-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s43674-021-00022-8.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Advances in computational intelligence\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s43674-021-00022-8\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Advances in computational intelligence","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.1007/s43674-021-00022-8","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Toward durable representations for continual learning
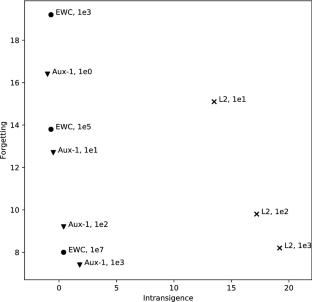
Continual learning models are known to suffer from catastrophic forgetting. Existing regularization methods to countering forgetting operate by penalizing large changes to learned parameters. A significant downside to these methods, however, is that, by effectively freezing model parameters, they gradually suspend the capacity of a model to learn new tasks. In this paper, we explore an alternative approach to the continual learning problem that aims to circumvent this downside. In particular, we ask the question: instead of forcing continual learning models to remember the past, can we modify the learning process from the start, such that the learned representations are less susceptible to forgetting? To this end, we explore multiple methods that could potentially encourage durable representations. We demonstrate empirically that the use of unsupervised auxiliary tasks achieves significant reduction in parameter re-optimization across tasks, and consequently reduces forgetting, without explicitly penalizing forgetting. Moreover, we propose a distance metric to track internal model dynamics across tasks, and use it to gain insight into the workings of our proposed approach, as well as other recently proposed methods.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


