Prabakaran N. , Kannadasan R. , Krishnamoorthy A. , Vijay Kakani
{"title":"一种基于关键字的模式匹配的双向LSTM脚本自动评估方法","authors":"Prabakaran N. , Kannadasan R. , Krishnamoorthy A. , Vijay Kakani","doi":"10.1016/j.nlp.2023.100033","DOIUrl":null,"url":null,"abstract":"<div><p>The evaluation process necessitates significant work in order to effectively and impartially assess the growing number of new subjects and interests in courses. This paper aims at auto-evaluating and setting scores for individuals similar to those provided by humans using deep learning models. This system is built purely to decipher the English characters and numbers from images, convert them into text format, and match the existing written scripts or custom keywords provided by the invigilators to check the answers. The Handwritten Text Recognition (HTR) model fervors and implements an algorithm that is capable of evaluating written scripts based on handwriting and comparing it with the custom keywords provided, whereas the existing models using Convolutional Neural networks (CNN) or Recurrent Neural networks (RNN) suffer from the Vanishing Gradient problem. The core objective of this model is to reduce manual paper checking using Bidirectional Long Short Term Memory (BiLSTM) and CRNN (Convolutional Recurrent Neural Networks). It has been implemented more than the models built on conventional approaches in aspects of performance, efficiency, and better text recognition. The inputs given to the model are in the form of custom keywords; the system processes them through HTR and image processing techniques of segmentation; and the output formats the percentage obtained by the student, word error rate, number of words misspelt, synonyms produced, and the effective outcome. The system has the capability to identify and highlight errors made by students. This feature is advantageous for both students and teachers, as it saves a significant amount of time. Even if the keywords used by students do not align perfectly, the advanced processing models employed by the system possess the intelligence to provide a reasonable number of marks.</p></div>","PeriodicalId":100944,"journal":{"name":"Natural Language Processing Journal","volume":"5 ","pages":"Article 100033"},"PeriodicalIF":0.0000,"publicationDate":"2023-09-15","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A Bidirectional LSTM approach for written script auto evaluation using keywords-based pattern matching\",\"authors\":\"Prabakaran N. , Kannadasan R. , Krishnamoorthy A. , Vijay Kakani\",\"doi\":\"10.1016/j.nlp.2023.100033\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>The evaluation process necessitates significant work in order to effectively and impartially assess the growing number of new subjects and interests in courses. This paper aims at auto-evaluating and setting scores for individuals similar to those provided by humans using deep learning models. This system is built purely to decipher the English characters and numbers from images, convert them into text format, and match the existing written scripts or custom keywords provided by the invigilators to check the answers. The Handwritten Text Recognition (HTR) model fervors and implements an algorithm that is capable of evaluating written scripts based on handwriting and comparing it with the custom keywords provided, whereas the existing models using Convolutional Neural networks (CNN) or Recurrent Neural networks (RNN) suffer from the Vanishing Gradient problem. The core objective of this model is to reduce manual paper checking using Bidirectional Long Short Term Memory (BiLSTM) and CRNN (Convolutional Recurrent Neural Networks). It has been implemented more than the models built on conventional approaches in aspects of performance, efficiency, and better text recognition. The inputs given to the model are in the form of custom keywords; the system processes them through HTR and image processing techniques of segmentation; and the output formats the percentage obtained by the student, word error rate, number of words misspelt, synonyms produced, and the effective outcome. The system has the capability to identify and highlight errors made by students. This feature is advantageous for both students and teachers, as it saves a significant amount of time. Even if the keywords used by students do not align perfectly, the advanced processing models employed by the system possess the intelligence to provide a reasonable number of marks.</p></div>\",\"PeriodicalId\":100944,\"journal\":{\"name\":\"Natural Language Processing Journal\",\"volume\":\"5 \",\"pages\":\"Article 100033\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-09-15\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Natural Language Processing Journal\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2949719123000304\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Natural Language Processing Journal","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2949719123000304","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
A Bidirectional LSTM approach for written script auto evaluation using keywords-based pattern matching
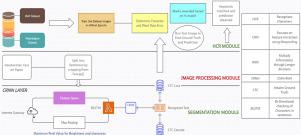
The evaluation process necessitates significant work in order to effectively and impartially assess the growing number of new subjects and interests in courses. This paper aims at auto-evaluating and setting scores for individuals similar to those provided by humans using deep learning models. This system is built purely to decipher the English characters and numbers from images, convert them into text format, and match the existing written scripts or custom keywords provided by the invigilators to check the answers. The Handwritten Text Recognition (HTR) model fervors and implements an algorithm that is capable of evaluating written scripts based on handwriting and comparing it with the custom keywords provided, whereas the existing models using Convolutional Neural networks (CNN) or Recurrent Neural networks (RNN) suffer from the Vanishing Gradient problem. The core objective of this model is to reduce manual paper checking using Bidirectional Long Short Term Memory (BiLSTM) and CRNN (Convolutional Recurrent Neural Networks). It has been implemented more than the models built on conventional approaches in aspects of performance, efficiency, and better text recognition. The inputs given to the model are in the form of custom keywords; the system processes them through HTR and image processing techniques of segmentation; and the output formats the percentage obtained by the student, word error rate, number of words misspelt, synonyms produced, and the effective outcome. The system has the capability to identify and highlight errors made by students. This feature is advantageous for both students and teachers, as it saves a significant amount of time. Even if the keywords used by students do not align perfectly, the advanced processing models employed by the system possess the intelligence to provide a reasonable number of marks.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


