{"title":"不同误差假设下随机漫步模型的贝叶斯分析","authors":"Praveen Kumar Tripathi, Manika Agarwal","doi":"10.1007/s40745-023-00465-5","DOIUrl":null,"url":null,"abstract":"<div><p>In this paper, the Bayesian analyses for the random walk models have been performed under the assumptions of normal distribution, log-normal distribution and the stochastic volatility model, for the error component, one by one. For the various parameters, in each model, some suitable choices of informative and non-informative priors have been made and the posterior distributions are calculated. For the first two choices of error distribution, the posterior samples are easily obtained by using the gamma generating routine in R software. For a random walk model, having stochastic volatility error, the Gibbs sampling with intermediate independent Metropolis–Hastings steps is employed to obtain the desired posterior samples. The whole procedure is numerically illustrated through a real data set of crude oil prices from April 2014 to March 2022. The models are, then, compared on the basis of their accuracies in forecasting the true values. Among the other choices, the random walk model with stochastic volatile errors outperformed for the data in hand.\n</p></div>","PeriodicalId":36280,"journal":{"name":"Annals of Data Science","volume":"11 5","pages":"1635 - 1652"},"PeriodicalIF":0.0000,"publicationDate":"2023-04-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"","citationCount":"0","resultStr":"{\"title\":\"A Bayes Analysis of Random Walk Model Under Different Error Assumptions\",\"authors\":\"Praveen Kumar Tripathi, Manika Agarwal\",\"doi\":\"10.1007/s40745-023-00465-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>In this paper, the Bayesian analyses for the random walk models have been performed under the assumptions of normal distribution, log-normal distribution and the stochastic volatility model, for the error component, one by one. For the various parameters, in each model, some suitable choices of informative and non-informative priors have been made and the posterior distributions are calculated. For the first two choices of error distribution, the posterior samples are easily obtained by using the gamma generating routine in R software. For a random walk model, having stochastic volatility error, the Gibbs sampling with intermediate independent Metropolis–Hastings steps is employed to obtain the desired posterior samples. The whole procedure is numerically illustrated through a real data set of crude oil prices from April 2014 to March 2022. The models are, then, compared on the basis of their accuracies in forecasting the true values. Among the other choices, the random walk model with stochastic volatile errors outperformed for the data in hand.\\n</p></div>\",\"PeriodicalId\":36280,\"journal\":{\"name\":\"Annals of Data Science\",\"volume\":\"11 5\",\"pages\":\"1635 - 1652\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2023-04-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Annals of Data Science\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s40745-023-00465-5\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Decision Sciences\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Annals of Data Science","FirstCategoryId":"1085","ListUrlMain":"https://link.springer.com/article/10.1007/s40745-023-00465-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Decision Sciences","Score":null,"Total":0}
A Bayes Analysis of Random Walk Model Under Different Error Assumptions
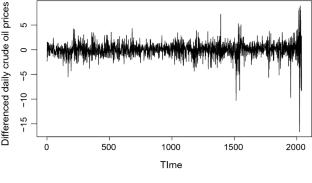
In this paper, the Bayesian analyses for the random walk models have been performed under the assumptions of normal distribution, log-normal distribution and the stochastic volatility model, for the error component, one by one. For the various parameters, in each model, some suitable choices of informative and non-informative priors have been made and the posterior distributions are calculated. For the first two choices of error distribution, the posterior samples are easily obtained by using the gamma generating routine in R software. For a random walk model, having stochastic volatility error, the Gibbs sampling with intermediate independent Metropolis–Hastings steps is employed to obtain the desired posterior samples. The whole procedure is numerically illustrated through a real data set of crude oil prices from April 2014 to March 2022. The models are, then, compared on the basis of their accuracies in forecasting the true values. Among the other choices, the random walk model with stochastic volatile errors outperformed for the data in hand.
期刊介绍:
Annals of Data Science (ADS) publishes cutting-edge research findings, experimental results and case studies of data science. Although Data Science is regarded as an interdisciplinary field of using mathematics, statistics, databases, data mining, high-performance computing, knowledge management and virtualization to discover knowledge from Big Data, it should have its own scientific contents, such as axioms, laws and rules, which are fundamentally important for experts in different fields to explore their own interests from Big Data. ADS encourages contributors to address such challenging problems at this exchange platform. At present, how to discover knowledge from heterogeneous data under Big Data environment needs to be addressed. ADS is a series of volumes edited by either the editorial office or guest editors. Guest editors will be responsible for call-for-papers and the review process for high-quality contributions in their volumes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


