Andries Smit, Herman A. Engelbrecht, Willie Brink, Arnu Pretorius
{"title":"将多智能体强化学习扩展到完整的11对11模拟机器人足球","authors":"Andries Smit, Herman A. Engelbrecht, Willie Brink, Arnu Pretorius","doi":"10.1007/s10458-023-09603-y","DOIUrl":null,"url":null,"abstract":"<div><p>Robotic football has long been seen as a grand challenge in artificial intelligence. Despite recent success of learned policies over heuristics and handcrafted rules in general, current teams in the simulated RoboCup football leagues, where autonomous agents compete against each other, still rely on handcrafted strategies with only a few using reinforcement learning directly. This limits a learning agent’s ability to find stronger high-level strategies for the full game. In this paper, we show that it is possible for agents to learn competent football strategies on a full 22 player setting using limited computation resources (one GPU and one CPU), from tabula rasa through self-play. To do this, we build a 2D football simulator with faster simulation times than the RoboCup simulator. We propose various improvements to the standard single-agent PPO training algorithm which help it scale to our multi-agent setting. These improvements include (1) using a policy and critic network with an attention mechanism that scales linearly in the number of agents, (2) sharing networks between agents which allow for faster throughput using batching, and (3) using Polyak averaged opponents, league opponents and freezing the opponent team when necessary. We show through experimental results that stable training in the full 22 player setting is possible. Agents trained in the 22 player setting learn to defeat a variety of handcrafted strategies, and also achieve a higher win rate compared to agents trained in the 4 player setting and evaluated in the full game.</p></div>","PeriodicalId":55586,"journal":{"name":"Autonomous Agents and Multi-Agent Systems","volume":"37 1","pages":""},"PeriodicalIF":2.0000,"publicationDate":"2023-03-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://link.springer.com/content/pdf/10.1007/s10458-023-09603-y.pdf","citationCount":"0","resultStr":"{\"title\":\"Scaling multi-agent reinforcement learning to full 11 versus 11 simulated robotic football\",\"authors\":\"Andries Smit, Herman A. Engelbrecht, Willie Brink, Arnu Pretorius\",\"doi\":\"10.1007/s10458-023-09603-y\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Robotic football has long been seen as a grand challenge in artificial intelligence. Despite recent success of learned policies over heuristics and handcrafted rules in general, current teams in the simulated RoboCup football leagues, where autonomous agents compete against each other, still rely on handcrafted strategies with only a few using reinforcement learning directly. This limits a learning agent’s ability to find stronger high-level strategies for the full game. In this paper, we show that it is possible for agents to learn competent football strategies on a full 22 player setting using limited computation resources (one GPU and one CPU), from tabula rasa through self-play. To do this, we build a 2D football simulator with faster simulation times than the RoboCup simulator. We propose various improvements to the standard single-agent PPO training algorithm which help it scale to our multi-agent setting. These improvements include (1) using a policy and critic network with an attention mechanism that scales linearly in the number of agents, (2) sharing networks between agents which allow for faster throughput using batching, and (3) using Polyak averaged opponents, league opponents and freezing the opponent team when necessary. We show through experimental results that stable training in the full 22 player setting is possible. Agents trained in the 22 player setting learn to defeat a variety of handcrafted strategies, and also achieve a higher win rate compared to agents trained in the 4 player setting and evaluated in the full game.</p></div>\",\"PeriodicalId\":55586,\"journal\":{\"name\":\"Autonomous Agents and Multi-Agent Systems\",\"volume\":\"37 1\",\"pages\":\"\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2023-03-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://link.springer.com/content/pdf/10.1007/s10458-023-09603-y.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Autonomous Agents and Multi-Agent Systems\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://link.springer.com/article/10.1007/s10458-023-09603-y\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Autonomous Agents and Multi-Agent Systems","FirstCategoryId":"94","ListUrlMain":"https://link.springer.com/article/10.1007/s10458-023-09603-y","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
Scaling multi-agent reinforcement learning to full 11 versus 11 simulated robotic football
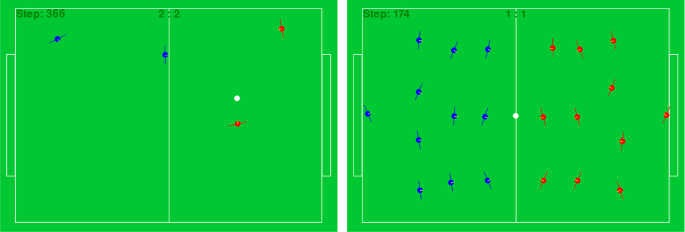
Robotic football has long been seen as a grand challenge in artificial intelligence. Despite recent success of learned policies over heuristics and handcrafted rules in general, current teams in the simulated RoboCup football leagues, where autonomous agents compete against each other, still rely on handcrafted strategies with only a few using reinforcement learning directly. This limits a learning agent’s ability to find stronger high-level strategies for the full game. In this paper, we show that it is possible for agents to learn competent football strategies on a full 22 player setting using limited computation resources (one GPU and one CPU), from tabula rasa through self-play. To do this, we build a 2D football simulator with faster simulation times than the RoboCup simulator. We propose various improvements to the standard single-agent PPO training algorithm which help it scale to our multi-agent setting. These improvements include (1) using a policy and critic network with an attention mechanism that scales linearly in the number of agents, (2) sharing networks between agents which allow for faster throughput using batching, and (3) using Polyak averaged opponents, league opponents and freezing the opponent team when necessary. We show through experimental results that stable training in the full 22 player setting is possible. Agents trained in the 22 player setting learn to defeat a variety of handcrafted strategies, and also achieve a higher win rate compared to agents trained in the 4 player setting and evaluated in the full game.
期刊介绍:
This is the official journal of the International Foundation for Autonomous Agents and Multi-Agent Systems. It provides a leading forum for disseminating significant original research results in the foundations, theory, development, analysis, and applications of autonomous agents and multi-agent systems. Coverage in Autonomous Agents and Multi-Agent Systems includes, but is not limited to:
Agent decision-making architectures and their evaluation, including: cognitive models; knowledge representation; logics for agency; ontological reasoning; planning (single and multi-agent); reasoning (single and multi-agent)
Cooperation and teamwork, including: distributed problem solving; human-robot/agent interaction; multi-user/multi-virtual-agent interaction; coalition formation; coordination
Agent communication languages, including: their semantics, pragmatics, and implementation; agent communication protocols and conversations; agent commitments; speech act theory
Ontologies for agent systems, agents and the semantic web, agents and semantic web services, Grid-based systems, and service-oriented computing
Agent societies and societal issues, including: artificial social systems; environments, organizations and institutions; ethical and legal issues; privacy, safety and security; trust, reliability and reputation
Agent-based system development, including: agent development techniques, tools and environments; agent programming languages; agent specification or validation languages
Agent-based simulation, including: emergent behavior; participatory simulation; simulation techniques, tools and environments; social simulation
Agreement technologies, including: argumentation; collective decision making; judgment aggregation and belief merging; negotiation; norms
Economic paradigms, including: auction and mechanism design; bargaining and negotiation; economically-motivated agents; game theory (cooperative and non-cooperative); social choice and voting
Learning agents, including: computational architectures for learning agents; evolution, adaptation; multi-agent learning.
Robotic agents, including: integrated perception, cognition, and action; cognitive robotics; robot planning (including action and motion planning); multi-robot systems.
Virtual agents, including: agents in games and virtual environments; companion and coaching agents; modeling personality, emotions; multimodal interaction; verbal and non-verbal expressiveness
Significant, novel applications of agent technology
Comprehensive reviews and authoritative tutorials of research and practice in agent systems
Comprehensive and authoritative reviews of books dealing with agents and multi-agent systems.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


