Talia B. Kimber , Maxime Gagnebin , Andrea Volkamer
{"title":"Maxsmi:利用SMILES增强和深度学习的置信度估计最大化分子特性预测性能","authors":"Talia B. Kimber , Maxime Gagnebin , Andrea Volkamer","doi":"10.1016/j.ailsci.2021.100014","DOIUrl":null,"url":null,"abstract":"<div><p>Accurate molecular property or activity prediction is one of the main goals in computer-aided drug design. Quantitative structure-activity relationship (QSAR) modeling and machine learning, more recently deep learning, have become an integral part of this process. Such algorithms require lots of data for training which, in the case of physico-chemical and bioactivity data sets, remains scarce. To address the lack of data, augmentation techniques are increasingly applied in deep learning. Here, we exploit that one compound can be represented by various SMILES strings as means of data augmentation and we explore several augmentation techniques. Convolutional and recurrent neural networks are trained on four data sets, including experimental solubility, lipophilicity, and bioactivity measurements. Moreover, the uncertainty of the models is assessed by applying augmentation on the test set. Our results show that data augmentation improves the accuracy independently of the deep learning model and of the size of the data. The best strategies lead to the Maxsmi models, the models that <strong>max</strong>imize the performance in <strong>SMI</strong>LES augmentation. Our findings show that the standard deviation of the per SMILES prediction correlates with the accuracy of the associated compound prediction. In addition, our systematic testing of different augmentation strategies provides an extensive guideline to SMILES augmentation. A prediction tool using the Maxsmi models for novel compounds on the aforementioned physico-chemical and bioactivity tasks is made available at <span>https://github.com/volkamerlab/maxsmi</span><svg><path></path></svg>.</p></div>","PeriodicalId":72304,"journal":{"name":"Artificial intelligence in the life sciences","volume":"1 ","pages":"Article 100014"},"PeriodicalIF":5.4000,"publicationDate":"2021-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.sciencedirect.com/science/article/pii/S2667318521000143/pdfft?md5=2b8d2b601acd14d7fc4fb788c10b0c44&pid=1-s2.0-S2667318521000143-main.pdf","citationCount":"11","resultStr":"{\"title\":\"Maxsmi: Maximizing molecular property prediction performance with confidence estimation using SMILES augmentation and deep learning\",\"authors\":\"Talia B. Kimber , Maxime Gagnebin , Andrea Volkamer\",\"doi\":\"10.1016/j.ailsci.2021.100014\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Accurate molecular property or activity prediction is one of the main goals in computer-aided drug design. Quantitative structure-activity relationship (QSAR) modeling and machine learning, more recently deep learning, have become an integral part of this process. Such algorithms require lots of data for training which, in the case of physico-chemical and bioactivity data sets, remains scarce. To address the lack of data, augmentation techniques are increasingly applied in deep learning. Here, we exploit that one compound can be represented by various SMILES strings as means of data augmentation and we explore several augmentation techniques. Convolutional and recurrent neural networks are trained on four data sets, including experimental solubility, lipophilicity, and bioactivity measurements. Moreover, the uncertainty of the models is assessed by applying augmentation on the test set. Our results show that data augmentation improves the accuracy independently of the deep learning model and of the size of the data. The best strategies lead to the Maxsmi models, the models that <strong>max</strong>imize the performance in <strong>SMI</strong>LES augmentation. Our findings show that the standard deviation of the per SMILES prediction correlates with the accuracy of the associated compound prediction. In addition, our systematic testing of different augmentation strategies provides an extensive guideline to SMILES augmentation. A prediction tool using the Maxsmi models for novel compounds on the aforementioned physico-chemical and bioactivity tasks is made available at <span>https://github.com/volkamerlab/maxsmi</span><svg><path></path></svg>.</p></div>\",\"PeriodicalId\":72304,\"journal\":{\"name\":\"Artificial intelligence in the life sciences\",\"volume\":\"1 \",\"pages\":\"Article 100014\"},\"PeriodicalIF\":5.4000,\"publicationDate\":\"2021-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.sciencedirect.com/science/article/pii/S2667318521000143/pdfft?md5=2b8d2b601acd14d7fc4fb788c10b0c44&pid=1-s2.0-S2667318521000143-main.pdf\",\"citationCount\":\"11\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Artificial intelligence in the life sciences\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2667318521000143\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Artificial intelligence in the life sciences","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2667318521000143","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Maxsmi: Maximizing molecular property prediction performance with confidence estimation using SMILES augmentation and deep learning
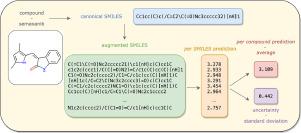
Accurate molecular property or activity prediction is one of the main goals in computer-aided drug design. Quantitative structure-activity relationship (QSAR) modeling and machine learning, more recently deep learning, have become an integral part of this process. Such algorithms require lots of data for training which, in the case of physico-chemical and bioactivity data sets, remains scarce. To address the lack of data, augmentation techniques are increasingly applied in deep learning. Here, we exploit that one compound can be represented by various SMILES strings as means of data augmentation and we explore several augmentation techniques. Convolutional and recurrent neural networks are trained on four data sets, including experimental solubility, lipophilicity, and bioactivity measurements. Moreover, the uncertainty of the models is assessed by applying augmentation on the test set. Our results show that data augmentation improves the accuracy independently of the deep learning model and of the size of the data. The best strategies lead to the Maxsmi models, the models that maximize the performance in SMILES augmentation. Our findings show that the standard deviation of the per SMILES prediction correlates with the accuracy of the associated compound prediction. In addition, our systematic testing of different augmentation strategies provides an extensive guideline to SMILES augmentation. A prediction tool using the Maxsmi models for novel compounds on the aforementioned physico-chemical and bioactivity tasks is made available at https://github.com/volkamerlab/maxsmi.
Artificial intelligence in the life sciencesPharmacology, Biochemistry, Genetics and Molecular Biology (General), Computer Science Applications, Health Informatics, Drug Discovery, Veterinary Science and Veterinary Medicine (General)

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


