{"title":"通过机器学习预测抗体-抗原结合:数据集的开发和方法的评估","authors":"Chao Ye, Wenxing Hu, Bruno Gaeta","doi":"10.2196/29404","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The mammalian immune system is able to generate antibodies against a huge variety of antigens, including bacteria, viruses, and toxins. The ultradeep DNA sequencing of rearranged immunoglobulin genes has considerable potential in furthering our understanding of the immune response, but it is limited by the lack of a high-throughput, sequence-based method for predicting the antigen(s) that a given immunoglobulin recognizes.</p><p><strong>Objective: </strong>As a step toward the prediction of antibody-antigen binding from sequence data alone, we aimed to compare a range of machine learning approaches that were applied to a collated data set of antibody-antigen pairs in order to predict antibody-antigen binding from sequence data.</p><p><strong>Methods: </strong>Data for training and testing were extracted from the Protein Data Bank and the Coronavirus Antibody Database, and additional antibody-antigen pair data were generated by using a molecular docking protocol. Several machine learning methods, including the weighted nearest neighbor method, the nearest neighbor method with the BLOSUM62 matrix, and the random forest method, were applied to the problem.</p><p><strong>Results: </strong>The final data set contained 1157 antibodies and 57 antigens that were combined in 5041 antibody-antigen pairs. The best performance for the prediction of interactions was obtained by using the nearest neighbor method with the BLOSUM62 matrix, which resulted in around 82% accuracy on the full data set. These results provide a useful frame of reference, as well as protocols and considerations, for machine learning and data set creation in the prediction of antibody-antigen binding.</p><p><strong>Conclusions: </strong>Several machine learning approaches were compared to predict antibody-antigen interaction from protein sequences. Both the data set (in CSV format) and the machine learning program (coded in Python) are freely available for download on GitHub.</p>","PeriodicalId":73552,"journal":{"name":"JMIR bioinformatics and biotechnology","volume":" ","pages":"e29404"},"PeriodicalIF":0.0000,"publicationDate":"2022-10-28","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11135222/pdf/","citationCount":"0","resultStr":"{\"title\":\"Prediction of Antibody-Antigen Binding via Machine Learning: Development of Data Sets and Evaluation of Methods.\",\"authors\":\"Chao Ye, Wenxing Hu, Bruno Gaeta\",\"doi\":\"10.2196/29404\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The mammalian immune system is able to generate antibodies against a huge variety of antigens, including bacteria, viruses, and toxins. The ultradeep DNA sequencing of rearranged immunoglobulin genes has considerable potential in furthering our understanding of the immune response, but it is limited by the lack of a high-throughput, sequence-based method for predicting the antigen(s) that a given immunoglobulin recognizes.</p><p><strong>Objective: </strong>As a step toward the prediction of antibody-antigen binding from sequence data alone, we aimed to compare a range of machine learning approaches that were applied to a collated data set of antibody-antigen pairs in order to predict antibody-antigen binding from sequence data.</p><p><strong>Methods: </strong>Data for training and testing were extracted from the Protein Data Bank and the Coronavirus Antibody Database, and additional antibody-antigen pair data were generated by using a molecular docking protocol. Several machine learning methods, including the weighted nearest neighbor method, the nearest neighbor method with the BLOSUM62 matrix, and the random forest method, were applied to the problem.</p><p><strong>Results: </strong>The final data set contained 1157 antibodies and 57 antigens that were combined in 5041 antibody-antigen pairs. The best performance for the prediction of interactions was obtained by using the nearest neighbor method with the BLOSUM62 matrix, which resulted in around 82% accuracy on the full data set. These results provide a useful frame of reference, as well as protocols and considerations, for machine learning and data set creation in the prediction of antibody-antigen binding.</p><p><strong>Conclusions: </strong>Several machine learning approaches were compared to predict antibody-antigen interaction from protein sequences. Both the data set (in CSV format) and the machine learning program (coded in Python) are freely available for download on GitHub.</p>\",\"PeriodicalId\":73552,\"journal\":{\"name\":\"JMIR bioinformatics and biotechnology\",\"volume\":\" \",\"pages\":\"e29404\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-10-28\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC11135222/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR bioinformatics and biotechnology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/29404\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR bioinformatics and biotechnology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/29404","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
Prediction of Antibody-Antigen Binding via Machine Learning: Development of Data Sets and Evaluation of Methods.
Background: The mammalian immune system is able to generate antibodies against a huge variety of antigens, including bacteria, viruses, and toxins. The ultradeep DNA sequencing of rearranged immunoglobulin genes has considerable potential in furthering our understanding of the immune response, but it is limited by the lack of a high-throughput, sequence-based method for predicting the antigen(s) that a given immunoglobulin recognizes.
Objective: As a step toward the prediction of antibody-antigen binding from sequence data alone, we aimed to compare a range of machine learning approaches that were applied to a collated data set of antibody-antigen pairs in order to predict antibody-antigen binding from sequence data.
Methods: Data for training and testing were extracted from the Protein Data Bank and the Coronavirus Antibody Database, and additional antibody-antigen pair data were generated by using a molecular docking protocol. Several machine learning methods, including the weighted nearest neighbor method, the nearest neighbor method with the BLOSUM62 matrix, and the random forest method, were applied to the problem.
Results: The final data set contained 1157 antibodies and 57 antigens that were combined in 5041 antibody-antigen pairs. The best performance for the prediction of interactions was obtained by using the nearest neighbor method with the BLOSUM62 matrix, which resulted in around 82% accuracy on the full data set. These results provide a useful frame of reference, as well as protocols and considerations, for machine learning and data set creation in the prediction of antibody-antigen binding.
Conclusions: Several machine learning approaches were compared to predict antibody-antigen interaction from protein sequences. Both the data set (in CSV format) and the machine learning program (coded in Python) are freely available for download on GitHub.
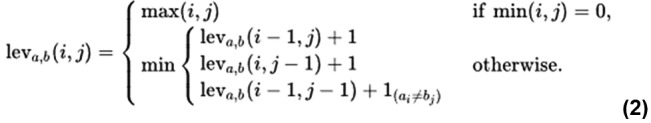
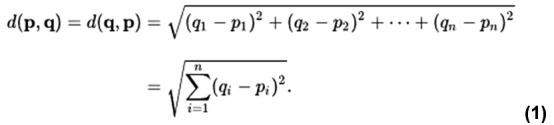

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


