Olivia Watkins, Sandy Huang, Julius Frost, Kush Bhatia, Eric Weiner, Pieter Abbeel, Trevor Darrell, Bryan Plummer, Kate Saenko, Anca Dragan
{"title":"解释机器人政策","authors":"Olivia Watkins, Sandy Huang, Julius Frost, Kush Bhatia, Eric Weiner, Pieter Abbeel, Trevor Darrell, Bryan Plummer, Kate Saenko, Anca Dragan","doi":"10.1002/ail2.52","DOIUrl":null,"url":null,"abstract":"<p>In order to interact with a robot or make wise decisions about where and how to deploy it in the real world, humans need to have an accurate mental model of how the robot acts in different situations. We propose to improve users' mental model of a robot by showing them examples of how the robot behaves in informative scenarios. We explore this in two settings. First, we show that when there are many possible environment states, users can more quickly understand the robot's policy if they are shown <i>critical states</i> where taking a particular action is important. Second, we show that when there is a distribution shift between training and test environment distributions, then it is more effective to show <i>exploratory states</i> that the robot does not visit naturally.</p>","PeriodicalId":72253,"journal":{"name":"Applied AI letters","volume":"2 4","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2021-11-13","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ail2.52","citationCount":"4","resultStr":"{\"title\":\"Explaining robot policies\",\"authors\":\"Olivia Watkins, Sandy Huang, Julius Frost, Kush Bhatia, Eric Weiner, Pieter Abbeel, Trevor Darrell, Bryan Plummer, Kate Saenko, Anca Dragan\",\"doi\":\"10.1002/ail2.52\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p>In order to interact with a robot or make wise decisions about where and how to deploy it in the real world, humans need to have an accurate mental model of how the robot acts in different situations. We propose to improve users' mental model of a robot by showing them examples of how the robot behaves in informative scenarios. We explore this in two settings. First, we show that when there are many possible environment states, users can more quickly understand the robot's policy if they are shown <i>critical states</i> where taking a particular action is important. Second, we show that when there is a distribution shift between training and test environment distributions, then it is more effective to show <i>exploratory states</i> that the robot does not visit naturally.</p>\",\"PeriodicalId\":72253,\"journal\":{\"name\":\"Applied AI letters\",\"volume\":\"2 4\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2021-11-13\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://onlinelibrary.wiley.com/doi/epdf/10.1002/ail2.52\",\"citationCount\":\"4\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Applied AI letters\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://onlinelibrary.wiley.com/doi/10.1002/ail2.52\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Applied AI letters","FirstCategoryId":"1085","ListUrlMain":"https://onlinelibrary.wiley.com/doi/10.1002/ail2.52","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
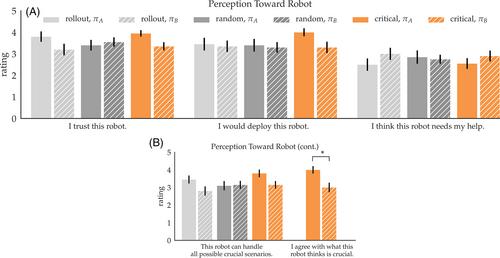
In order to interact with a robot or make wise decisions about where and how to deploy it in the real world, humans need to have an accurate mental model of how the robot acts in different situations. We propose to improve users' mental model of a robot by showing them examples of how the robot behaves in informative scenarios. We explore this in two settings. First, we show that when there are many possible environment states, users can more quickly understand the robot's policy if they are shown critical states where taking a particular action is important. Second, we show that when there is a distribution shift between training and test environment distributions, then it is more effective to show exploratory states that the robot does not visit naturally.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


