John Torcivia, Kawther Abdilleh, Fabian Seidl, Owais Shahzada, Rebecca Rodriguez, David Pot, Raja Mazumder
{"title":"全基因组变异数据集,用于18种不同癌症的丰富研究。","authors":"John Torcivia, Kawther Abdilleh, Fabian Seidl, Owais Shahzada, Rebecca Rodriguez, David Pot, Raja Mazumder","doi":"10.3390/onco2020009","DOIUrl":null,"url":null,"abstract":"<p><p>Whole genome sequencing (WGS) has helped to revolutionize biology, but the computational challenge remains for extracting valuable inferences from this information. Here, we present the cancer-associated variants from the Cancer Genome Atlas (TCGA) WGS dataset. This set of data will allow cancer researchers to further expand their analysis beyond the exomic regions of the genome to the entire genome. A total of 1342 WGS alignments available from the consortium were processed with VarScan2 and deposited to the NCI Cancer Cloud. The sample set covers 18 different cancers and reveals 157,313,519 pooled (non-unique) cancer-associated single-nucleotide variations (SNVs) across all samples. There was an average of 117,223 SNVs per sample, with a range from 1111 to 775,470 and a standard deviation of 163,273. The dataset was incorporated into BigQuery, which allows for fast access and cross-mapping, which will allow researchers to enrich their current studies with a plethora of newly available genomic data.</p>","PeriodicalId":74339,"journal":{"name":"Onco","volume":"2 2","pages":"129-144"},"PeriodicalIF":0.0000,"publicationDate":"2022-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10571071/pdf/","citationCount":"0","resultStr":"{\"title\":\"Whole Genome Variant Dataset for Enriching Studies across 18 Different Cancers.\",\"authors\":\"John Torcivia, Kawther Abdilleh, Fabian Seidl, Owais Shahzada, Rebecca Rodriguez, David Pot, Raja Mazumder\",\"doi\":\"10.3390/onco2020009\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Whole genome sequencing (WGS) has helped to revolutionize biology, but the computational challenge remains for extracting valuable inferences from this information. Here, we present the cancer-associated variants from the Cancer Genome Atlas (TCGA) WGS dataset. This set of data will allow cancer researchers to further expand their analysis beyond the exomic regions of the genome to the entire genome. A total of 1342 WGS alignments available from the consortium were processed with VarScan2 and deposited to the NCI Cancer Cloud. The sample set covers 18 different cancers and reveals 157,313,519 pooled (non-unique) cancer-associated single-nucleotide variations (SNVs) across all samples. There was an average of 117,223 SNVs per sample, with a range from 1111 to 775,470 and a standard deviation of 163,273. The dataset was incorporated into BigQuery, which allows for fast access and cross-mapping, which will allow researchers to enrich their current studies with a plethora of newly available genomic data.</p>\",\"PeriodicalId\":74339,\"journal\":{\"name\":\"Onco\",\"volume\":\"2 2\",\"pages\":\"129-144\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10571071/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Onco\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/onco2020009\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/6/17 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Onco","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/onco2020009","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/6/17 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Whole Genome Variant Dataset for Enriching Studies across 18 Different Cancers.
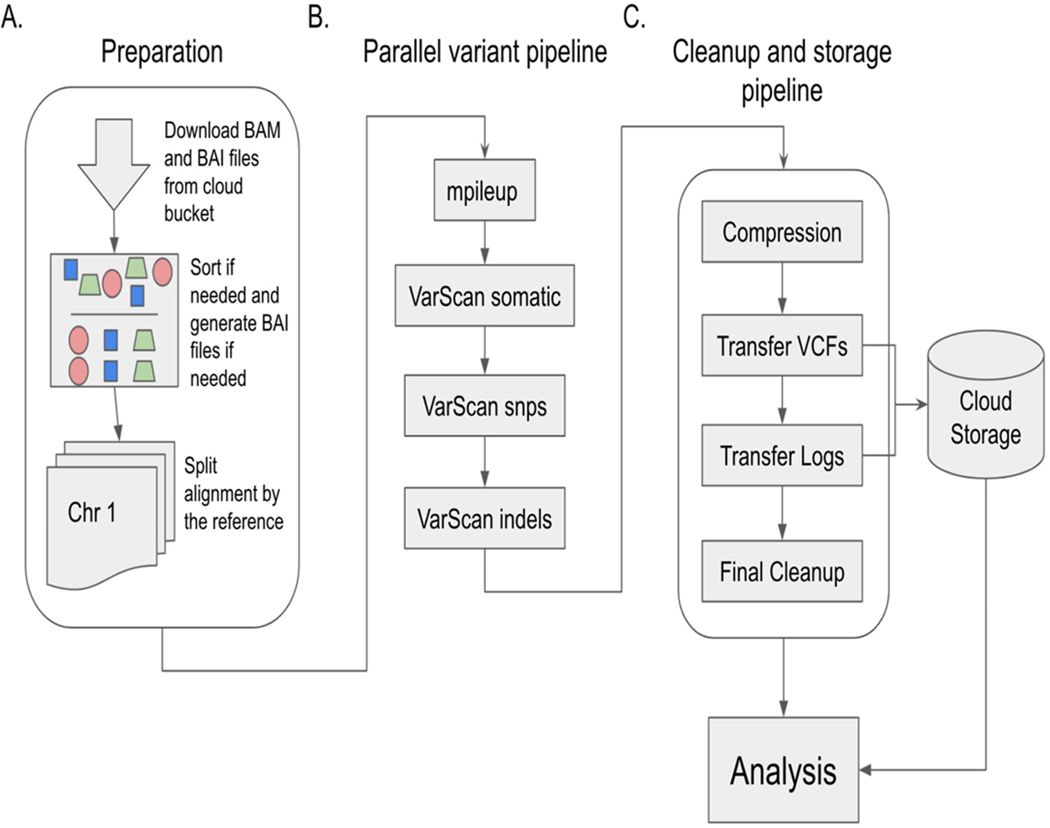
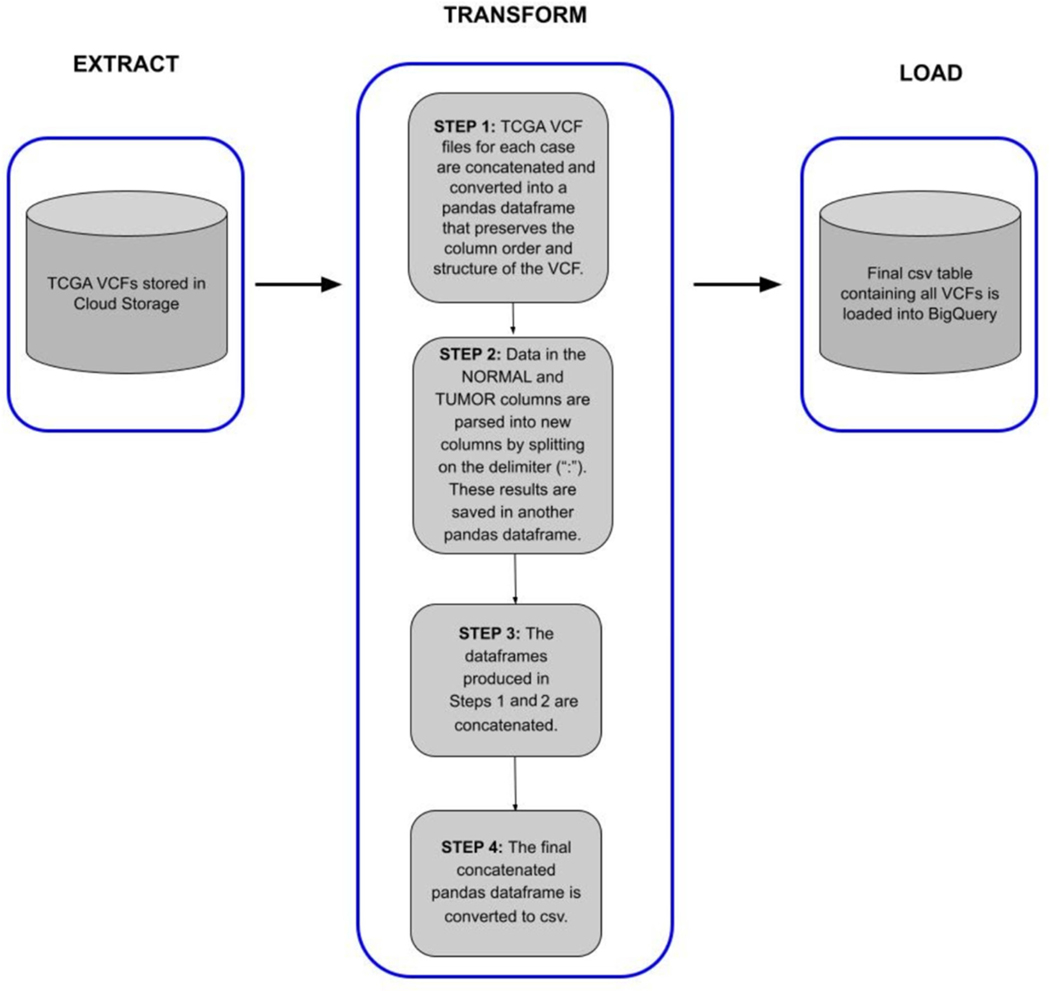
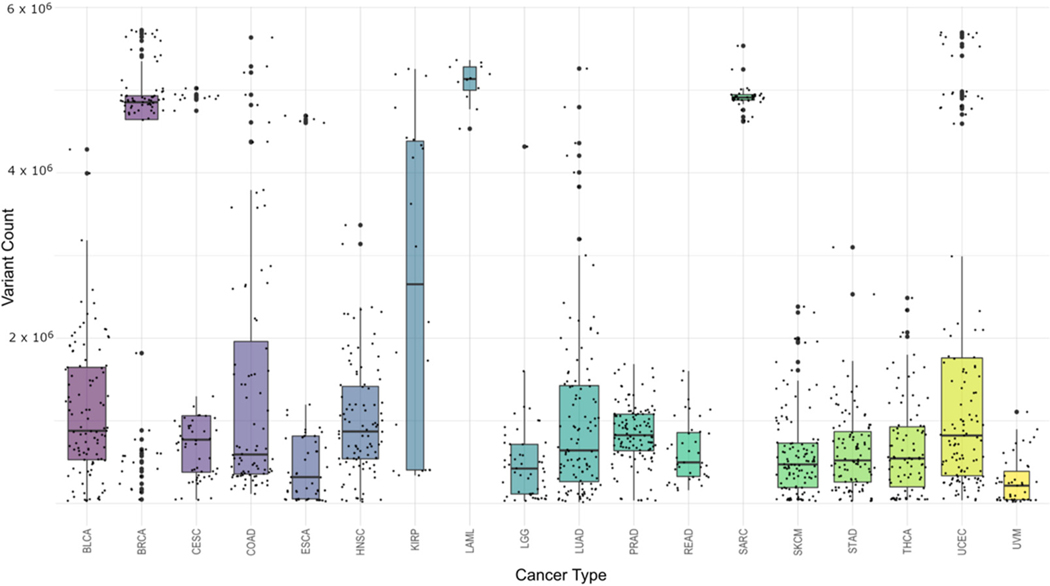
Whole genome sequencing (WGS) has helped to revolutionize biology, but the computational challenge remains for extracting valuable inferences from this information. Here, we present the cancer-associated variants from the Cancer Genome Atlas (TCGA) WGS dataset. This set of data will allow cancer researchers to further expand their analysis beyond the exomic regions of the genome to the entire genome. A total of 1342 WGS alignments available from the consortium were processed with VarScan2 and deposited to the NCI Cancer Cloud. The sample set covers 18 different cancers and reveals 157,313,519 pooled (non-unique) cancer-associated single-nucleotide variations (SNVs) across all samples. There was an average of 117,223 SNVs per sample, with a range from 1111 to 775,470 and a standard deviation of 163,273. The dataset was incorporated into BigQuery, which allows for fast access and cross-mapping, which will allow researchers to enrich their current studies with a plethora of newly available genomic data.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


