Richard Hr Roberts, Stephen R Ali, Hayley A Hutchings, Thomas D Dobbs, Iain S Whitaker
{"title":"ChatGPT和人类评估人员根据公认的报告标准评估医学文献的比较研究。","authors":"Richard Hr Roberts, Stephen R Ali, Hayley A Hutchings, Thomas D Dobbs, Iain S Whitaker","doi":"10.1136/bmjhci-2023-100830","DOIUrl":null,"url":null,"abstract":"Introduction Amid clinicians’ challenges in staying updated with medical research, artificial intelligence (AI) tools like the large language model (LLM) ChatGPT could automate appraisal of research quality, saving time and reducing bias. This study compares the proficiency of ChatGPT3 against human evaluation in scoring abstracts to determine its potential as a tool for evidence synthesis. Methods We compared ChatGPT’s scoring of implant dentistry abstracts with human evaluators using the Consolidated Standards of Reporting Trials for Abstracts reporting standards checklist, yielding an overall compliance score (OCS). Bland-Altman analysis assessed agreement between human and AI-generated OCS percentages. Additional error analysis included mean difference of OCS subscores, Welch’s t-test and Pearson’s correlation coefficient. Results Bland-Altman analysis showed a mean difference of 4.92% (95% CI 0.62%, 0.37%) in OCS between human evaluation and ChatGPT. Error analysis displayed small mean differences in most domains, with the highest in ‘conclusion’ (0.764 (95% CI 0.186, 0.280)) and the lowest in ‘blinding’ (0.034 (95% CI 0.818, 0.895)). The strongest correlations between were in ‘harms’ (r=0.32, p<0.001) and ‘trial registration’ (r=0.34, p=0.002), whereas the weakest were in ‘intervention’ (r=0.02, p<0.001) and ‘objective’ (r=0.06, p<0.001). Conclusion LLMs like ChatGPT can help automate appraisal of medical literature, aiding in the identification of accurately reported research. Possible applications of ChatGPT include integration within medical databases for abstract evaluation. Current limitations include the token limit, restricting its usage to abstracts. As AI technology advances, future versions like GPT4 could offer more reliable, comprehensive evaluations, enhancing the identification of high-quality research and potentially improving patient outcomes.","PeriodicalId":9050,"journal":{"name":"BMJ Health & Care Informatics","volume":"30 1","pages":""},"PeriodicalIF":4.1000,"publicationDate":"2023-10-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10583079/pdf/","citationCount":"0","resultStr":"{\"title\":\"Comparative study of ChatGPT and human evaluators on the assessment of medical literature according to recognised reporting standards.\",\"authors\":\"Richard Hr Roberts, Stephen R Ali, Hayley A Hutchings, Thomas D Dobbs, Iain S Whitaker\",\"doi\":\"10.1136/bmjhci-2023-100830\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"Introduction Amid clinicians’ challenges in staying updated with medical research, artificial intelligence (AI) tools like the large language model (LLM) ChatGPT could automate appraisal of research quality, saving time and reducing bias. This study compares the proficiency of ChatGPT3 against human evaluation in scoring abstracts to determine its potential as a tool for evidence synthesis. Methods We compared ChatGPT’s scoring of implant dentistry abstracts with human evaluators using the Consolidated Standards of Reporting Trials for Abstracts reporting standards checklist, yielding an overall compliance score (OCS). Bland-Altman analysis assessed agreement between human and AI-generated OCS percentages. Additional error analysis included mean difference of OCS subscores, Welch’s t-test and Pearson’s correlation coefficient. Results Bland-Altman analysis showed a mean difference of 4.92% (95% CI 0.62%, 0.37%) in OCS between human evaluation and ChatGPT. Error analysis displayed small mean differences in most domains, with the highest in ‘conclusion’ (0.764 (95% CI 0.186, 0.280)) and the lowest in ‘blinding’ (0.034 (95% CI 0.818, 0.895)). The strongest correlations between were in ‘harms’ (r=0.32, p<0.001) and ‘trial registration’ (r=0.34, p=0.002), whereas the weakest were in ‘intervention’ (r=0.02, p<0.001) and ‘objective’ (r=0.06, p<0.001). Conclusion LLMs like ChatGPT can help automate appraisal of medical literature, aiding in the identification of accurately reported research. Possible applications of ChatGPT include integration within medical databases for abstract evaluation. Current limitations include the token limit, restricting its usage to abstracts. As AI technology advances, future versions like GPT4 could offer more reliable, comprehensive evaluations, enhancing the identification of high-quality research and potentially improving patient outcomes.\",\"PeriodicalId\":9050,\"journal\":{\"name\":\"BMJ Health & Care Informatics\",\"volume\":\"30 1\",\"pages\":\"\"},\"PeriodicalIF\":4.1000,\"publicationDate\":\"2023-10-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10583079/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMJ Health & Care Informatics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1136/bmjhci-2023-100830\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMJ Health & Care Informatics","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1136/bmjhci-2023-100830","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Comparative study of ChatGPT and human evaluators on the assessment of medical literature according to recognised reporting standards.
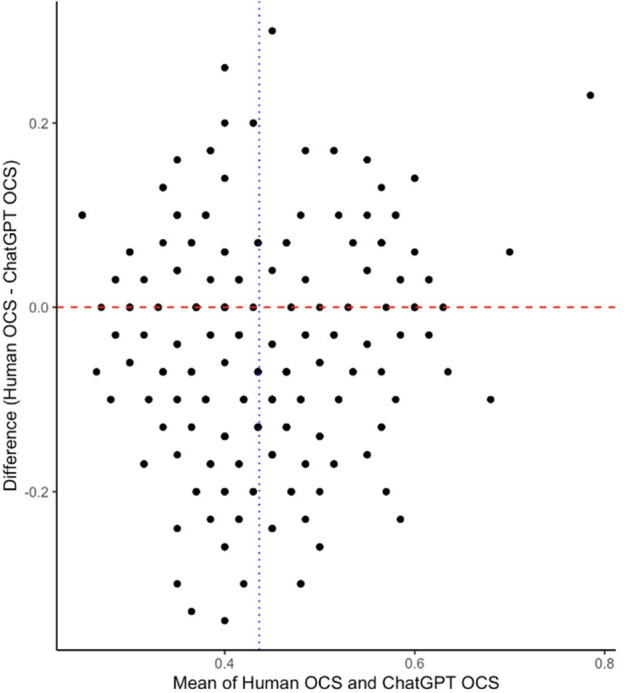
Introduction Amid clinicians’ challenges in staying updated with medical research, artificial intelligence (AI) tools like the large language model (LLM) ChatGPT could automate appraisal of research quality, saving time and reducing bias. This study compares the proficiency of ChatGPT3 against human evaluation in scoring abstracts to determine its potential as a tool for evidence synthesis. Methods We compared ChatGPT’s scoring of implant dentistry abstracts with human evaluators using the Consolidated Standards of Reporting Trials for Abstracts reporting standards checklist, yielding an overall compliance score (OCS). Bland-Altman analysis assessed agreement between human and AI-generated OCS percentages. Additional error analysis included mean difference of OCS subscores, Welch’s t-test and Pearson’s correlation coefficient. Results Bland-Altman analysis showed a mean difference of 4.92% (95% CI 0.62%, 0.37%) in OCS between human evaluation and ChatGPT. Error analysis displayed small mean differences in most domains, with the highest in ‘conclusion’ (0.764 (95% CI 0.186, 0.280)) and the lowest in ‘blinding’ (0.034 (95% CI 0.818, 0.895)). The strongest correlations between were in ‘harms’ (r=0.32, p<0.001) and ‘trial registration’ (r=0.34, p=0.002), whereas the weakest were in ‘intervention’ (r=0.02, p<0.001) and ‘objective’ (r=0.06, p<0.001). Conclusion LLMs like ChatGPT can help automate appraisal of medical literature, aiding in the identification of accurately reported research. Possible applications of ChatGPT include integration within medical databases for abstract evaluation. Current limitations include the token limit, restricting its usage to abstracts. As AI technology advances, future versions like GPT4 could offer more reliable, comprehensive evaluations, enhancing the identification of high-quality research and potentially improving patient outcomes.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


