{"title":"利用声音作为生物标记的帕金森病分类机器学习智能系统","authors":"Ilias Tougui, Abdelilah Jilbab, Jamal El Mhamdi","doi":"10.4258/hir.2022.28.3.210","DOIUrl":null,"url":null,"abstract":"<p><strong>Objectives: </strong>This study presents PD Predict, a machine learning system for Parkinson disease classification using voice as a biomarker.</p><p><strong>Methods: </strong>We first created an original set of recordings from the mPower study, and then extracted several audio features, such as mel-frequency cepstral coefficient (MFCC) components and other classical speech features, using a windowing procedure. The generated dataset was then divided into training and holdout sets. The training set was used to train two machine learning pipelines, and their performance was estimated using a nested subject-wise cross-validation approach. The holdout set was used to assess the generalizability of the pipelines for unseen data. The final pipelines were implemented in PD Predict and accessed through a prediction endpoint developed using the Django REST Framework. PD Predict is a two-component system: a desktop application that records audio recordings, extracts audio features, and makes predictions; and a server-side web application that implements the machine learning pipelines and processes incoming requests with the extracted audio features to make predictions. Our system is deployed and accessible via the following link: https://pdpredict.herokuapp.com/.</p><p><strong>Results: </strong>Both machine learning pipelines showed moderate performance, between 65% and 75% using the nested subject-wise cross-validation approach. Furthermore, they generalized well to unseen data and they did not overfit the training set.</p><p><strong>Conclusions: </strong>The architecture of PD Predict is clear, and the performance of the implemented machine learning pipelines is promising and confirms the usability of smartphone microphones for capturing digital biomarkers of disease.</p>","PeriodicalId":12947,"journal":{"name":"Healthcare Informatics Research","volume":null,"pages":null},"PeriodicalIF":2.3000,"publicationDate":"2022-07-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/0d/f8/hir-2022-28-3-210.PMC9388925.pdf","citationCount":"0","resultStr":"{\"title\":\"Machine Learning Smart System for Parkinson Disease Classification Using the Voice as a Biomarker.\",\"authors\":\"Ilias Tougui, Abdelilah Jilbab, Jamal El Mhamdi\",\"doi\":\"10.4258/hir.2022.28.3.210\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Objectives: </strong>This study presents PD Predict, a machine learning system for Parkinson disease classification using voice as a biomarker.</p><p><strong>Methods: </strong>We first created an original set of recordings from the mPower study, and then extracted several audio features, such as mel-frequency cepstral coefficient (MFCC) components and other classical speech features, using a windowing procedure. The generated dataset was then divided into training and holdout sets. The training set was used to train two machine learning pipelines, and their performance was estimated using a nested subject-wise cross-validation approach. The holdout set was used to assess the generalizability of the pipelines for unseen data. The final pipelines were implemented in PD Predict and accessed through a prediction endpoint developed using the Django REST Framework. PD Predict is a two-component system: a desktop application that records audio recordings, extracts audio features, and makes predictions; and a server-side web application that implements the machine learning pipelines and processes incoming requests with the extracted audio features to make predictions. Our system is deployed and accessible via the following link: https://pdpredict.herokuapp.com/.</p><p><strong>Results: </strong>Both machine learning pipelines showed moderate performance, between 65% and 75% using the nested subject-wise cross-validation approach. Furthermore, they generalized well to unseen data and they did not overfit the training set.</p><p><strong>Conclusions: </strong>The architecture of PD Predict is clear, and the performance of the implemented machine learning pipelines is promising and confirms the usability of smartphone microphones for capturing digital biomarkers of disease.</p>\",\"PeriodicalId\":12947,\"journal\":{\"name\":\"Healthcare Informatics Research\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":2.3000,\"publicationDate\":\"2022-07-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/0d/f8/hir-2022-28-3-210.PMC9388925.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Healthcare Informatics Research\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4258/hir.2022.28.3.210\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/7/31 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"MEDICAL INFORMATICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Healthcare Informatics Research","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4258/hir.2022.28.3.210","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/7/31 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"MEDICAL INFORMATICS","Score":null,"Total":0}
Machine Learning Smart System for Parkinson Disease Classification Using the Voice as a Biomarker.
Objectives: This study presents PD Predict, a machine learning system for Parkinson disease classification using voice as a biomarker.
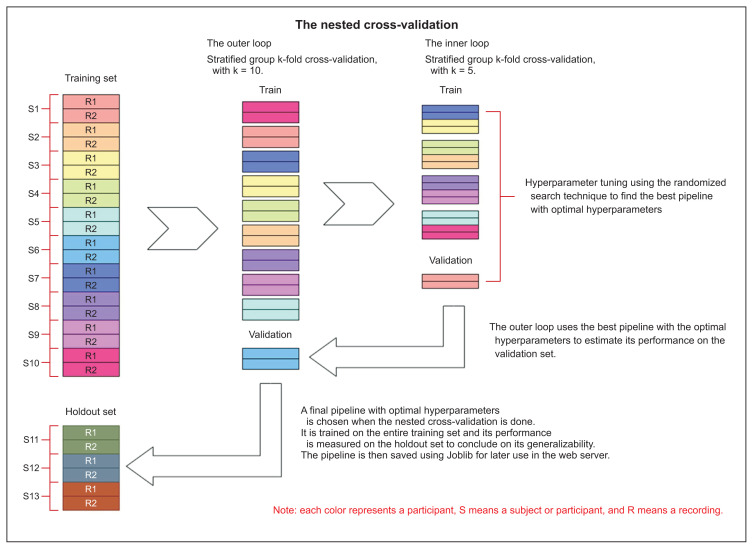
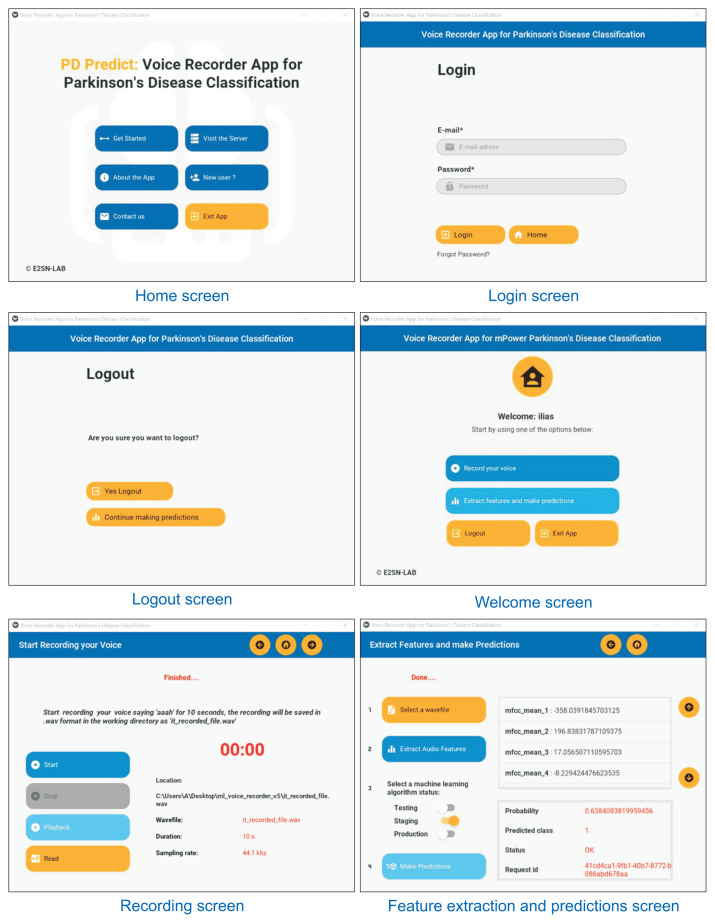
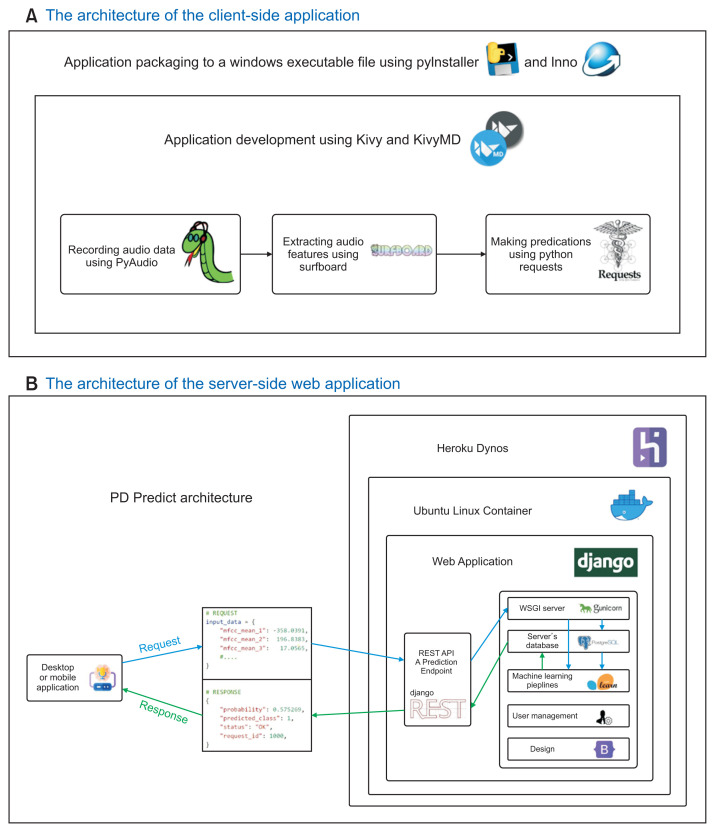
Methods: We first created an original set of recordings from the mPower study, and then extracted several audio features, such as mel-frequency cepstral coefficient (MFCC) components and other classical speech features, using a windowing procedure. The generated dataset was then divided into training and holdout sets. The training set was used to train two machine learning pipelines, and their performance was estimated using a nested subject-wise cross-validation approach. The holdout set was used to assess the generalizability of the pipelines for unseen data. The final pipelines were implemented in PD Predict and accessed through a prediction endpoint developed using the Django REST Framework. PD Predict is a two-component system: a desktop application that records audio recordings, extracts audio features, and makes predictions; and a server-side web application that implements the machine learning pipelines and processes incoming requests with the extracted audio features to make predictions. Our system is deployed and accessible via the following link: https://pdpredict.herokuapp.com/.
Results: Both machine learning pipelines showed moderate performance, between 65% and 75% using the nested subject-wise cross-validation approach. Furthermore, they generalized well to unseen data and they did not overfit the training set.
Conclusions: The architecture of PD Predict is clear, and the performance of the implemented machine learning pipelines is promising and confirms the usability of smartphone microphones for capturing digital biomarkers of disease.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


