{"title":"针对多元依赖性的多尺度费雪独立性检验。","authors":"S Gorsky, L Ma","doi":"10.1093/biomet/asac013","DOIUrl":null,"url":null,"abstract":"<p><p>Identifying dependency in multivariate data is a common inference task that arises in numerous applications. However, existing nonparametric independence tests typically require computation that scales at least quadratically with the sample size, making it difficult to apply them in the presence of massive sample sizes. Moreover, resampling is usually necessary to evaluate the statistical significance of the resulting test statistics at finite sample sizes, further worsening the computational burden. We introduce a scalable, resampling-free approach to testing the independence between two random vectors by breaking down the task into simple univariate tests of independence on a collection of 2 × 2 contingency tables constructed through sequential coarse-to-fine discretization of the sample space, transforming the inference task into a multiple testing problem that can be completed with almost linear complexity with respect to the sample size. To address increasing dimensionality, we introduce a coarse-to-fine sequential adaptive procedure that exploits the spatial features of dependency structures. We derive a finite-sample theory that guarantees the inferential validity of our adaptive procedure at any given sample size. We show that our approach can achieve strong control of the level of the testing procedure at any sample size without resampling or asymptotic approximation and establish its large-sample consistency. We demonstrate through an extensive simulation study its substantial computational advantage in comparison to existing approaches while achieving robust statistical power under various dependency scenarios, and illustrate how its divide-and-conquer nature can be exploited to not just test independence, but to learn the nature of the underlying dependency. Finally, we demonstrate the use of our method through analysing a dataset from a flow cytometry experiment.</p>","PeriodicalId":9001,"journal":{"name":"Biometrika","volume":null,"pages":null},"PeriodicalIF":2.4000,"publicationDate":"2022-09-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9648765/pdf/","citationCount":"0","resultStr":"{\"title\":\"Multi-scale Fisher's independence test for multivariate dependence.\",\"authors\":\"S Gorsky, L Ma\",\"doi\":\"10.1093/biomet/asac013\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Identifying dependency in multivariate data is a common inference task that arises in numerous applications. However, existing nonparametric independence tests typically require computation that scales at least quadratically with the sample size, making it difficult to apply them in the presence of massive sample sizes. Moreover, resampling is usually necessary to evaluate the statistical significance of the resulting test statistics at finite sample sizes, further worsening the computational burden. We introduce a scalable, resampling-free approach to testing the independence between two random vectors by breaking down the task into simple univariate tests of independence on a collection of 2 × 2 contingency tables constructed through sequential coarse-to-fine discretization of the sample space, transforming the inference task into a multiple testing problem that can be completed with almost linear complexity with respect to the sample size. To address increasing dimensionality, we introduce a coarse-to-fine sequential adaptive procedure that exploits the spatial features of dependency structures. We derive a finite-sample theory that guarantees the inferential validity of our adaptive procedure at any given sample size. We show that our approach can achieve strong control of the level of the testing procedure at any sample size without resampling or asymptotic approximation and establish its large-sample consistency. We demonstrate through an extensive simulation study its substantial computational advantage in comparison to existing approaches while achieving robust statistical power under various dependency scenarios, and illustrate how its divide-and-conquer nature can be exploited to not just test independence, but to learn the nature of the underlying dependency. Finally, we demonstrate the use of our method through analysing a dataset from a flow cytometry experiment.</p>\",\"PeriodicalId\":9001,\"journal\":{\"name\":\"Biometrika\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":2.4000,\"publicationDate\":\"2022-09-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9648765/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biometrika\",\"FirstCategoryId\":\"100\",\"ListUrlMain\":\"https://doi.org/10.1093/biomet/asac013\",\"RegionNum\":2,\"RegionCategory\":\"数学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/2/21 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biometrika","FirstCategoryId":"100","ListUrlMain":"https://doi.org/10.1093/biomet/asac013","RegionNum":2,"RegionCategory":"数学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/2/21 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"BIOLOGY","Score":null,"Total":0}
Multi-scale Fisher's independence test for multivariate dependence.
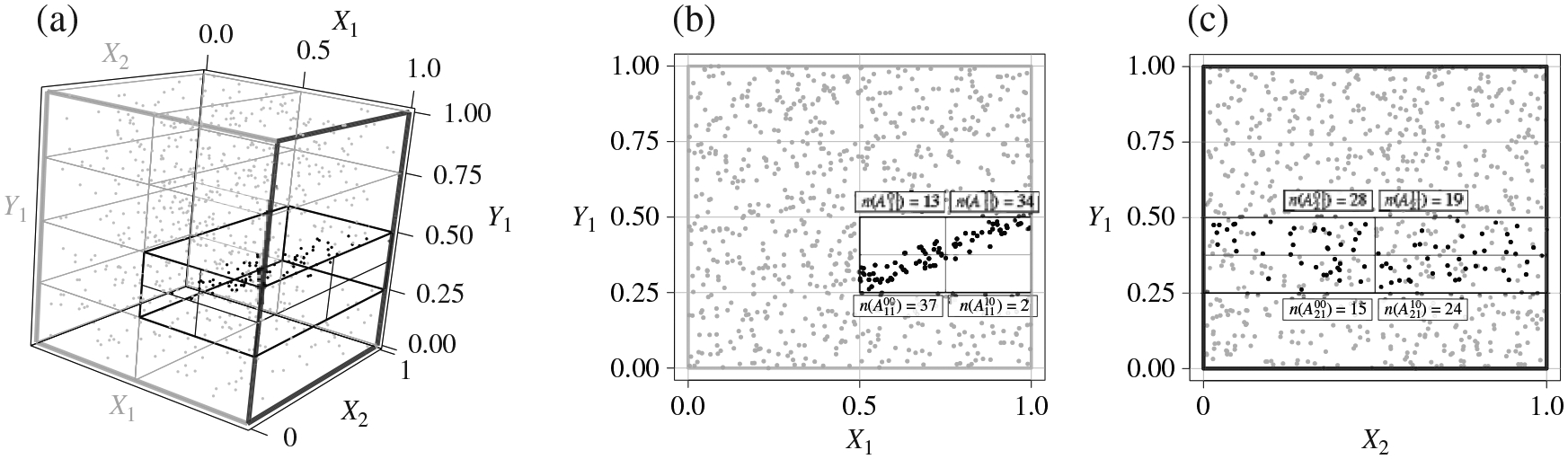
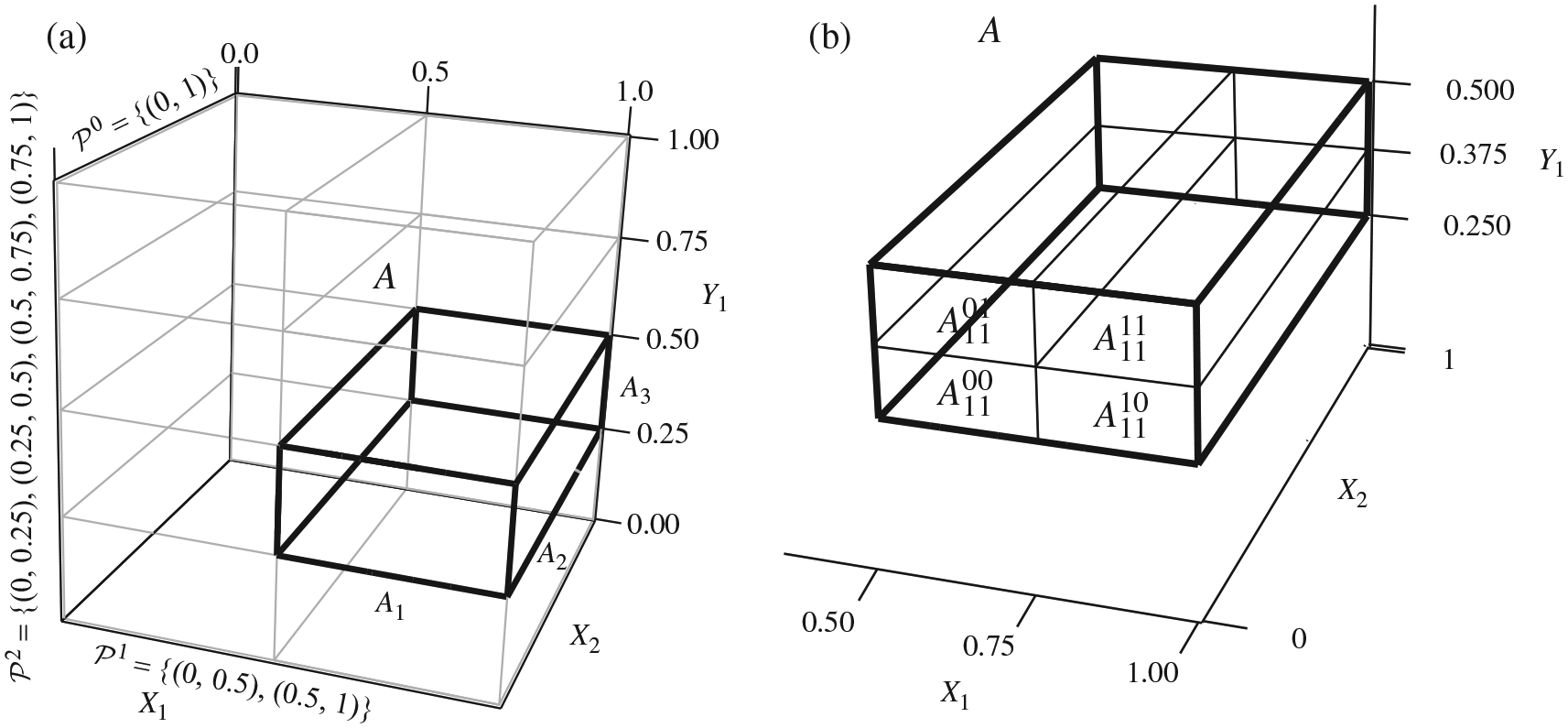
Identifying dependency in multivariate data is a common inference task that arises in numerous applications. However, existing nonparametric independence tests typically require computation that scales at least quadratically with the sample size, making it difficult to apply them in the presence of massive sample sizes. Moreover, resampling is usually necessary to evaluate the statistical significance of the resulting test statistics at finite sample sizes, further worsening the computational burden. We introduce a scalable, resampling-free approach to testing the independence between two random vectors by breaking down the task into simple univariate tests of independence on a collection of 2 × 2 contingency tables constructed through sequential coarse-to-fine discretization of the sample space, transforming the inference task into a multiple testing problem that can be completed with almost linear complexity with respect to the sample size. To address increasing dimensionality, we introduce a coarse-to-fine sequential adaptive procedure that exploits the spatial features of dependency structures. We derive a finite-sample theory that guarantees the inferential validity of our adaptive procedure at any given sample size. We show that our approach can achieve strong control of the level of the testing procedure at any sample size without resampling or asymptotic approximation and establish its large-sample consistency. We demonstrate through an extensive simulation study its substantial computational advantage in comparison to existing approaches while achieving robust statistical power under various dependency scenarios, and illustrate how its divide-and-conquer nature can be exploited to not just test independence, but to learn the nature of the underlying dependency. Finally, we demonstrate the use of our method through analysing a dataset from a flow cytometry experiment.
期刊介绍:
Biometrika is primarily a journal of statistics in which emphasis is placed on papers containing original theoretical contributions of direct or potential value in applications. From time to time, papers in bordering fields are also published.
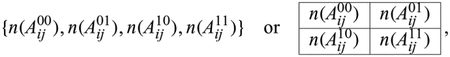

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


