Neal D Goldstein, Deborah Kahal, Karla Testa, Ed J Gracely, Igor Burstyn
{"title":"电子健康记录研究中的数据质量:通过诊断代码对不完全确定的健康结果进行验证和定量偏倚分析的方法。","authors":"Neal D Goldstein, Deborah Kahal, Karla Testa, Ed J Gracely, Igor Burstyn","doi":"10.1162/99608f92.cbe67e91","DOIUrl":null,"url":null,"abstract":"<p><p>It is incumbent upon all researchers who use the electronic health record (EHR), including data scientists, to understand the quality of such data. EHR data may be subject to measurement error or misclassification that have the potential to bias results, unless one applies the available computational techniques specifically created for this problem. In this article, we begin with a discussion of data-quality issues in the EHR focusing on health outcomes. We review the concepts of sensitivity, specificity, positive and negative predictive values, and demonstrate how the imperfect classification of a dichotomous outcome variable can bias an analysis, both in terms of prevalence of the outcome, and relative risk of the outcome under one treatment regime (aka exposure) compared to another. This is then followed by a description of a generalizable approach to probabilistic (quantitative) bias analysis using a combination of regression estimation of the parameters that relate the true and observed data and application of these estimates to adjust the prevalence and relative risk that may have existed if there was no misclassification. We describe bias analysis that accounts for both random and systematic errors and highlight its limitations. We then motivate a case study with the goal of validating the accuracy of a health outcome, chronic infection with hepatitis C virus, derived from a diagnostic code in the EHR. Finally, we demonstrate our approaches on the case study and conclude by summarizing the literature on outcome misclassification and quantitative bias analysis.</p>","PeriodicalId":73195,"journal":{"name":"Harvard data science review","volume":" ","pages":""},"PeriodicalIF":2.5000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9624477/pdf/","citationCount":"5","resultStr":"{\"title\":\"Data Quality in Electronic Health Record Research: An Approach for Validation and Quantitative Bias Analysis for Imperfectly Ascertained Health Outcomes Via Diagnostic Codes.\",\"authors\":\"Neal D Goldstein, Deborah Kahal, Karla Testa, Ed J Gracely, Igor Burstyn\",\"doi\":\"10.1162/99608f92.cbe67e91\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>It is incumbent upon all researchers who use the electronic health record (EHR), including data scientists, to understand the quality of such data. EHR data may be subject to measurement error or misclassification that have the potential to bias results, unless one applies the available computational techniques specifically created for this problem. In this article, we begin with a discussion of data-quality issues in the EHR focusing on health outcomes. We review the concepts of sensitivity, specificity, positive and negative predictive values, and demonstrate how the imperfect classification of a dichotomous outcome variable can bias an analysis, both in terms of prevalence of the outcome, and relative risk of the outcome under one treatment regime (aka exposure) compared to another. This is then followed by a description of a generalizable approach to probabilistic (quantitative) bias analysis using a combination of regression estimation of the parameters that relate the true and observed data and application of these estimates to adjust the prevalence and relative risk that may have existed if there was no misclassification. We describe bias analysis that accounts for both random and systematic errors and highlight its limitations. We then motivate a case study with the goal of validating the accuracy of a health outcome, chronic infection with hepatitis C virus, derived from a diagnostic code in the EHR. Finally, we demonstrate our approaches on the case study and conclude by summarizing the literature on outcome misclassification and quantitative bias analysis.</p>\",\"PeriodicalId\":73195,\"journal\":{\"name\":\"Harvard data science review\",\"volume\":\" \",\"pages\":\"\"},\"PeriodicalIF\":2.5000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9624477/pdf/\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Harvard data science review\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1162/99608f92.cbe67e91\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/4/28 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Harvard data science review","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1162/99608f92.cbe67e91","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/4/28 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Data Quality in Electronic Health Record Research: An Approach for Validation and Quantitative Bias Analysis for Imperfectly Ascertained Health Outcomes Via Diagnostic Codes.
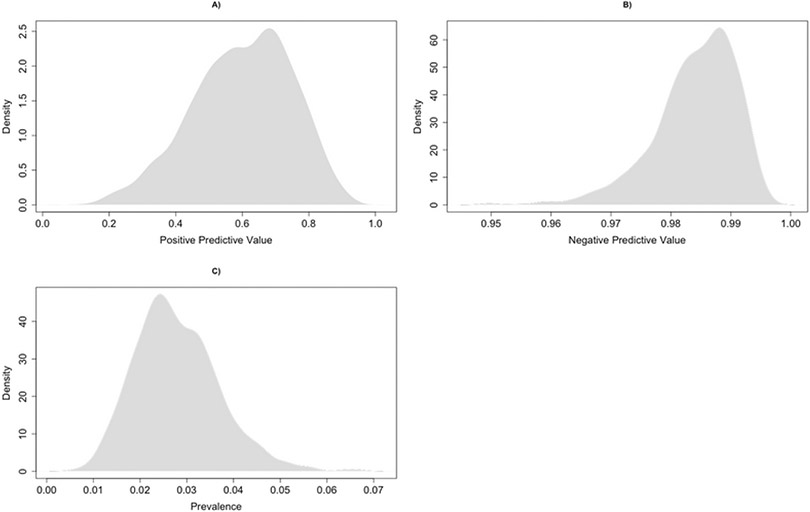
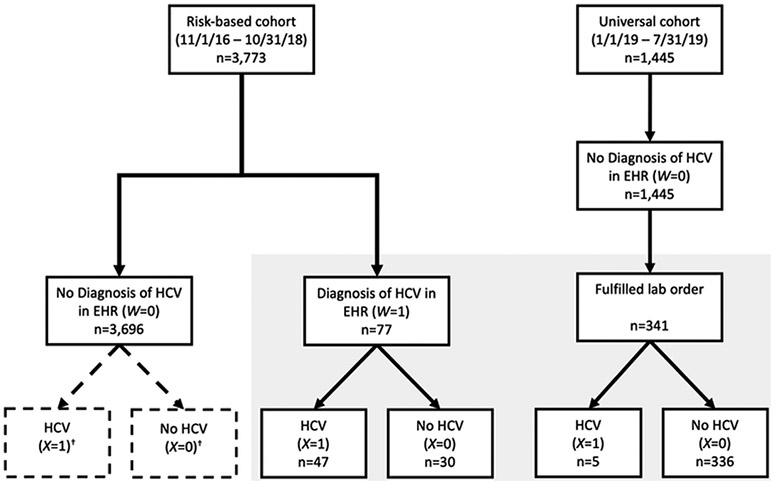
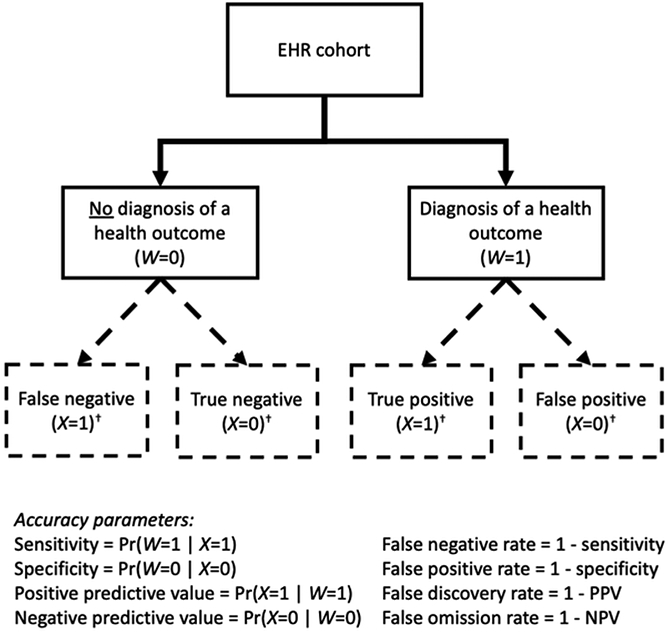
It is incumbent upon all researchers who use the electronic health record (EHR), including data scientists, to understand the quality of such data. EHR data may be subject to measurement error or misclassification that have the potential to bias results, unless one applies the available computational techniques specifically created for this problem. In this article, we begin with a discussion of data-quality issues in the EHR focusing on health outcomes. We review the concepts of sensitivity, specificity, positive and negative predictive values, and demonstrate how the imperfect classification of a dichotomous outcome variable can bias an analysis, both in terms of prevalence of the outcome, and relative risk of the outcome under one treatment regime (aka exposure) compared to another. This is then followed by a description of a generalizable approach to probabilistic (quantitative) bias analysis using a combination of regression estimation of the parameters that relate the true and observed data and application of these estimates to adjust the prevalence and relative risk that may have existed if there was no misclassification. We describe bias analysis that accounts for both random and systematic errors and highlight its limitations. We then motivate a case study with the goal of validating the accuracy of a health outcome, chronic infection with hepatitis C virus, derived from a diagnostic code in the EHR. Finally, we demonstrate our approaches on the case study and conclude by summarizing the literature on outcome misclassification and quantitative bias analysis.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


