{"title":"一种用于半自动评估药物价值集正确性的数据驱动迭代方法:基于阿片类药物的概念验证。","authors":"Linyi Li, Adela Grando, Abeed Sarker","doi":"10.1055/s-0041-1740358","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Value sets are lists of terms (e.g., opioid medication names) and their corresponding codes from standard clinical vocabularies (e.g., RxNorm) created with the intent of supporting health information exchange and research. Value sets are manually-created and often exhibit errors.</p><p><strong>Objectives: </strong>The aim of the study is to develop a semi-automatic, data-centric natural language processing (NLP) method to assess medication-related value set correctness and evaluate it on a set of opioid medication value sets.</p><p><strong>Methods: </strong>We developed an NLP algorithm that utilizes value sets containing mostly true positives and true negatives to learn lexical patterns associated with the true positives, and then employs these patterns to identify potential errors in unseen value sets. We evaluated the algorithm on a set of opioid medication value sets, using the recall, precision and F<sub>1</sub>-score metrics. We applied the trained model to assess the correctness of unseen opioid value sets based on recall. To replicate the application of the algorithm in real-world settings, a domain expert manually conducted error analysis to identify potential system and value set errors.</p><p><strong>Results: </strong>Thirty-eight value sets were retrieved from the Value Set Authority Center, and six (two opioid, four non-opioid) were used to develop and evaluate the system. Average precision, recall, and F<sub>1</sub>-score were 0.932, 0.904, and 0.909, respectively on uncorrected value sets; and 0.958, 0.953, and 0.953, respectively after manual correction of the same value sets. On 20 unseen opioid value sets, the algorithm obtained average recall of 0.89. Error analyses revealed that the main sources of system misclassifications were differences in how opioids were coded in the value sets-while the training value sets had generic names mostly, some of the unseen value sets had new trade names and ingredients.</p><p><strong>Conclusion: </strong>The proposed approach is data-centric, reusable, customizable, and not resource intensive. It may help domain experts to easily validate value sets.</p>","PeriodicalId":49822,"journal":{"name":"Methods of Information in Medicine","volume":" ","pages":"e111-e119"},"PeriodicalIF":1.8000,"publicationDate":"2021-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/ac/c9/10-1055-s-0041-1740358.PMC8716187.pdf","citationCount":"0","resultStr":"{\"title\":\"A Data-Driven Iterative Approach for Semi-automatically Assessing the Correctness of Medication Value Sets: A Proof of Concept Based on Opioids.\",\"authors\":\"Linyi Li, Adela Grando, Abeed Sarker\",\"doi\":\"10.1055/s-0041-1740358\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Value sets are lists of terms (e.g., opioid medication names) and their corresponding codes from standard clinical vocabularies (e.g., RxNorm) created with the intent of supporting health information exchange and research. Value sets are manually-created and often exhibit errors.</p><p><strong>Objectives: </strong>The aim of the study is to develop a semi-automatic, data-centric natural language processing (NLP) method to assess medication-related value set correctness and evaluate it on a set of opioid medication value sets.</p><p><strong>Methods: </strong>We developed an NLP algorithm that utilizes value sets containing mostly true positives and true negatives to learn lexical patterns associated with the true positives, and then employs these patterns to identify potential errors in unseen value sets. We evaluated the algorithm on a set of opioid medication value sets, using the recall, precision and F<sub>1</sub>-score metrics. We applied the trained model to assess the correctness of unseen opioid value sets based on recall. To replicate the application of the algorithm in real-world settings, a domain expert manually conducted error analysis to identify potential system and value set errors.</p><p><strong>Results: </strong>Thirty-eight value sets were retrieved from the Value Set Authority Center, and six (two opioid, four non-opioid) were used to develop and evaluate the system. Average precision, recall, and F<sub>1</sub>-score were 0.932, 0.904, and 0.909, respectively on uncorrected value sets; and 0.958, 0.953, and 0.953, respectively after manual correction of the same value sets. On 20 unseen opioid value sets, the algorithm obtained average recall of 0.89. Error analyses revealed that the main sources of system misclassifications were differences in how opioids were coded in the value sets-while the training value sets had generic names mostly, some of the unseen value sets had new trade names and ingredients.</p><p><strong>Conclusion: </strong>The proposed approach is data-centric, reusable, customizable, and not resource intensive. It may help domain experts to easily validate value sets.</p>\",\"PeriodicalId\":49822,\"journal\":{\"name\":\"Methods of Information in Medicine\",\"volume\":\" \",\"pages\":\"e111-e119\"},\"PeriodicalIF\":1.8000,\"publicationDate\":\"2021-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://ftp.ncbi.nlm.nih.gov/pub/pmc/oa_pdf/ac/c9/10-1055-s-0041-1740358.PMC8716187.pdf\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Methods of Information in Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1055/s-0041-1740358\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2021/12/29 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q3\",\"JCRName\":\"COMPUTER SCIENCE, INFORMATION SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Methods of Information in Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1055/s-0041-1740358","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/12/29 0:00:00","PubModel":"Epub","JCR":"Q3","JCRName":"COMPUTER SCIENCE, INFORMATION SYSTEMS","Score":null,"Total":0}
A Data-Driven Iterative Approach for Semi-automatically Assessing the Correctness of Medication Value Sets: A Proof of Concept Based on Opioids.
Background: Value sets are lists of terms (e.g., opioid medication names) and their corresponding codes from standard clinical vocabularies (e.g., RxNorm) created with the intent of supporting health information exchange and research. Value sets are manually-created and often exhibit errors.
Objectives: The aim of the study is to develop a semi-automatic, data-centric natural language processing (NLP) method to assess medication-related value set correctness and evaluate it on a set of opioid medication value sets.
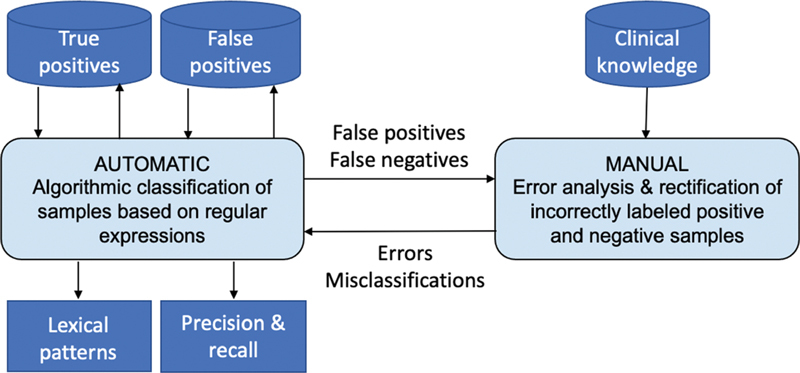
Methods: We developed an NLP algorithm that utilizes value sets containing mostly true positives and true negatives to learn lexical patterns associated with the true positives, and then employs these patterns to identify potential errors in unseen value sets. We evaluated the algorithm on a set of opioid medication value sets, using the recall, precision and F1-score metrics. We applied the trained model to assess the correctness of unseen opioid value sets based on recall. To replicate the application of the algorithm in real-world settings, a domain expert manually conducted error analysis to identify potential system and value set errors.
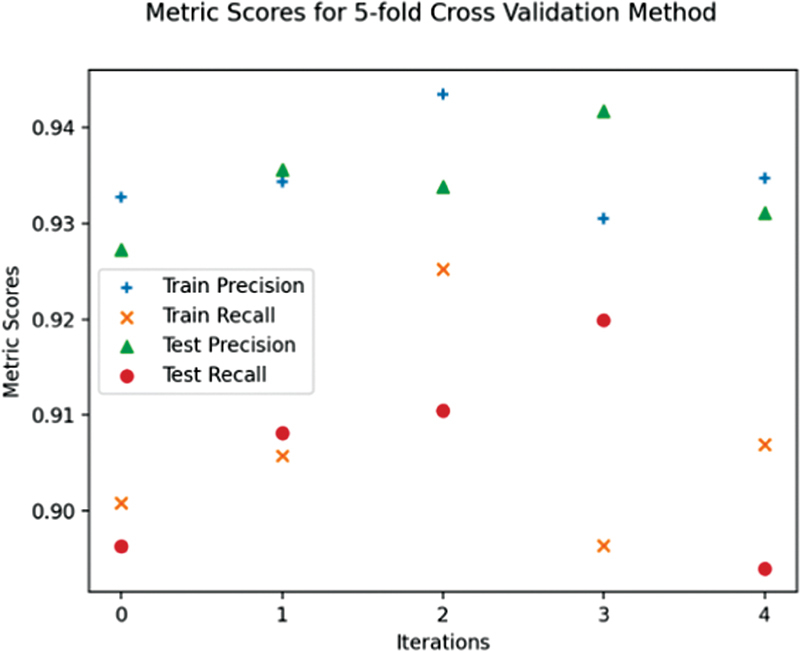
Results: Thirty-eight value sets were retrieved from the Value Set Authority Center, and six (two opioid, four non-opioid) were used to develop and evaluate the system. Average precision, recall, and F1-score were 0.932, 0.904, and 0.909, respectively on uncorrected value sets; and 0.958, 0.953, and 0.953, respectively after manual correction of the same value sets. On 20 unseen opioid value sets, the algorithm obtained average recall of 0.89. Error analyses revealed that the main sources of system misclassifications were differences in how opioids were coded in the value sets-while the training value sets had generic names mostly, some of the unseen value sets had new trade names and ingredients.
Conclusion: The proposed approach is data-centric, reusable, customizable, and not resource intensive. It may help domain experts to easily validate value sets.
期刊介绍:
Good medicine and good healthcare demand good information. Since the journal''s founding in 1962, Methods of Information in Medicine has stressed the methodology and scientific fundamentals of organizing, representing and analyzing data, information and knowledge in biomedicine and health care. Covering publications in the fields of biomedical and health informatics, medical biometry, and epidemiology, the journal publishes original papers, reviews, reports, opinion papers, editorials, and letters to the editor. From time to time, the journal publishes articles on particular focus themes as part of a journal''s issue.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


