Torleif Halkjelsvik, Antonio Gasparrini, Rannveig Kaldager Hart
{"title":"在公共卫生干预措施评估中使用分类数据:横断面依赖可能会使推断偏倚。","authors":"Torleif Halkjelsvik, Antonio Gasparrini, Rannveig Kaldager Hart","doi":"10.1186/s13690-022-00795-5","DOIUrl":null,"url":null,"abstract":"<p><p>Higher availability of administrative data and better infrastructure for electronic surveys allow for large sample sizes in evaluations of national and other large scale policies. Although larger datasets have many advantages, the use of big disaggregate data (e.g., on individuals, households, stores, municipalities) can be challenging in terms of statistical inference. Measurements made at the same point in time may be jointly influenced by contemporaneous factors and produce more variation across time than suggested by the model. This excess variation, or co-movement over time, produce observations that are not truly independent (i.e., cross-sectional dependence). If this dependency is not accounted for, statistical uncertainty will be underestimated, and studies may indicate reform effects where there is none. In the context of interrupted time series (segmented regression), we illustrate the potential for bias in inference when using large disaggregate data, and we describe two simple solutions that are available in standard statistical software.</p>","PeriodicalId":365748,"journal":{"name":"Archives of public health = Archives belges de sante publique","volume":" ","pages":"36"},"PeriodicalIF":0.0000,"publicationDate":"2022-01-20","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8772208/pdf/","citationCount":"0","resultStr":"{\"title\":\"The use of disaggregate data in evaluations of public health interventions: cross-sectional dependence can bias inference.\",\"authors\":\"Torleif Halkjelsvik, Antonio Gasparrini, Rannveig Kaldager Hart\",\"doi\":\"10.1186/s13690-022-00795-5\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Higher availability of administrative data and better infrastructure for electronic surveys allow for large sample sizes in evaluations of national and other large scale policies. Although larger datasets have many advantages, the use of big disaggregate data (e.g., on individuals, households, stores, municipalities) can be challenging in terms of statistical inference. Measurements made at the same point in time may be jointly influenced by contemporaneous factors and produce more variation across time than suggested by the model. This excess variation, or co-movement over time, produce observations that are not truly independent (i.e., cross-sectional dependence). If this dependency is not accounted for, statistical uncertainty will be underestimated, and studies may indicate reform effects where there is none. In the context of interrupted time series (segmented regression), we illustrate the potential for bias in inference when using large disaggregate data, and we describe two simple solutions that are available in standard statistical software.</p>\",\"PeriodicalId\":365748,\"journal\":{\"name\":\"Archives of public health = Archives belges de sante publique\",\"volume\":\" \",\"pages\":\"36\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-01-20\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8772208/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Archives of public health = Archives belges de sante publique\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s13690-022-00795-5\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Archives of public health = Archives belges de sante publique","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s13690-022-00795-5","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
The use of disaggregate data in evaluations of public health interventions: cross-sectional dependence can bias inference.
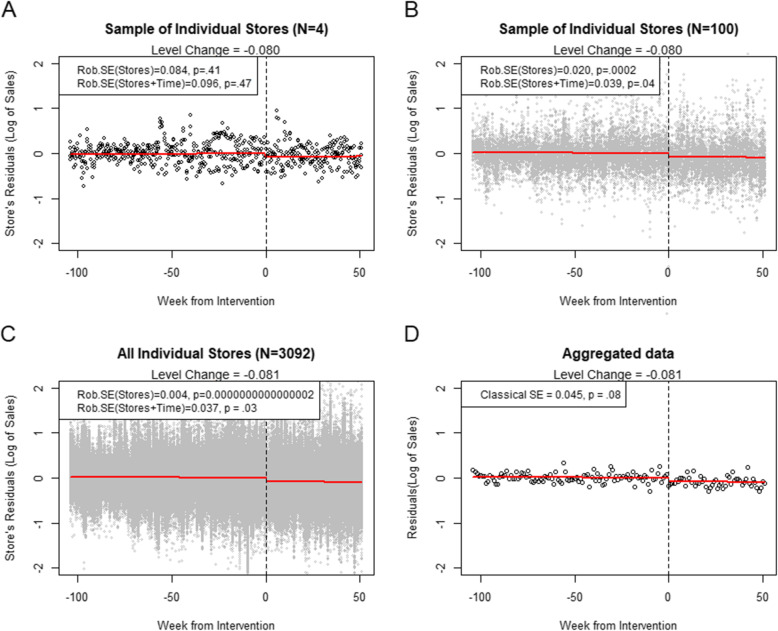
Higher availability of administrative data and better infrastructure for electronic surveys allow for large sample sizes in evaluations of national and other large scale policies. Although larger datasets have many advantages, the use of big disaggregate data (e.g., on individuals, households, stores, municipalities) can be challenging in terms of statistical inference. Measurements made at the same point in time may be jointly influenced by contemporaneous factors and produce more variation across time than suggested by the model. This excess variation, or co-movement over time, produce observations that are not truly independent (i.e., cross-sectional dependence). If this dependency is not accounted for, statistical uncertainty will be underestimated, and studies may indicate reform effects where there is none. In the context of interrupted time series (segmented regression), we illustrate the potential for bias in inference when using large disaggregate data, and we describe two simple solutions that are available in standard statistical software.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


