Vimala Balakrishnan, Zhongliang Shi, Chuan Liang Law, Regine Lim, Lee Leng Teh, Yue Fan
{"title":"预测产品情绪评级的深度学习方法:比较分析。","authors":"Vimala Balakrishnan, Zhongliang Shi, Chuan Liang Law, Regine Lim, Lee Leng Teh, Yue Fan","doi":"10.1007/s11227-021-04169-6","DOIUrl":null,"url":null,"abstract":"<p><p>We present a benchmark comparison of several deep learning models including Convolutional Neural Networks, Recurrent Neural Network and Bi-directional Long Short Term Memory, assessed based on various word embedding approaches, including the Bi-directional Encoder Representations from Transformers (BERT) and its variants, FastText and Word2Vec. Data augmentation was administered using the Easy Data Augmentation approach resulting in two datasets (original versus augmented). All the models were assessed in two setups, namely 5-class versus 3-class (i.e., compressed version). Findings show the best prediction models were Neural Network-based using Word2Vec, with CNN-RNN-Bi-LSTM producing the highest accuracy (96%) and <i>F</i>-score (91.1%). Individually, RNN was the best model with an accuracy of 87.5% and <i>F</i>-score of 83.5%, while RoBERTa had the best <i>F</i>-score of 73.1%. The study shows that deep learning is better for analyzing the sentiments within the text compared to supervised machine learning and provides a direction for future work and research.</p>","PeriodicalId":50034,"journal":{"name":"Journal of Supercomputing","volume":"78 5","pages":"7206-7226"},"PeriodicalIF":2.7000,"publicationDate":"2022-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8569508/pdf/","citationCount":"22","resultStr":"{\"title\":\"A deep learning approach in predicting products' sentiment ratings: a comparative analysis.\",\"authors\":\"Vimala Balakrishnan, Zhongliang Shi, Chuan Liang Law, Regine Lim, Lee Leng Teh, Yue Fan\",\"doi\":\"10.1007/s11227-021-04169-6\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>We present a benchmark comparison of several deep learning models including Convolutional Neural Networks, Recurrent Neural Network and Bi-directional Long Short Term Memory, assessed based on various word embedding approaches, including the Bi-directional Encoder Representations from Transformers (BERT) and its variants, FastText and Word2Vec. Data augmentation was administered using the Easy Data Augmentation approach resulting in two datasets (original versus augmented). All the models were assessed in two setups, namely 5-class versus 3-class (i.e., compressed version). Findings show the best prediction models were Neural Network-based using Word2Vec, with CNN-RNN-Bi-LSTM producing the highest accuracy (96%) and <i>F</i>-score (91.1%). Individually, RNN was the best model with an accuracy of 87.5% and <i>F</i>-score of 83.5%, while RoBERTa had the best <i>F</i>-score of 73.1%. The study shows that deep learning is better for analyzing the sentiments within the text compared to supervised machine learning and provides a direction for future work and research.</p>\",\"PeriodicalId\":50034,\"journal\":{\"name\":\"Journal of Supercomputing\",\"volume\":\"78 5\",\"pages\":\"7206-7226\"},\"PeriodicalIF\":2.7000,\"publicationDate\":\"2022-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8569508/pdf/\",\"citationCount\":\"22\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Supercomputing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1007/s11227-021-04169-6\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2021/11/5 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Supercomputing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1007/s11227-021-04169-6","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2021/11/5 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"COMPUTER SCIENCE, HARDWARE & ARCHITECTURE","Score":null,"Total":0}
A deep learning approach in predicting products' sentiment ratings: a comparative analysis.
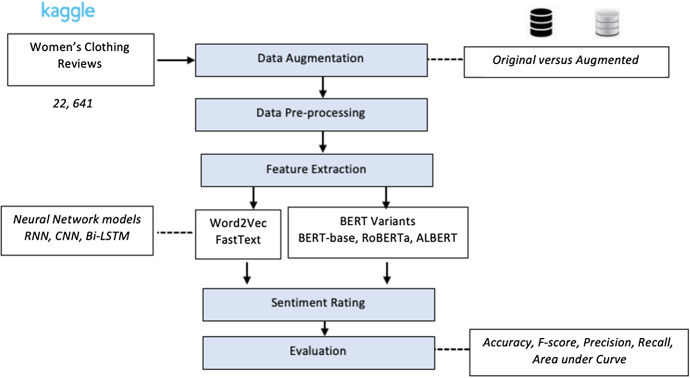
We present a benchmark comparison of several deep learning models including Convolutional Neural Networks, Recurrent Neural Network and Bi-directional Long Short Term Memory, assessed based on various word embedding approaches, including the Bi-directional Encoder Representations from Transformers (BERT) and its variants, FastText and Word2Vec. Data augmentation was administered using the Easy Data Augmentation approach resulting in two datasets (original versus augmented). All the models were assessed in two setups, namely 5-class versus 3-class (i.e., compressed version). Findings show the best prediction models were Neural Network-based using Word2Vec, with CNN-RNN-Bi-LSTM producing the highest accuracy (96%) and F-score (91.1%). Individually, RNN was the best model with an accuracy of 87.5% and F-score of 83.5%, while RoBERTa had the best F-score of 73.1%. The study shows that deep learning is better for analyzing the sentiments within the text compared to supervised machine learning and provides a direction for future work and research.
期刊介绍:
The Journal of Supercomputing publishes papers on the technology, architecture and systems, algorithms, languages and programs, performance measures and methods, and applications of all aspects of Supercomputing. Tutorial and survey papers are intended for workers and students in the fields associated with and employing advanced computer systems. The journal also publishes letters to the editor, especially in areas relating to policy, succinct statements of paradoxes, intuitively puzzling results, partial results and real needs.
Published theoretical and practical papers are advanced, in-depth treatments describing new developments and new ideas. Each includes an introduction summarizing prior, directly pertinent work that is useful for the reader to understand, in order to appreciate the advances being described.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


