Şenay Kafkas, Sara Althubaiti, Georgios V Gkoutos, Robert Hoehndorf, Paul N Schofield
{"title":"将常见的人类疾病与其表型联系起来;人类表型组学资源的开发。","authors":"Şenay Kafkas, Sara Althubaiti, Georgios V Gkoutos, Robert Hoehndorf, Paul N Schofield","doi":"10.1186/s13326-021-00249-x","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In recent years a large volume of clinical genomics data has become available due to rapid advances in sequencing technologies. Efficient exploitation of this genomics data requires linkage to patient phenotype profiles. Current resources providing disease-phenotype associations are not comprehensive, and they often do not have broad coverage of the disease terminologies, particularly ICD-10, which is still the primary terminology used in clinical settings.</p><p><strong>Methods: </strong>We developed two approaches to gather disease-phenotype associations. First, we used a text mining method that utilizes semantic relations in phenotype ontologies, and applies statistical methods to extract associations between diseases in ICD-10 and phenotype ontology classes from the literature. Second, we developed a semi-automatic way to collect ICD-10-phenotype associations from existing resources containing known relationships.</p><p><strong>Results: </strong>We generated four datasets. Two of them are independent datasets linking diseases to their phenotypes based on text mining and semi-automatic strategies. The remaining two datasets are generated from these datasets and cover a subset of ICD-10 classes of common diseases contained in UK Biobank. We extensively validated our text mined and semi-automatically curated datasets by: comparing them against an expert-curated validation dataset containing disease-phenotype associations, measuring their similarity to disease-phenotype associations found in public databases, and assessing how well they could be used to recover gene-disease associations using phenotype similarity.</p><p><strong>Conclusion: </strong>We find that our text mining method can produce phenotype annotations of diseases that are correct but often too general to have significant information content, or too specific to accurately reflect the typical manifestations of the sporadic disease. On the other hand, the datasets generated from integrating multiple knowledgebases are more complete (i.e., cover more of the required phenotype annotations for a given disease). We make all data freely available at https://doi.org/10.5281/zenodo.4726713 .</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":" ","pages":"17"},"PeriodicalIF":2.0000,"publicationDate":"2021-08-23","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8383460/pdf/","citationCount":"0","resultStr":"{\"title\":\"Linking common human diseases to their phenotypes; development of a resource for human phenomics.\",\"authors\":\"Şenay Kafkas, Sara Althubaiti, Georgios V Gkoutos, Robert Hoehndorf, Paul N Schofield\",\"doi\":\"10.1186/s13326-021-00249-x\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>In recent years a large volume of clinical genomics data has become available due to rapid advances in sequencing technologies. Efficient exploitation of this genomics data requires linkage to patient phenotype profiles. Current resources providing disease-phenotype associations are not comprehensive, and they often do not have broad coverage of the disease terminologies, particularly ICD-10, which is still the primary terminology used in clinical settings.</p><p><strong>Methods: </strong>We developed two approaches to gather disease-phenotype associations. First, we used a text mining method that utilizes semantic relations in phenotype ontologies, and applies statistical methods to extract associations between diseases in ICD-10 and phenotype ontology classes from the literature. Second, we developed a semi-automatic way to collect ICD-10-phenotype associations from existing resources containing known relationships.</p><p><strong>Results: </strong>We generated four datasets. Two of them are independent datasets linking diseases to their phenotypes based on text mining and semi-automatic strategies. The remaining two datasets are generated from these datasets and cover a subset of ICD-10 classes of common diseases contained in UK Biobank. We extensively validated our text mined and semi-automatically curated datasets by: comparing them against an expert-curated validation dataset containing disease-phenotype associations, measuring their similarity to disease-phenotype associations found in public databases, and assessing how well they could be used to recover gene-disease associations using phenotype similarity.</p><p><strong>Conclusion: </strong>We find that our text mining method can produce phenotype annotations of diseases that are correct but often too general to have significant information content, or too specific to accurately reflect the typical manifestations of the sporadic disease. On the other hand, the datasets generated from integrating multiple knowledgebases are more complete (i.e., cover more of the required phenotype annotations for a given disease). We make all data freely available at https://doi.org/10.5281/zenodo.4726713 .</p>\",\"PeriodicalId\":15055,\"journal\":{\"name\":\"Journal of Biomedical Semantics\",\"volume\":\" \",\"pages\":\"17\"},\"PeriodicalIF\":2.0000,\"publicationDate\":\"2021-08-23\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC8383460/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Semantics\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1186/s13326-021-00249-x\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-021-00249-x","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Linking common human diseases to their phenotypes; development of a resource for human phenomics.
Background: In recent years a large volume of clinical genomics data has become available due to rapid advances in sequencing technologies. Efficient exploitation of this genomics data requires linkage to patient phenotype profiles. Current resources providing disease-phenotype associations are not comprehensive, and they often do not have broad coverage of the disease terminologies, particularly ICD-10, which is still the primary terminology used in clinical settings.
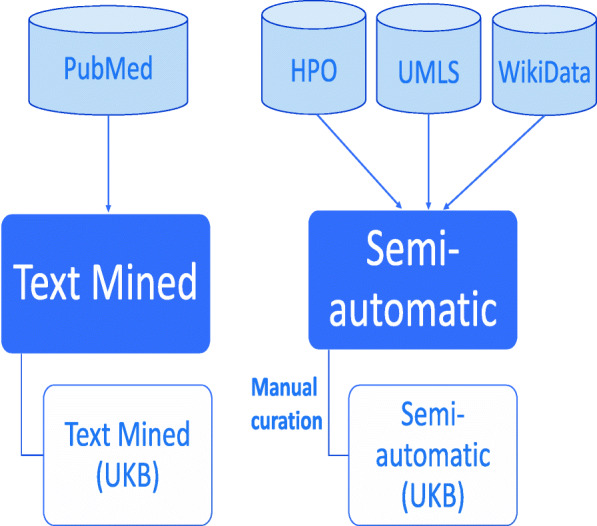
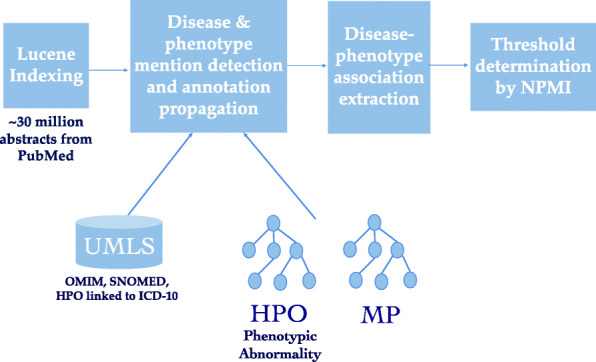
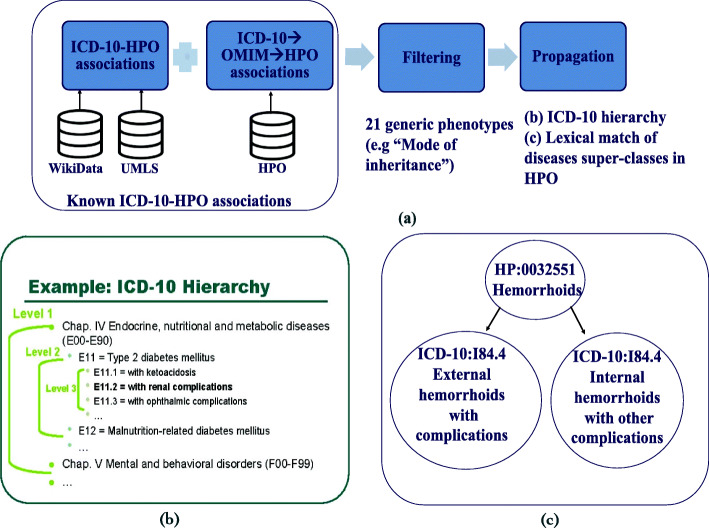
Methods: We developed two approaches to gather disease-phenotype associations. First, we used a text mining method that utilizes semantic relations in phenotype ontologies, and applies statistical methods to extract associations between diseases in ICD-10 and phenotype ontology classes from the literature. Second, we developed a semi-automatic way to collect ICD-10-phenotype associations from existing resources containing known relationships.
Results: We generated four datasets. Two of them are independent datasets linking diseases to their phenotypes based on text mining and semi-automatic strategies. The remaining two datasets are generated from these datasets and cover a subset of ICD-10 classes of common diseases contained in UK Biobank. We extensively validated our text mined and semi-automatically curated datasets by: comparing them against an expert-curated validation dataset containing disease-phenotype associations, measuring their similarity to disease-phenotype associations found in public databases, and assessing how well they could be used to recover gene-disease associations using phenotype similarity.
Conclusion: We find that our text mining method can produce phenotype annotations of diseases that are correct but often too general to have significant information content, or too specific to accurately reflect the typical manifestations of the sporadic disease. On the other hand, the datasets generated from integrating multiple knowledgebases are more complete (i.e., cover more of the required phenotype annotations for a given disease). We make all data freely available at https://doi.org/10.5281/zenodo.4726713 .
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


