Ivano Lauriola, Fabio Aiolli, Alberto Lavelli, Fabio Rinaldi
{"title":"生物医学领域实体识别的学习自适应表示。","authors":"Ivano Lauriola, Fabio Aiolli, Alberto Lavelli, Fabio Rinaldi","doi":"10.1186/s13326-021-00238-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>Named Entity Recognition is a common task in Natural Language Processing applications, whose purpose is to recognize named entities in textual documents. Several systems exist to solve this task in the biomedical domain, based on Natural Language Processing techniques and Machine Learning algorithms. A crucial step of these applications is the choice of the representation which describes data. Several representations have been proposed in the literature, some of which are based on a strong knowledge of the domain, and they consist of features manually defined by domain experts. Usually, these representations describe the problem well, but they require a lot of human effort and annotated data. On the other hand, general-purpose representations like word-embeddings do not require human domain knowledge, but they could be too general for a specific task.</p><p><strong>Results: </strong>This paper investigates methods to learn the best representation from data directly, by combining several knowledge-based representations and word embeddings. Two mechanisms have been considered to perform the combination, which are neural networks and Multiple Kernel Learning. To this end, we use a hybrid architecture for biomedical entity recognition which integrates dictionary look-up (also known as gazetteers) with machine learning techniques. Results on the CRAFT corpus clearly show the benefits of the proposed algorithm in terms of F<sub>1</sub> score.</p><p><strong>Conclusions: </strong>Our experiments show that the principled combination of general, domain specific, word-, and character-level representations improves the performance of entity recognition. We also discussed the contribution of each representation in the final solution.</p>","PeriodicalId":15055,"journal":{"name":"Journal of Biomedical Semantics","volume":" ","pages":"10"},"PeriodicalIF":1.6000,"publicationDate":"2021-05-17","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s13326-021-00238-0","citationCount":"2","resultStr":"{\"title\":\"Learning adaptive representations for entity recognition in the biomedical domain.\",\"authors\":\"Ivano Lauriola, Fabio Aiolli, Alberto Lavelli, Fabio Rinaldi\",\"doi\":\"10.1186/s13326-021-00238-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>Named Entity Recognition is a common task in Natural Language Processing applications, whose purpose is to recognize named entities in textual documents. Several systems exist to solve this task in the biomedical domain, based on Natural Language Processing techniques and Machine Learning algorithms. A crucial step of these applications is the choice of the representation which describes data. Several representations have been proposed in the literature, some of which are based on a strong knowledge of the domain, and they consist of features manually defined by domain experts. Usually, these representations describe the problem well, but they require a lot of human effort and annotated data. On the other hand, general-purpose representations like word-embeddings do not require human domain knowledge, but they could be too general for a specific task.</p><p><strong>Results: </strong>This paper investigates methods to learn the best representation from data directly, by combining several knowledge-based representations and word embeddings. Two mechanisms have been considered to perform the combination, which are neural networks and Multiple Kernel Learning. To this end, we use a hybrid architecture for biomedical entity recognition which integrates dictionary look-up (also known as gazetteers) with machine learning techniques. Results on the CRAFT corpus clearly show the benefits of the proposed algorithm in terms of F<sub>1</sub> score.</p><p><strong>Conclusions: </strong>Our experiments show that the principled combination of general, domain specific, word-, and character-level representations improves the performance of entity recognition. We also discussed the contribution of each representation in the final solution.</p>\",\"PeriodicalId\":15055,\"journal\":{\"name\":\"Journal of Biomedical Semantics\",\"volume\":\" \",\"pages\":\"10\"},\"PeriodicalIF\":1.6000,\"publicationDate\":\"2021-05-17\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/s13326-021-00238-0\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Biomedical Semantics\",\"FirstCategoryId\":\"5\",\"ListUrlMain\":\"https://doi.org/10.1186/s13326-021-00238-0\",\"RegionNum\":3,\"RegionCategory\":\"工程技术\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q3\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Biomedical Semantics","FirstCategoryId":"5","ListUrlMain":"https://doi.org/10.1186/s13326-021-00238-0","RegionNum":3,"RegionCategory":"工程技术","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q3","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Learning adaptive representations for entity recognition in the biomedical domain.
Background: Named Entity Recognition is a common task in Natural Language Processing applications, whose purpose is to recognize named entities in textual documents. Several systems exist to solve this task in the biomedical domain, based on Natural Language Processing techniques and Machine Learning algorithms. A crucial step of these applications is the choice of the representation which describes data. Several representations have been proposed in the literature, some of which are based on a strong knowledge of the domain, and they consist of features manually defined by domain experts. Usually, these representations describe the problem well, but they require a lot of human effort and annotated data. On the other hand, general-purpose representations like word-embeddings do not require human domain knowledge, but they could be too general for a specific task.
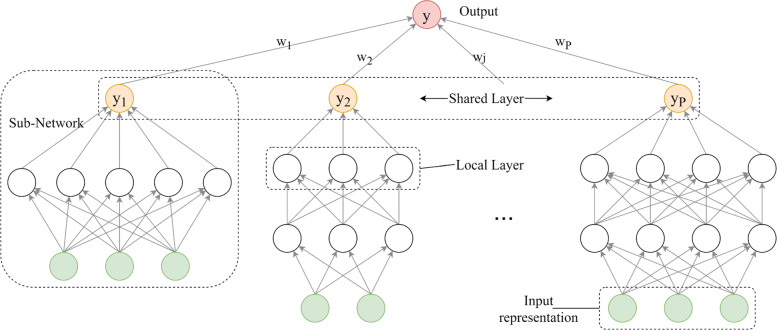
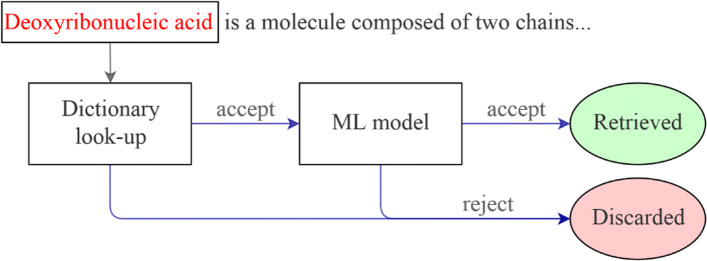
Results: This paper investigates methods to learn the best representation from data directly, by combining several knowledge-based representations and word embeddings. Two mechanisms have been considered to perform the combination, which are neural networks and Multiple Kernel Learning. To this end, we use a hybrid architecture for biomedical entity recognition which integrates dictionary look-up (also known as gazetteers) with machine learning techniques. Results on the CRAFT corpus clearly show the benefits of the proposed algorithm in terms of F1 score.
Conclusions: Our experiments show that the principled combination of general, domain specific, word-, and character-level representations improves the performance of entity recognition. We also discussed the contribution of each representation in the final solution.
期刊介绍:
Journal of Biomedical Semantics addresses issues of semantic enrichment and semantic processing in the biomedical domain. The scope of the journal covers two main areas:
Infrastructure for biomedical semantics: focusing on semantic resources and repositories, meta-data management and resource description, knowledge representation and semantic frameworks, the Biomedical Semantic Web, and semantic interoperability.
Semantic mining, annotation, and analysis: focusing on approaches and applications of semantic resources; and tools for investigation, reasoning, prediction, and discoveries in biomedicine.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


