Youhyeon Hwang, Min Oh, Giup Jang, Taekeon Lee, Chihyun Park, Jaegyoon Ahn and Youngmi Yoon
{"title":"确定ADR(药物不良反应)集群的共同遗传网络并建立ADR分类模型†","authors":"Youhyeon Hwang, Min Oh, Giup Jang, Taekeon Lee, Chihyun Park, Jaegyoon Ahn and Youngmi Yoon","doi":"10.1039/C7MB00059F","DOIUrl":null,"url":null,"abstract":"<p >Adverse drug reactions (ADRs) are one of the major concerns threatening public health and have resulted in failures in drug development. Thus, predicting ADRs and discovering the mechanisms underlying ADRs have become important tasks in pharmacovigilance. Identification of potential ADRs by computational approaches in the early stages would be advantageous in drug development. Here we propose a computational method that elucidates the action mechanisms of ADRs and predicts potential ADRs by utilizing ADR genes, drug features, and protein–protein interaction (PPI) networks. If some ADRs share similar features, there is a high possibility that they may appear together in a drug and share analogous mechanisms. Proceeding from this assumption, we clustered ADRs according to interactions of ADR genes in the PPI networks and the frequency of co-occurrence of ADRs in drugs. ADR clusters were verified based on a side effect database and literature data regarding whether ADRs have relevance to other ADRs in the same cluster. Gene networks shared by ADRs in each cluster were constructed by cumulating the shortest paths between drug target genes and ADR genes in the PPI network. We developed a classification model to predict potential ADRs using these gene networks shared by ADRs and calculated cross-validation AUC (area under the curve) values for each ADR cluster. In addition, in order to demonstrate correlations between gene networks shared by ADRs and ADRs in a cluster, we applied the Wilcoxon rank sum statistical test to the literature data and results of a Google query search. We attained statistically meaningful <em>p</em>-values (<0.05) for every ADR cluster. The results suggest that our approach provides insights into discovering the action mechanisms of ADRs and is a novel attempt to predict ADRs in a biological aspect.</p>","PeriodicalId":90,"journal":{"name":"Molecular BioSystems","volume":" 9","pages":" 1788-1796"},"PeriodicalIF":3.7430,"publicationDate":"2017-06-19","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1039/C7MB00059F","citationCount":"5","resultStr":"{\"title\":\"Identifying the common genetic networks of ADR (adverse drug reaction) clusters and developing an ADR classification model†\",\"authors\":\"Youhyeon Hwang, Min Oh, Giup Jang, Taekeon Lee, Chihyun Park, Jaegyoon Ahn and Youngmi Yoon\",\"doi\":\"10.1039/C7MB00059F\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p >Adverse drug reactions (ADRs) are one of the major concerns threatening public health and have resulted in failures in drug development. Thus, predicting ADRs and discovering the mechanisms underlying ADRs have become important tasks in pharmacovigilance. Identification of potential ADRs by computational approaches in the early stages would be advantageous in drug development. Here we propose a computational method that elucidates the action mechanisms of ADRs and predicts potential ADRs by utilizing ADR genes, drug features, and protein–protein interaction (PPI) networks. If some ADRs share similar features, there is a high possibility that they may appear together in a drug and share analogous mechanisms. Proceeding from this assumption, we clustered ADRs according to interactions of ADR genes in the PPI networks and the frequency of co-occurrence of ADRs in drugs. ADR clusters were verified based on a side effect database and literature data regarding whether ADRs have relevance to other ADRs in the same cluster. Gene networks shared by ADRs in each cluster were constructed by cumulating the shortest paths between drug target genes and ADR genes in the PPI network. We developed a classification model to predict potential ADRs using these gene networks shared by ADRs and calculated cross-validation AUC (area under the curve) values for each ADR cluster. In addition, in order to demonstrate correlations between gene networks shared by ADRs and ADRs in a cluster, we applied the Wilcoxon rank sum statistical test to the literature data and results of a Google query search. We attained statistically meaningful <em>p</em>-values (<0.05) for every ADR cluster. The results suggest that our approach provides insights into discovering the action mechanisms of ADRs and is a novel attempt to predict ADRs in a biological aspect.</p>\",\"PeriodicalId\":90,\"journal\":{\"name\":\"Molecular BioSystems\",\"volume\":\" 9\",\"pages\":\" 1788-1796\"},\"PeriodicalIF\":3.7430,\"publicationDate\":\"2017-06-19\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1039/C7MB00059F\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Molecular BioSystems\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://pubs.rsc.org/en/content/articlelanding/2017/mb/c7mb00059f\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Biochemistry, Genetics and Molecular Biology\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Molecular BioSystems","FirstCategoryId":"1085","ListUrlMain":"https://pubs.rsc.org/en/content/articlelanding/2017/mb/c7mb00059f","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
Identifying the common genetic networks of ADR (adverse drug reaction) clusters and developing an ADR classification model†
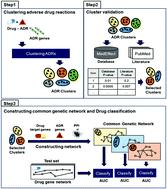
Adverse drug reactions (ADRs) are one of the major concerns threatening public health and have resulted in failures in drug development. Thus, predicting ADRs and discovering the mechanisms underlying ADRs have become important tasks in pharmacovigilance. Identification of potential ADRs by computational approaches in the early stages would be advantageous in drug development. Here we propose a computational method that elucidates the action mechanisms of ADRs and predicts potential ADRs by utilizing ADR genes, drug features, and protein–protein interaction (PPI) networks. If some ADRs share similar features, there is a high possibility that they may appear together in a drug and share analogous mechanisms. Proceeding from this assumption, we clustered ADRs according to interactions of ADR genes in the PPI networks and the frequency of co-occurrence of ADRs in drugs. ADR clusters were verified based on a side effect database and literature data regarding whether ADRs have relevance to other ADRs in the same cluster. Gene networks shared by ADRs in each cluster were constructed by cumulating the shortest paths between drug target genes and ADR genes in the PPI network. We developed a classification model to predict potential ADRs using these gene networks shared by ADRs and calculated cross-validation AUC (area under the curve) values for each ADR cluster. In addition, in order to demonstrate correlations between gene networks shared by ADRs and ADRs in a cluster, we applied the Wilcoxon rank sum statistical test to the literature data and results of a Google query search. We attained statistically meaningful p-values (<0.05) for every ADR cluster. The results suggest that our approach provides insights into discovering the action mechanisms of ADRs and is a novel attempt to predict ADRs in a biological aspect.
期刊介绍:
Molecular Omics publishes molecular level experimental and bioinformatics research in the -omics sciences, including genomics, proteomics, transcriptomics and metabolomics. We will also welcome multidisciplinary papers presenting studies combining different types of omics, or the interface of omics and other fields such as systems biology or chemical biology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


