Shahzad Ashraf, Sehrish Saleem, Tauqeer Ahmed, Zeeshan Aslam, Durr Muhammad
{"title":"利用抽样指标将不利的数据语料库转换为精明的输出。","authors":"Shahzad Ashraf, Sehrish Saleem, Tauqeer Ahmed, Zeeshan Aslam, Durr Muhammad","doi":"10.1186/s42492-020-00055-9","DOIUrl":null,"url":null,"abstract":"<p><p>An imbalanced dataset is commonly found in at least one class, which are typically exceeded by the other ones. A machine learning algorithm (classifier) trained with an imbalanced dataset predicts the majority class (frequently occurring) more than the other minority classes (rarely occurring). Training with an imbalanced dataset poses challenges for classifiers; however, applying suitable techniques for reducing class imbalance issues can enhance classifiers' performance. In this study, we consider an imbalanced dataset from an educational context. Initially, we examine all shortcomings regarding the classification of an imbalanced dataset. Then, we apply data-level algorithms for class balancing and compare the performance of classifiers. The performance of the classifiers is measured using the underlying information in their confusion matrices, such as accuracy, precision, recall, and F measure. The results show that classification with an imbalanced dataset may produce high accuracy but low precision and recall for the minority class. The analysis confirms that undersampling and oversampling are effective for balancing datasets, but the latter dominates.</p>","PeriodicalId":52384,"journal":{"name":"Visual Computing for Industry, Biomedicine, and Art","volume":"3 1","pages":"19"},"PeriodicalIF":6.0000,"publicationDate":"2020-08-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s42492-020-00055-9","citationCount":"25","resultStr":"{\"title\":\"Conversion of adverse data corpus to shrewd output using sampling metrics.\",\"authors\":\"Shahzad Ashraf, Sehrish Saleem, Tauqeer Ahmed, Zeeshan Aslam, Durr Muhammad\",\"doi\":\"10.1186/s42492-020-00055-9\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>An imbalanced dataset is commonly found in at least one class, which are typically exceeded by the other ones. A machine learning algorithm (classifier) trained with an imbalanced dataset predicts the majority class (frequently occurring) more than the other minority classes (rarely occurring). Training with an imbalanced dataset poses challenges for classifiers; however, applying suitable techniques for reducing class imbalance issues can enhance classifiers' performance. In this study, we consider an imbalanced dataset from an educational context. Initially, we examine all shortcomings regarding the classification of an imbalanced dataset. Then, we apply data-level algorithms for class balancing and compare the performance of classifiers. The performance of the classifiers is measured using the underlying information in their confusion matrices, such as accuracy, precision, recall, and F measure. The results show that classification with an imbalanced dataset may produce high accuracy but low precision and recall for the minority class. The analysis confirms that undersampling and oversampling are effective for balancing datasets, but the latter dominates.</p>\",\"PeriodicalId\":52384,\"journal\":{\"name\":\"Visual Computing for Industry, Biomedicine, and Art\",\"volume\":\"3 1\",\"pages\":\"19\"},\"PeriodicalIF\":6.0000,\"publicationDate\":\"2020-08-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/s42492-020-00055-9\",\"citationCount\":\"25\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Visual Computing for Industry, Biomedicine, and Art\",\"FirstCategoryId\":\"1093\",\"ListUrlMain\":\"https://doi.org/10.1186/s42492-020-00055-9\",\"RegionNum\":4,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"Arts and Humanities\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Visual Computing for Industry, Biomedicine, and Art","FirstCategoryId":"1093","ListUrlMain":"https://doi.org/10.1186/s42492-020-00055-9","RegionNum":4,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"Arts and Humanities","Score":null,"Total":0}
Conversion of adverse data corpus to shrewd output using sampling metrics.
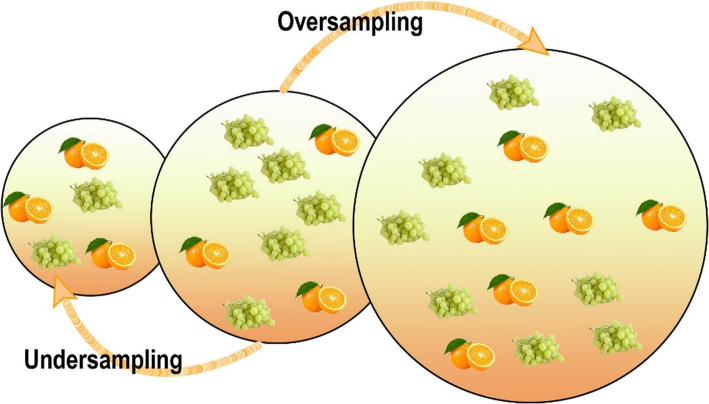
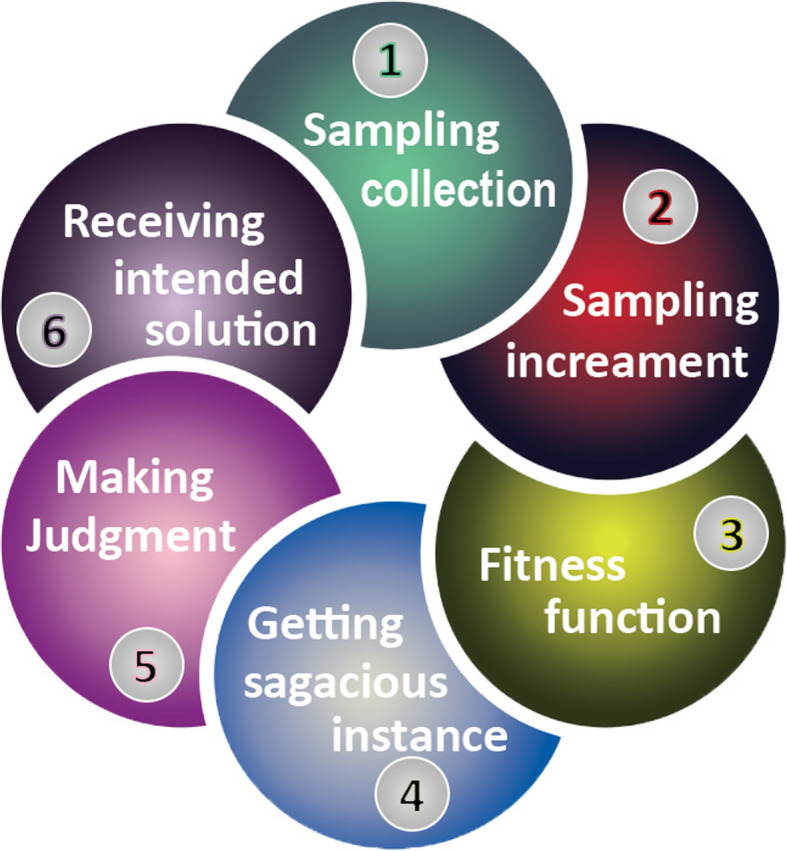
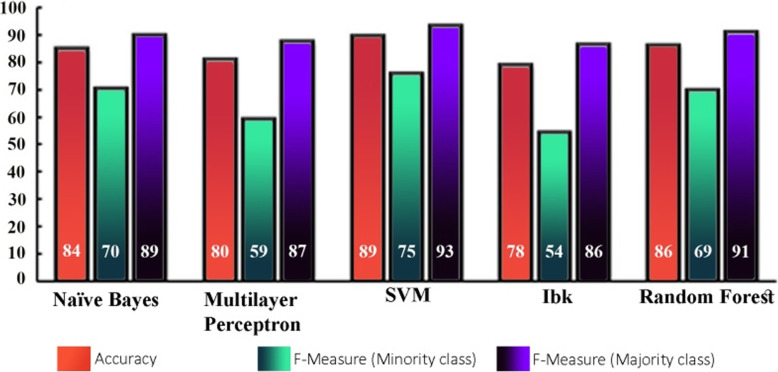
An imbalanced dataset is commonly found in at least one class, which are typically exceeded by the other ones. A machine learning algorithm (classifier) trained with an imbalanced dataset predicts the majority class (frequently occurring) more than the other minority classes (rarely occurring). Training with an imbalanced dataset poses challenges for classifiers; however, applying suitable techniques for reducing class imbalance issues can enhance classifiers' performance. In this study, we consider an imbalanced dataset from an educational context. Initially, we examine all shortcomings regarding the classification of an imbalanced dataset. Then, we apply data-level algorithms for class balancing and compare the performance of classifiers. The performance of the classifiers is measured using the underlying information in their confusion matrices, such as accuracy, precision, recall, and F measure. The results show that classification with an imbalanced dataset may produce high accuracy but low precision and recall for the minority class. The analysis confirms that undersampling and oversampling are effective for balancing datasets, but the latter dominates.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


