Andrea Caccamisi, Leif Jørgensen, Hercules Dalianis, Mats Rosenlund
{"title":"通过自然语言处理和机器学习,可以从电子病历中自动提取和分类患者的吸烟状况。","authors":"Andrea Caccamisi, Leif Jørgensen, Hercules Dalianis, Mats Rosenlund","doi":"10.1080/03009734.2020.1792010","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The electronic medical record (EMR) offers unique possibilities for clinical research, but some important patient attributes are not readily available due to its unstructured properties. We applied text mining using machine learning to enable automatic classification of unstructured information on smoking status from Swedish EMR data.</p><p><strong>Methods: </strong>Data on patients' smoking status from EMRs were used to develop 32 different predictive models that were trained using Weka, changing sentence frequency, classifier type, tokenization, and attribute selection in a database of 85,000 classified sentences. The models were evaluated using F-score and accuracy based on out-of-sample test data including 8500 sentences. The error weight matrix was used to select the best model, assigning a weight to each type of misclassification and applying it to the model confusion matrices. The best performing model was then compared to a rule-based method.</p><p><strong>Results: </strong>The best performing model was based on the Support Vector Machine (SVM) Sequential Minimal Optimization (SMO) classifier using a combination of unigrams and bigrams as tokens. Sentence frequency and attributes selection did not improve model performance. SMO achieved 98.14% accuracy and 0.981 F-score versus 79.32% and 0.756 for the rule-based model.</p><p><strong>Conclusion: </strong>A model using machine-learning algorithms to automatically classify patients' smoking status was successfully developed. Such algorithms may enable automatic assessment of smoking status and other unstructured data directly from EMRs without manual classification of complete case notes.</p>","PeriodicalId":23458,"journal":{"name":"Upsala journal of medical sciences","volume":"125 4","pages":"316-324"},"PeriodicalIF":1.5000,"publicationDate":"2020-11-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1080/03009734.2020.1792010","citationCount":"16","resultStr":"{\"title\":\"Natural language processing and machine learning to enable automatic extraction and classification of patients' smoking status from electronic medical records.\",\"authors\":\"Andrea Caccamisi, Leif Jørgensen, Hercules Dalianis, Mats Rosenlund\",\"doi\":\"10.1080/03009734.2020.1792010\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The electronic medical record (EMR) offers unique possibilities for clinical research, but some important patient attributes are not readily available due to its unstructured properties. We applied text mining using machine learning to enable automatic classification of unstructured information on smoking status from Swedish EMR data.</p><p><strong>Methods: </strong>Data on patients' smoking status from EMRs were used to develop 32 different predictive models that were trained using Weka, changing sentence frequency, classifier type, tokenization, and attribute selection in a database of 85,000 classified sentences. The models were evaluated using F-score and accuracy based on out-of-sample test data including 8500 sentences. The error weight matrix was used to select the best model, assigning a weight to each type of misclassification and applying it to the model confusion matrices. The best performing model was then compared to a rule-based method.</p><p><strong>Results: </strong>The best performing model was based on the Support Vector Machine (SVM) Sequential Minimal Optimization (SMO) classifier using a combination of unigrams and bigrams as tokens. Sentence frequency and attributes selection did not improve model performance. SMO achieved 98.14% accuracy and 0.981 F-score versus 79.32% and 0.756 for the rule-based model.</p><p><strong>Conclusion: </strong>A model using machine-learning algorithms to automatically classify patients' smoking status was successfully developed. Such algorithms may enable automatic assessment of smoking status and other unstructured data directly from EMRs without manual classification of complete case notes.</p>\",\"PeriodicalId\":23458,\"journal\":{\"name\":\"Upsala journal of medical sciences\",\"volume\":\"125 4\",\"pages\":\"316-324\"},\"PeriodicalIF\":1.5000,\"publicationDate\":\"2020-11-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1080/03009734.2020.1792010\",\"citationCount\":\"16\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Upsala journal of medical sciences\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.1080/03009734.2020.1792010\",\"RegionNum\":4,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2020/7/22 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"MEDICINE, GENERAL & INTERNAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Upsala journal of medical sciences","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.1080/03009734.2020.1792010","RegionNum":4,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2020/7/22 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
Natural language processing and machine learning to enable automatic extraction and classification of patients' smoking status from electronic medical records.
Background: The electronic medical record (EMR) offers unique possibilities for clinical research, but some important patient attributes are not readily available due to its unstructured properties. We applied text mining using machine learning to enable automatic classification of unstructured information on smoking status from Swedish EMR data.
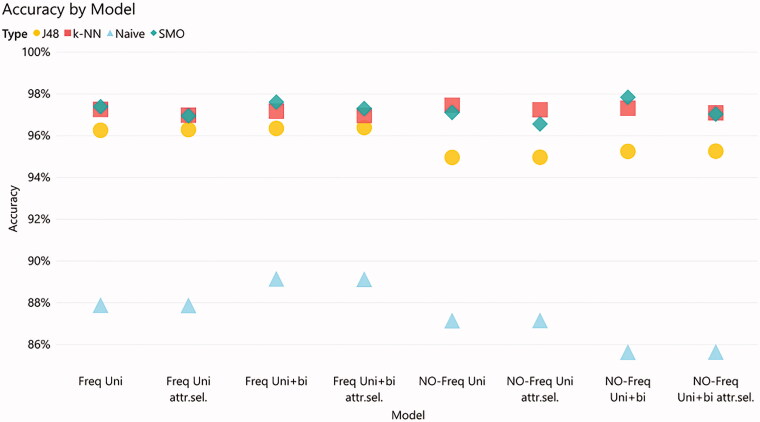
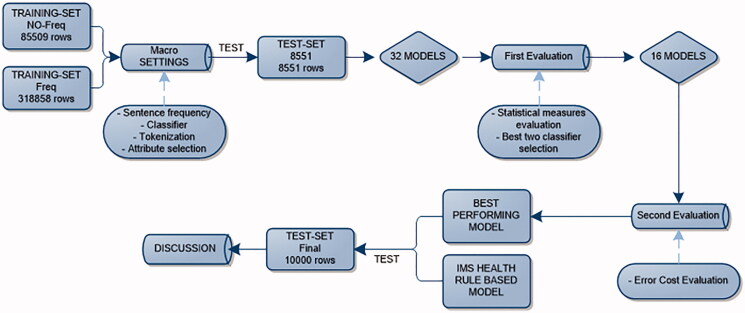
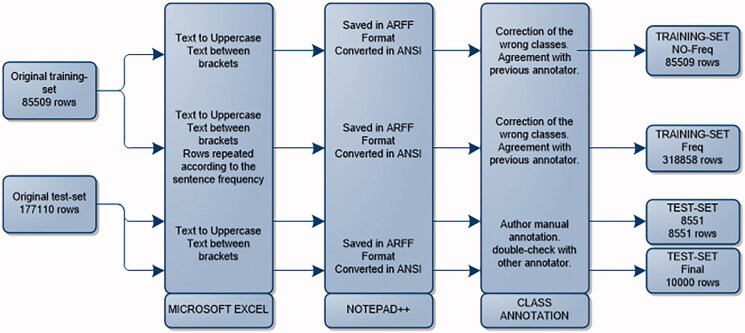
Methods: Data on patients' smoking status from EMRs were used to develop 32 different predictive models that were trained using Weka, changing sentence frequency, classifier type, tokenization, and attribute selection in a database of 85,000 classified sentences. The models were evaluated using F-score and accuracy based on out-of-sample test data including 8500 sentences. The error weight matrix was used to select the best model, assigning a weight to each type of misclassification and applying it to the model confusion matrices. The best performing model was then compared to a rule-based method.
Results: The best performing model was based on the Support Vector Machine (SVM) Sequential Minimal Optimization (SMO) classifier using a combination of unigrams and bigrams as tokens. Sentence frequency and attributes selection did not improve model performance. SMO achieved 98.14% accuracy and 0.981 F-score versus 79.32% and 0.756 for the rule-based model.
Conclusion: A model using machine-learning algorithms to automatically classify patients' smoking status was successfully developed. Such algorithms may enable automatic assessment of smoking status and other unstructured data directly from EMRs without manual classification of complete case notes.
期刊介绍:
Upsala Journal of Medical Sciences is published for the Upsala Medical Society. It has been published since 1865 and is one of the oldest medical journals in Sweden.
The journal publishes clinical and experimental original works in the medical field. Although focusing on regional issues, the journal always welcomes contributions from outside Sweden.
Specially extended issues are published occasionally, dealing with special topics, congress proceedings and academic dissertations.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


