Giuseppe Agapito, Marzia Settino, Francesca Scionti, Emanuela Altomare, Pietro Hiram Guzzi, Pierfrancesco Tassone, Pierosandro Tagliaferri, Mario Cannataro, Mariamena Arbitrio, Maria Teresa Di Martino
{"title":"DMETTM基因分型:精准医学时代发现生物标志物的工具。","authors":"Giuseppe Agapito, Marzia Settino, Francesca Scionti, Emanuela Altomare, Pietro Hiram Guzzi, Pierfrancesco Tassone, Pierosandro Tagliaferri, Mario Cannataro, Mariamena Arbitrio, Maria Teresa Di Martino","doi":"10.3390/ht9020008","DOIUrl":null,"url":null,"abstract":"<p><p>The knowledge of genetic variants in genes involved in drug metabolism may be translated into reduction of adverse drug reactions, increase of efficacy, healthcare outcomes improvement and economic benefits. Many high-throughput tools are available for the genotyping of Single Nucleotide Polymorphisms (SNPs) known to be related to drugs and xenobiotics metabolism. DMET<sup>TM</sup> platform represents an example of SNPs panel to discover biomarkers correlated to efficacy or toxicity in common and rare diseases. The difficulty in analyzing the mole of information generated by DMET<sup>TM</sup> platform led to the development and implementation of algorithms and tools for statistical and data mining analysis. These softwares allow efficient handling of the omics data to validate the explorative SNPs identified by DMET assay and to correlate them with drug efficacy, toxicity and/or cancer susceptibility. In this review we present a suite of bioinformatic frameworks for the preprocessing and analysis of DMET-SNPs data. In particular, we introduce a workflow that uses the GenoMetric Query Language, a high-level query language specifically designed for genomics, able to query public datasets (such as ENCODE, TCGA, GENCODE annotation dataset, etc.) as well as to combine them with private datasets (e.g., output from Affymetrix® DMET<sup>TM</sup> Platform).</p>","PeriodicalId":53433,"journal":{"name":"High-Throughput","volume":"9 2","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2020-03-29","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.3390/ht9020008","citationCount":"9","resultStr":"{\"title\":\"DMET<sup>TM</sup> Genotyping: Tools for Biomarkers Discovery in the Era of Precision Medicine.\",\"authors\":\"Giuseppe Agapito, Marzia Settino, Francesca Scionti, Emanuela Altomare, Pietro Hiram Guzzi, Pierfrancesco Tassone, Pierosandro Tagliaferri, Mario Cannataro, Mariamena Arbitrio, Maria Teresa Di Martino\",\"doi\":\"10.3390/ht9020008\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The knowledge of genetic variants in genes involved in drug metabolism may be translated into reduction of adverse drug reactions, increase of efficacy, healthcare outcomes improvement and economic benefits. Many high-throughput tools are available for the genotyping of Single Nucleotide Polymorphisms (SNPs) known to be related to drugs and xenobiotics metabolism. DMET<sup>TM</sup> platform represents an example of SNPs panel to discover biomarkers correlated to efficacy or toxicity in common and rare diseases. The difficulty in analyzing the mole of information generated by DMET<sup>TM</sup> platform led to the development and implementation of algorithms and tools for statistical and data mining analysis. These softwares allow efficient handling of the omics data to validate the explorative SNPs identified by DMET assay and to correlate them with drug efficacy, toxicity and/or cancer susceptibility. In this review we present a suite of bioinformatic frameworks for the preprocessing and analysis of DMET-SNPs data. In particular, we introduce a workflow that uses the GenoMetric Query Language, a high-level query language specifically designed for genomics, able to query public datasets (such as ENCODE, TCGA, GENCODE annotation dataset, etc.) as well as to combine them with private datasets (e.g., output from Affymetrix® DMET<sup>TM</sup> Platform).</p>\",\"PeriodicalId\":53433,\"journal\":{\"name\":\"High-Throughput\",\"volume\":\"9 2\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2020-03-29\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.3390/ht9020008\",\"citationCount\":\"9\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"High-Throughput\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/ht9020008\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Biochemistry, Genetics and Molecular Biology\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"High-Throughput","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/ht9020008","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
DMETTM Genotyping: Tools for Biomarkers Discovery in the Era of Precision Medicine.
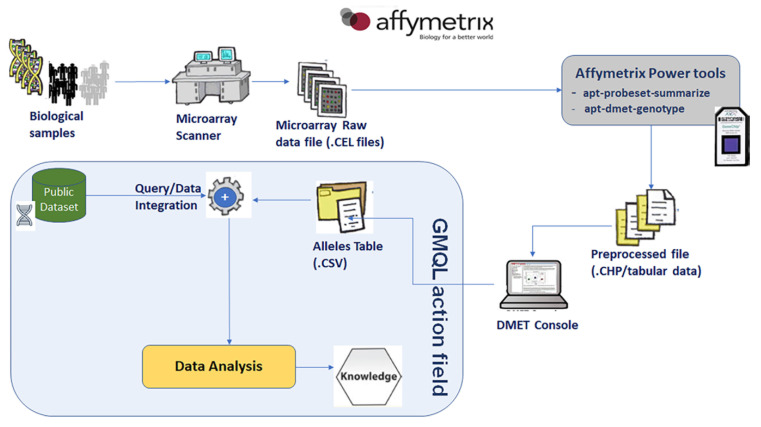
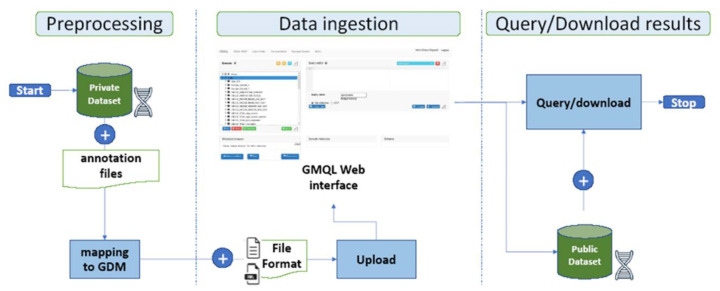
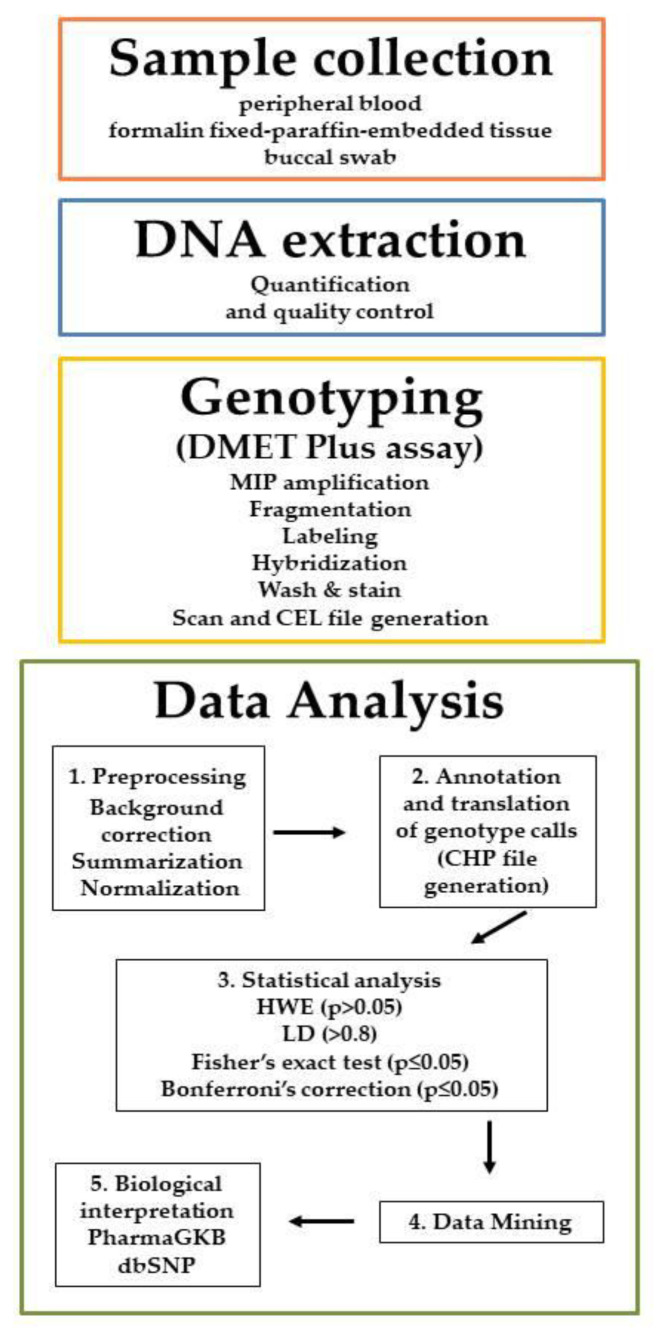
The knowledge of genetic variants in genes involved in drug metabolism may be translated into reduction of adverse drug reactions, increase of efficacy, healthcare outcomes improvement and economic benefits. Many high-throughput tools are available for the genotyping of Single Nucleotide Polymorphisms (SNPs) known to be related to drugs and xenobiotics metabolism. DMETTM platform represents an example of SNPs panel to discover biomarkers correlated to efficacy or toxicity in common and rare diseases. The difficulty in analyzing the mole of information generated by DMETTM platform led to the development and implementation of algorithms and tools for statistical and data mining analysis. These softwares allow efficient handling of the omics data to validate the explorative SNPs identified by DMET assay and to correlate them with drug efficacy, toxicity and/or cancer susceptibility. In this review we present a suite of bioinformatic frameworks for the preprocessing and analysis of DMET-SNPs data. In particular, we introduce a workflow that uses the GenoMetric Query Language, a high-level query language specifically designed for genomics, able to query public datasets (such as ENCODE, TCGA, GENCODE annotation dataset, etc.) as well as to combine them with private datasets (e.g., output from Affymetrix® DMETTM Platform).
High-ThroughputBiochemistry, Genetics and Molecular Biology-Biotechnology
CiteScore
3.60
自引率
0.00%
发文量
0
审稿时长
9 weeks
期刊介绍:
High-Throughput (formerly Microarrays, ISSN 2076-3905) is a multidisciplinary peer-reviewed scientific journal that provides an advanced forum for the publication of studies reporting high-dimensional approaches and developments in Life Sciences, Chemistry and related fields. Our aim is to encourage scientists to publish their experimental and theoretical results based on high-throughput techniques as well as computational and statistical tools for data analysis and interpretation. The full experimental or methodological details must be provided so that the results can be reproduced. There is no restriction on the length of the papers. High-Throughput invites submissions covering several topics, including, but not limited to: -Microarrays -DNA Sequencing -RNA Sequencing -Protein Identification and Quantification -Cell-based Approaches -Omics Technologies -Imaging -Bioinformatics -Computational Biology/Chemistry -Statistics -Integrative Omics -Drug Discovery and Development -Microfluidics -Lab-on-a-chip -Data Mining -Databases -Multiplex Assays

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


