Maruan Al-Shedivat, Andrew Gordon Wilson, Yunus Saatchi, Zhiting Hu, Eric P Xing
{"title":"用循环结构学习可扩展深度核。","authors":"Maruan Al-Shedivat, Andrew Gordon Wilson, Yunus Saatchi, Zhiting Hu, Eric P Xing","doi":"","DOIUrl":null,"url":null,"abstract":"<p><p>Many applications in speech, robotics, finance, and biology deal with sequential data, where ordering matters and recurrent structures are common. However, this structure cannot be easily captured by standard kernel functions. To model such structure, we propose expressive closed-form kernel functions for Gaussian processes. The resulting model, GP-LSTM, fully encapsulates the inductive biases of long short-term memory (LSTM) recurrent networks, while retaining the non-parametric probabilistic advantages of Gaussian processes. We learn the properties of the proposed kernels by optimizing the Gaussian process marginal likelihood using a new provably convergent semi-stochastic gradient procedure, and exploit the structure of these kernels for scalable training and prediction. This approach provides a practical representation for Bayesian LSTMs. We demonstrate state-of-the-art performance on several benchmarks, and thoroughly investigate a consequential autonomous driving application, where the predictive uncertainties provided by GP-LSTM are uniquely valuable.</p>","PeriodicalId":50161,"journal":{"name":"Journal of Machine Learning Research","volume":null,"pages":null},"PeriodicalIF":4.3000,"publicationDate":"2017-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6334642/pdf/","citationCount":"0","resultStr":"{\"title\":\"Learning Scalable Deep Kernels with Recurrent Structure.\",\"authors\":\"Maruan Al-Shedivat, Andrew Gordon Wilson, Yunus Saatchi, Zhiting Hu, Eric P Xing\",\"doi\":\"\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Many applications in speech, robotics, finance, and biology deal with sequential data, where ordering matters and recurrent structures are common. However, this structure cannot be easily captured by standard kernel functions. To model such structure, we propose expressive closed-form kernel functions for Gaussian processes. The resulting model, GP-LSTM, fully encapsulates the inductive biases of long short-term memory (LSTM) recurrent networks, while retaining the non-parametric probabilistic advantages of Gaussian processes. We learn the properties of the proposed kernels by optimizing the Gaussian process marginal likelihood using a new provably convergent semi-stochastic gradient procedure, and exploit the structure of these kernels for scalable training and prediction. This approach provides a practical representation for Bayesian LSTMs. We demonstrate state-of-the-art performance on several benchmarks, and thoroughly investigate a consequential autonomous driving application, where the predictive uncertainties provided by GP-LSTM are uniquely valuable.</p>\",\"PeriodicalId\":50161,\"journal\":{\"name\":\"Journal of Machine Learning Research\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":4.3000,\"publicationDate\":\"2017-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6334642/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Machine Learning Research\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"AUTOMATION & CONTROL SYSTEMS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Machine Learning Research","FirstCategoryId":"94","ListUrlMain":"","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"AUTOMATION & CONTROL SYSTEMS","Score":null,"Total":0}
Learning Scalable Deep Kernels with Recurrent Structure.
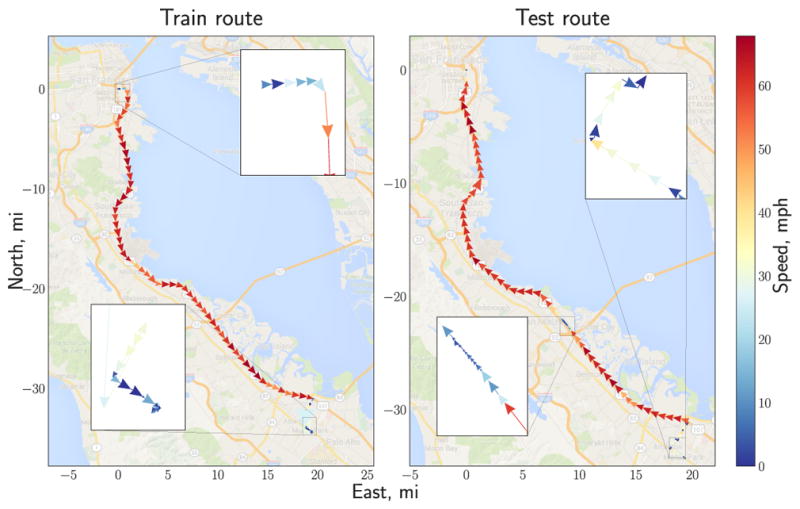
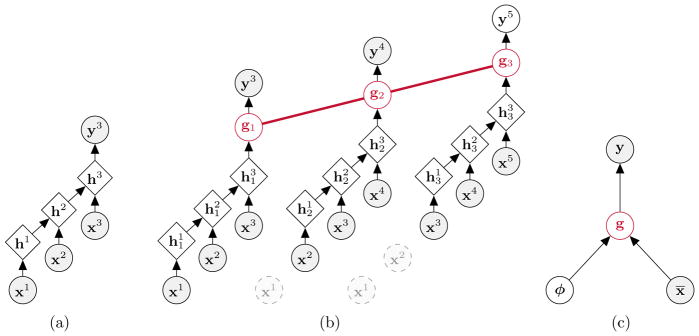
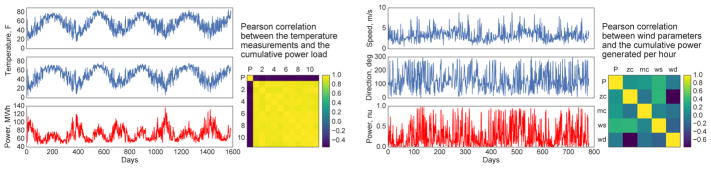
Many applications in speech, robotics, finance, and biology deal with sequential data, where ordering matters and recurrent structures are common. However, this structure cannot be easily captured by standard kernel functions. To model such structure, we propose expressive closed-form kernel functions for Gaussian processes. The resulting model, GP-LSTM, fully encapsulates the inductive biases of long short-term memory (LSTM) recurrent networks, while retaining the non-parametric probabilistic advantages of Gaussian processes. We learn the properties of the proposed kernels by optimizing the Gaussian process marginal likelihood using a new provably convergent semi-stochastic gradient procedure, and exploit the structure of these kernels for scalable training and prediction. This approach provides a practical representation for Bayesian LSTMs. We demonstrate state-of-the-art performance on several benchmarks, and thoroughly investigate a consequential autonomous driving application, where the predictive uncertainties provided by GP-LSTM are uniquely valuable.
期刊介绍:
The Journal of Machine Learning Research (JMLR) provides an international forum for the electronic and paper publication of high-quality scholarly articles in all areas of machine learning. All published papers are freely available online.
JMLR has a commitment to rigorous yet rapid reviewing.
JMLR seeks previously unpublished papers on machine learning that contain:
new principled algorithms with sound empirical validation, and with justification of theoretical, psychological, or biological nature;
experimental and/or theoretical studies yielding new insight into the design and behavior of learning in intelligent systems;
accounts of applications of existing techniques that shed light on the strengths and weaknesses of the methods;
formalization of new learning tasks (e.g., in the context of new applications) and of methods for assessing performance on those tasks;
development of new analytical frameworks that advance theoretical studies of practical learning methods;
computational models of data from natural learning systems at the behavioral or neural level; or extremely well-written surveys of existing work.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


