Sridhar Krishna Nemala, Dmitry N Zotkin, Ramani Duraiswami, Mounya Elhilali
{"title":"鲁棒说话人识别的仿生多分辨率分析。","authors":"Sridhar Krishna Nemala, Dmitry N Zotkin, Ramani Duraiswami, Mounya Elhilali","doi":"10.1186/1687-4722-2012-22","DOIUrl":null,"url":null,"abstract":"<p><p>Humans exhibit a remarkable ability to reliably classify sound sources in the environment even in presence of high levels of noise. In contrast, most engineering systems suffer a drastic drop in performance when speech signals are corrupted with channel or background distortions. Our brains are equipped with elaborate machinery for speech analysis and feature extraction, which hold great lessons for improving the performance of automatic speech processing systems under adverse conditions. The work presented here explores a biologically-motivated multi-resolution speaker information representation obtained by performing an intricate yet computationally-efficient analysis of the information-rich spectro-temporal attributes of the speech signal. We evaluate the proposed features in a speaker verification task performed on NIST SRE 2010 data. The biomimetic approach yields significant robustness in presence of non-stationary noise and reverberation, offering a new framework for deriving reliable features for speaker recognition and speech processing.</p>","PeriodicalId":49202,"journal":{"name":"Eurasip Journal on Audio Speech and Music Processing","volume":"2012 ","pages":""},"PeriodicalIF":1.9000,"publicationDate":"2012-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1687-4722-2012-22","citationCount":"5","resultStr":"{\"title\":\"Biomimetic multi-resolution analysis for robust speaker recognition.\",\"authors\":\"Sridhar Krishna Nemala, Dmitry N Zotkin, Ramani Duraiswami, Mounya Elhilali\",\"doi\":\"10.1186/1687-4722-2012-22\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Humans exhibit a remarkable ability to reliably classify sound sources in the environment even in presence of high levels of noise. In contrast, most engineering systems suffer a drastic drop in performance when speech signals are corrupted with channel or background distortions. Our brains are equipped with elaborate machinery for speech analysis and feature extraction, which hold great lessons for improving the performance of automatic speech processing systems under adverse conditions. The work presented here explores a biologically-motivated multi-resolution speaker information representation obtained by performing an intricate yet computationally-efficient analysis of the information-rich spectro-temporal attributes of the speech signal. We evaluate the proposed features in a speaker verification task performed on NIST SRE 2010 data. The biomimetic approach yields significant robustness in presence of non-stationary noise and reverberation, offering a new framework for deriving reliable features for speaker recognition and speech processing.</p>\",\"PeriodicalId\":49202,\"journal\":{\"name\":\"Eurasip Journal on Audio Speech and Music Processing\",\"volume\":\"2012 \",\"pages\":\"\"},\"PeriodicalIF\":1.9000,\"publicationDate\":\"2012-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/1687-4722-2012-22\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Eurasip Journal on Audio Speech and Music Processing\",\"FirstCategoryId\":\"94\",\"ListUrlMain\":\"https://doi.org/10.1186/1687-4722-2012-22\",\"RegionNum\":3,\"RegionCategory\":\"计算机科学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2012/9/7 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q2\",\"JCRName\":\"ACOUSTICS\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Eurasip Journal on Audio Speech and Music Processing","FirstCategoryId":"94","ListUrlMain":"https://doi.org/10.1186/1687-4722-2012-22","RegionNum":3,"RegionCategory":"计算机科学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2012/9/7 0:00:00","PubModel":"Epub","JCR":"Q2","JCRName":"ACOUSTICS","Score":null,"Total":0}
Biomimetic multi-resolution analysis for robust speaker recognition.
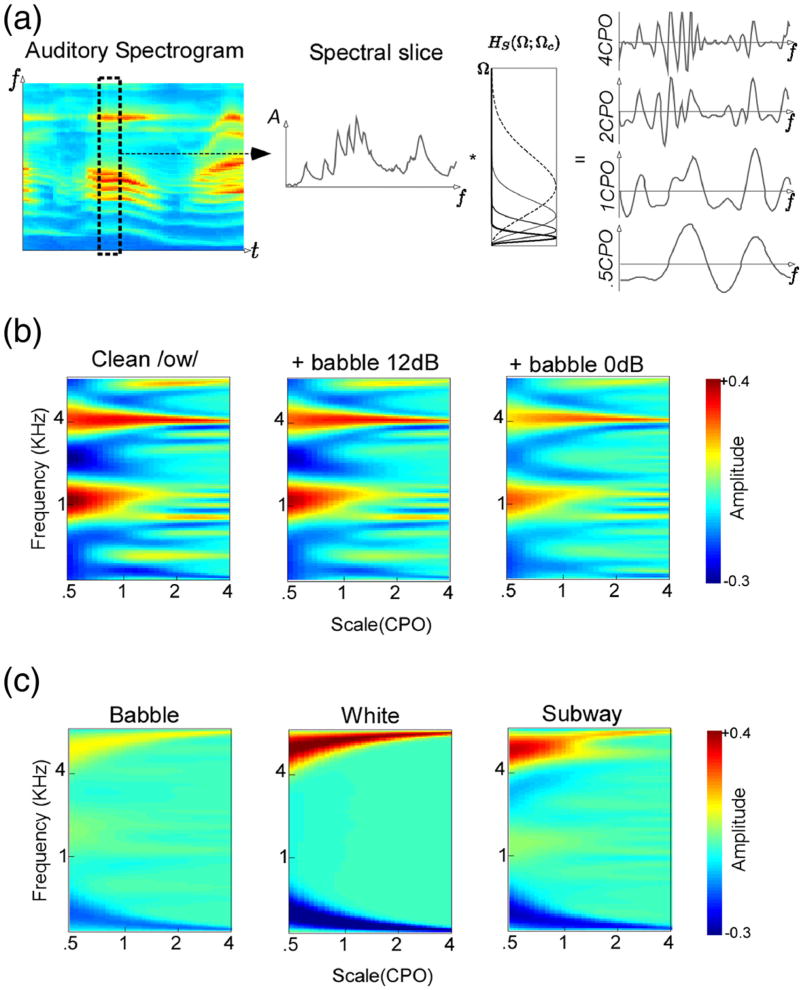
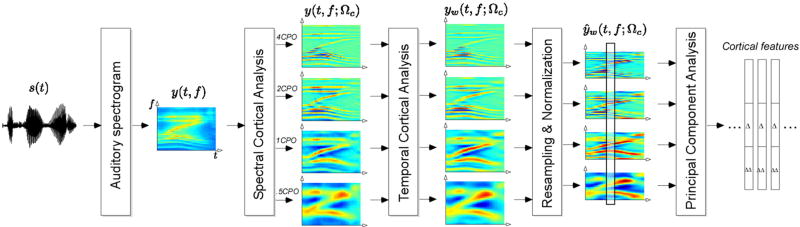
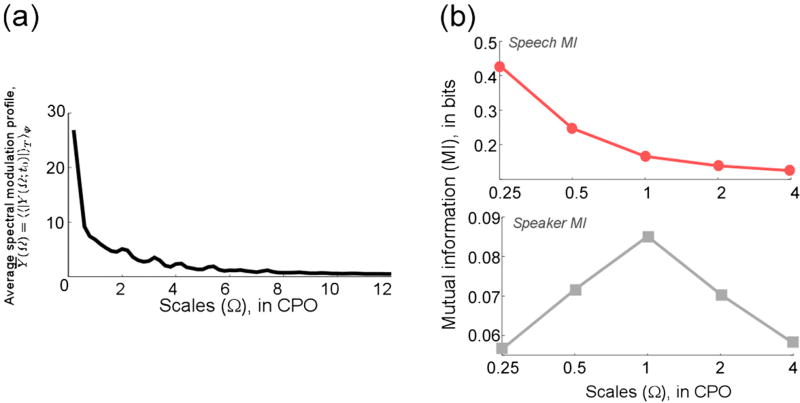
Humans exhibit a remarkable ability to reliably classify sound sources in the environment even in presence of high levels of noise. In contrast, most engineering systems suffer a drastic drop in performance when speech signals are corrupted with channel or background distortions. Our brains are equipped with elaborate machinery for speech analysis and feature extraction, which hold great lessons for improving the performance of automatic speech processing systems under adverse conditions. The work presented here explores a biologically-motivated multi-resolution speaker information representation obtained by performing an intricate yet computationally-efficient analysis of the information-rich spectro-temporal attributes of the speech signal. We evaluate the proposed features in a speaker verification task performed on NIST SRE 2010 data. The biomimetic approach yields significant robustness in presence of non-stationary noise and reverberation, offering a new framework for deriving reliable features for speaker recognition and speech processing.
期刊介绍:
The aim of “EURASIP Journal on Audio, Speech, and Music Processing” is to bring together researchers, scientists and engineers working on the theory and applications of the processing of various audio signals, with a specific focus on speech and music. EURASIP Journal on Audio, Speech, and Music Processing will be an interdisciplinary journal for the dissemination of all basic and applied aspects of speech communication and audio processes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


