{"title":"作者通过他的方法确定:EuPA解决了YPIC挑战","authors":"M.I. Indeykina , D.A. Podgrudkov , A.S. Kononikhin","doi":"10.1016/j.euprot.2018.10.001","DOIUrl":null,"url":null,"abstract":"<div><p>Here we present the results of our attempt on the EuPA YPIC challenge. The task was to sequence the provided synthetic peptides, build the sentence encrypted in them and determine from which book the sentence originated.</p><p>The task itself, while holding no direct scientific value, offers an insight in less formal terms (for participants at least) on how the overall process of a scientific study of a “new protein” looks like. Hence, we decided to look at the challenge as if it was a general task of sequencing an unknown protein from an unusual proteome database. To solve the task we used LC–MS/MS, MALDI-MS and de novo sequencing. A combination of two MS instruments and de novo MS/MS data analysis make it possible to sequence new peptides and proteins not yet present in proteomic databases.</p></div>","PeriodicalId":38260,"journal":{"name":"EuPA Open Proteomics","volume":"20 ","pages":"Pages 1-8"},"PeriodicalIF":0.0000,"publicationDate":"2018-12-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1016/j.euprot.2018.10.001","citationCount":"1","resultStr":"{\"title\":\"The author identified by his method: EuPA YPIC challenge solved\",\"authors\":\"M.I. Indeykina , D.A. Podgrudkov , A.S. Kononikhin\",\"doi\":\"10.1016/j.euprot.2018.10.001\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<div><p>Here we present the results of our attempt on the EuPA YPIC challenge. The task was to sequence the provided synthetic peptides, build the sentence encrypted in them and determine from which book the sentence originated.</p><p>The task itself, while holding no direct scientific value, offers an insight in less formal terms (for participants at least) on how the overall process of a scientific study of a “new protein” looks like. Hence, we decided to look at the challenge as if it was a general task of sequencing an unknown protein from an unusual proteome database. To solve the task we used LC–MS/MS, MALDI-MS and de novo sequencing. A combination of two MS instruments and de novo MS/MS data analysis make it possible to sequence new peptides and proteins not yet present in proteomic databases.</p></div>\",\"PeriodicalId\":38260,\"journal\":{\"name\":\"EuPA Open Proteomics\",\"volume\":\"20 \",\"pages\":\"Pages 1-8\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2018-12-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1016/j.euprot.2018.10.001\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"EuPA Open Proteomics\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://www.sciencedirect.com/science/article/pii/S2212968517300156\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q4\",\"JCRName\":\"Biochemistry, Genetics and Molecular Biology\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"EuPA Open Proteomics","FirstCategoryId":"1085","ListUrlMain":"https://www.sciencedirect.com/science/article/pii/S2212968517300156","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q4","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
The author identified by his method: EuPA YPIC challenge solved
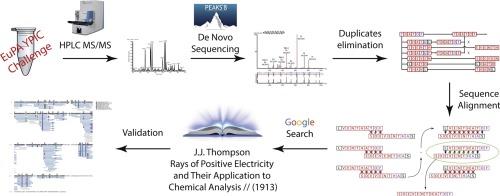
Here we present the results of our attempt on the EuPA YPIC challenge. The task was to sequence the provided synthetic peptides, build the sentence encrypted in them and determine from which book the sentence originated.
The task itself, while holding no direct scientific value, offers an insight in less formal terms (for participants at least) on how the overall process of a scientific study of a “new protein” looks like. Hence, we decided to look at the challenge as if it was a general task of sequencing an unknown protein from an unusual proteome database. To solve the task we used LC–MS/MS, MALDI-MS and de novo sequencing. A combination of two MS instruments and de novo MS/MS data analysis make it possible to sequence new peptides and proteins not yet present in proteomic databases.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


