Giuseppe Agapito, Pietro Hiram Guzzi, Mario Cannataro
{"title":"DMET微阵列基因分型数据分析的并行软件流水线。","authors":"Giuseppe Agapito, Pietro Hiram Guzzi, Mario Cannataro","doi":"10.3390/ht7020017","DOIUrl":null,"url":null,"abstract":"<p><p>Personalized medicine is an aspect of the P4 medicine (predictive, preventive, personalized and participatory) based precisely on the customization of all medical characters of each subject. In personalized medicine, the development of medical treatments and drugs is tailored to the individual characteristics and needs of each subject, according to the study of diseases at different scales from genotype to phenotype scale. To make concrete the goal of personalized medicine, it is necessary to employ high-throughput methodologies such as Next Generation Sequencing (NGS), Genome-Wide Association Studies (GWAS), Mass Spectrometry or Microarrays, that are able to investigate a single disease from a broader perspective. A side effect of high-throughput methodologies is the massive amount of data produced for each single experiment, that poses several challenges (e.g., high execution time and required memory) to bioinformatic software. Thus a main requirement of modern bioinformatic softwares, is the use of good software engineering methods and efficient programming techniques, able to face those challenges, that include the use of parallel programming and efficient and compact data structures. This paper presents the design and the experimentation of a comprehensive software pipeline, named microPipe, for the preprocessing, annotation and analysis of microarray-based Single Nucleotide Polymorphism (SNP) genotyping data. A use case in pharmacogenomics is presented. The main advantages of using microPipe are: the reduction of errors that may happen when trying to make data compatible among different tools; the possibility to analyze in parallel huge datasets; the easy annotation and integration of data. microPipe is available under Creative Commons license, and is freely downloadable for academic and not-for-profit institutions.</p>","PeriodicalId":53433,"journal":{"name":"High-Throughput","volume":"7 2","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2018-06-14","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.3390/ht7020017","citationCount":"1","resultStr":"{\"title\":\"A Parallel Software Pipeline for DMET Microarray Genotyping Data Analysis.\",\"authors\":\"Giuseppe Agapito, Pietro Hiram Guzzi, Mario Cannataro\",\"doi\":\"10.3390/ht7020017\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Personalized medicine is an aspect of the P4 medicine (predictive, preventive, personalized and participatory) based precisely on the customization of all medical characters of each subject. In personalized medicine, the development of medical treatments and drugs is tailored to the individual characteristics and needs of each subject, according to the study of diseases at different scales from genotype to phenotype scale. To make concrete the goal of personalized medicine, it is necessary to employ high-throughput methodologies such as Next Generation Sequencing (NGS), Genome-Wide Association Studies (GWAS), Mass Spectrometry or Microarrays, that are able to investigate a single disease from a broader perspective. A side effect of high-throughput methodologies is the massive amount of data produced for each single experiment, that poses several challenges (e.g., high execution time and required memory) to bioinformatic software. Thus a main requirement of modern bioinformatic softwares, is the use of good software engineering methods and efficient programming techniques, able to face those challenges, that include the use of parallel programming and efficient and compact data structures. This paper presents the design and the experimentation of a comprehensive software pipeline, named microPipe, for the preprocessing, annotation and analysis of microarray-based Single Nucleotide Polymorphism (SNP) genotyping data. A use case in pharmacogenomics is presented. The main advantages of using microPipe are: the reduction of errors that may happen when trying to make data compatible among different tools; the possibility to analyze in parallel huge datasets; the easy annotation and integration of data. microPipe is available under Creative Commons license, and is freely downloadable for academic and not-for-profit institutions.</p>\",\"PeriodicalId\":53433,\"journal\":{\"name\":\"High-Throughput\",\"volume\":\"7 2\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2018-06-14\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.3390/ht7020017\",\"citationCount\":\"1\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"High-Throughput\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/ht7020017\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Biochemistry, Genetics and Molecular Biology\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"High-Throughput","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/ht7020017","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
A Parallel Software Pipeline for DMET Microarray Genotyping Data Analysis.
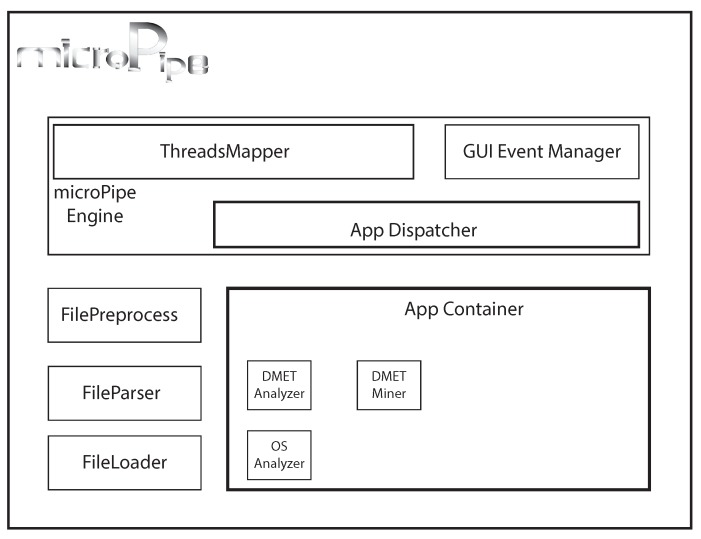
Personalized medicine is an aspect of the P4 medicine (predictive, preventive, personalized and participatory) based precisely on the customization of all medical characters of each subject. In personalized medicine, the development of medical treatments and drugs is tailored to the individual characteristics and needs of each subject, according to the study of diseases at different scales from genotype to phenotype scale. To make concrete the goal of personalized medicine, it is necessary to employ high-throughput methodologies such as Next Generation Sequencing (NGS), Genome-Wide Association Studies (GWAS), Mass Spectrometry or Microarrays, that are able to investigate a single disease from a broader perspective. A side effect of high-throughput methodologies is the massive amount of data produced for each single experiment, that poses several challenges (e.g., high execution time and required memory) to bioinformatic software. Thus a main requirement of modern bioinformatic softwares, is the use of good software engineering methods and efficient programming techniques, able to face those challenges, that include the use of parallel programming and efficient and compact data structures. This paper presents the design and the experimentation of a comprehensive software pipeline, named microPipe, for the preprocessing, annotation and analysis of microarray-based Single Nucleotide Polymorphism (SNP) genotyping data. A use case in pharmacogenomics is presented. The main advantages of using microPipe are: the reduction of errors that may happen when trying to make data compatible among different tools; the possibility to analyze in parallel huge datasets; the easy annotation and integration of data. microPipe is available under Creative Commons license, and is freely downloadable for academic and not-for-profit institutions.
High-ThroughputBiochemistry, Genetics and Molecular Biology-Biotechnology
CiteScore
3.60
自引率
0.00%
发文量
0
审稿时长
9 weeks
期刊介绍:
High-Throughput (formerly Microarrays, ISSN 2076-3905) is a multidisciplinary peer-reviewed scientific journal that provides an advanced forum for the publication of studies reporting high-dimensional approaches and developments in Life Sciences, Chemistry and related fields. Our aim is to encourage scientists to publish their experimental and theoretical results based on high-throughput techniques as well as computational and statistical tools for data analysis and interpretation. The full experimental or methodological details must be provided so that the results can be reproduced. There is no restriction on the length of the papers. High-Throughput invites submissions covering several topics, including, but not limited to: -Microarrays -DNA Sequencing -RNA Sequencing -Protein Identification and Quantification -Cell-based Approaches -Omics Technologies -Imaging -Bioinformatics -Computational Biology/Chemistry -Statistics -Integrative Omics -Drug Discovery and Development -Microfluidics -Lab-on-a-chip -Data Mining -Databases -Multiplex Assays


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


