Konstantin Avrachenkov, Vivek S Borkar, Arun Kadavankandy, Jithin K Sreedharan
{"title":"网络中基于随机漫步的重访抽样:回避老化期和频繁再生。","authors":"Konstantin Avrachenkov, Vivek S Borkar, Arun Kadavankandy, Jithin K Sreedharan","doi":"10.1186/s40649-018-0051-0","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In the framework of network sampling, random walk (RW) based estimation techniques provide many pragmatic solutions while uncovering the unknown network as little as possible. Despite several theoretical advances in this area, RW based sampling techniques usually make a strong assumption that the samples are in stationary regime, and hence are impelled to leave out the samples collected during the burn-in period.</p><p><strong>Methods: </strong>This work proposes two sampling schemes without burn-in time constraint to estimate the average of an arbitrary function defined on the network nodes, for example, the average age of users in a social network. The central idea of the algorithms lies in exploiting regeneration of RWs at revisits to an aggregated super-node or to a set of nodes, and in strategies to enhance the frequency of such regenerations either by contracting the graph or by making the hitting set larger. Our first algorithm, which is based on reinforcement learning (RL), uses stochastic approximation to derive an estimator. This method can be seen as intermediate between purely stochastic Markov chain Monte Carlo iterations and deterministic relative value iterations. The second algorithm, which we call the Ratio with Tours (RT)-estimator, is a modified form of respondent-driven sampling (RDS) that accommodates the idea of regeneration.</p><p><strong>Results: </strong>We study the methods via simulations on real networks. We observe that the trajectories of RL-estimator are much more stable than those of standard random walk based estimation procedures, and its error performance is comparable to that of respondent-driven sampling (RDS) which has a smaller asymptotic variance than many other estimators. Simulation studies also show that the mean squared error of RT-estimator decays much faster than that of RDS with time.</p><p><strong>Conclusion: </strong>The newly developed RW based estimators (RL- and RT-estimators) allow to avoid burn-in period, provide better control of stability along the sample path, and overall reduce the estimation time. Our estimators can be applied in social and complex networks.</p>","PeriodicalId":52145,"journal":{"name":"Computational Social Networks","volume":"5 1","pages":"4"},"PeriodicalIF":0.0000,"publicationDate":"2018-01-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/s40649-018-0051-0","citationCount":"8","resultStr":"{\"title\":\"Revisiting random walk based sampling in networks: evasion of burn-in period and frequent regenerations.\",\"authors\":\"Konstantin Avrachenkov, Vivek S Borkar, Arun Kadavankandy, Jithin K Sreedharan\",\"doi\":\"10.1186/s40649-018-0051-0\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>In the framework of network sampling, random walk (RW) based estimation techniques provide many pragmatic solutions while uncovering the unknown network as little as possible. Despite several theoretical advances in this area, RW based sampling techniques usually make a strong assumption that the samples are in stationary regime, and hence are impelled to leave out the samples collected during the burn-in period.</p><p><strong>Methods: </strong>This work proposes two sampling schemes without burn-in time constraint to estimate the average of an arbitrary function defined on the network nodes, for example, the average age of users in a social network. The central idea of the algorithms lies in exploiting regeneration of RWs at revisits to an aggregated super-node or to a set of nodes, and in strategies to enhance the frequency of such regenerations either by contracting the graph or by making the hitting set larger. Our first algorithm, which is based on reinforcement learning (RL), uses stochastic approximation to derive an estimator. This method can be seen as intermediate between purely stochastic Markov chain Monte Carlo iterations and deterministic relative value iterations. The second algorithm, which we call the Ratio with Tours (RT)-estimator, is a modified form of respondent-driven sampling (RDS) that accommodates the idea of regeneration.</p><p><strong>Results: </strong>We study the methods via simulations on real networks. We observe that the trajectories of RL-estimator are much more stable than those of standard random walk based estimation procedures, and its error performance is comparable to that of respondent-driven sampling (RDS) which has a smaller asymptotic variance than many other estimators. Simulation studies also show that the mean squared error of RT-estimator decays much faster than that of RDS with time.</p><p><strong>Conclusion: </strong>The newly developed RW based estimators (RL- and RT-estimators) allow to avoid burn-in period, provide better control of stability along the sample path, and overall reduce the estimation time. Our estimators can be applied in social and complex networks.</p>\",\"PeriodicalId\":52145,\"journal\":{\"name\":\"Computational Social Networks\",\"volume\":\"5 1\",\"pages\":\"4\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2018-01-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/s40649-018-0051-0\",\"citationCount\":\"8\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Computational Social Networks\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/s40649-018-0051-0\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2018/3/19 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"Q1\",\"JCRName\":\"Mathematics\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Computational Social Networks","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/s40649-018-0051-0","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2018/3/19 0:00:00","PubModel":"Epub","JCR":"Q1","JCRName":"Mathematics","Score":null,"Total":0}
Revisiting random walk based sampling in networks: evasion of burn-in period and frequent regenerations.
Background: In the framework of network sampling, random walk (RW) based estimation techniques provide many pragmatic solutions while uncovering the unknown network as little as possible. Despite several theoretical advances in this area, RW based sampling techniques usually make a strong assumption that the samples are in stationary regime, and hence are impelled to leave out the samples collected during the burn-in period.
Methods: This work proposes two sampling schemes without burn-in time constraint to estimate the average of an arbitrary function defined on the network nodes, for example, the average age of users in a social network. The central idea of the algorithms lies in exploiting regeneration of RWs at revisits to an aggregated super-node or to a set of nodes, and in strategies to enhance the frequency of such regenerations either by contracting the graph or by making the hitting set larger. Our first algorithm, which is based on reinforcement learning (RL), uses stochastic approximation to derive an estimator. This method can be seen as intermediate between purely stochastic Markov chain Monte Carlo iterations and deterministic relative value iterations. The second algorithm, which we call the Ratio with Tours (RT)-estimator, is a modified form of respondent-driven sampling (RDS) that accommodates the idea of regeneration.
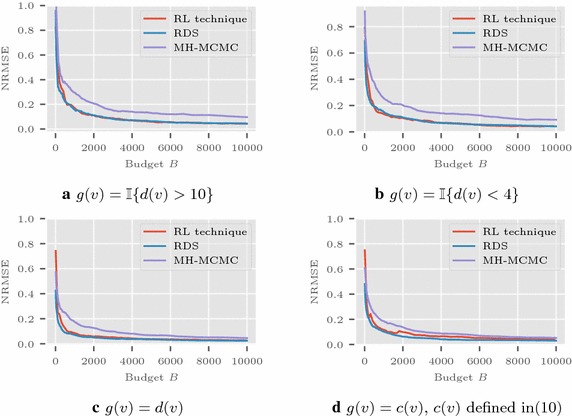
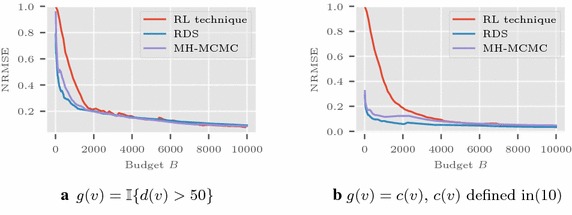
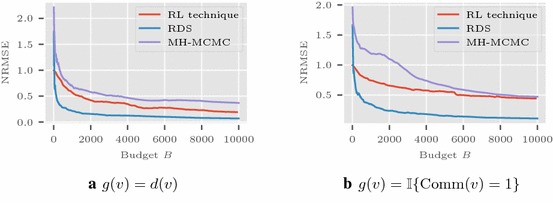
Results: We study the methods via simulations on real networks. We observe that the trajectories of RL-estimator are much more stable than those of standard random walk based estimation procedures, and its error performance is comparable to that of respondent-driven sampling (RDS) which has a smaller asymptotic variance than many other estimators. Simulation studies also show that the mean squared error of RT-estimator decays much faster than that of RDS with time.
Conclusion: The newly developed RW based estimators (RL- and RT-estimators) allow to avoid burn-in period, provide better control of stability along the sample path, and overall reduce the estimation time. Our estimators can be applied in social and complex networks.
期刊介绍:
Computational Social Networks showcases refereed papers dealing with all mathematical, computational and applied aspects of social computing. The objective of this journal is to advance and promote the theoretical foundation, mathematical aspects, and applications of social computing. Submissions are welcome which focus on common principles, algorithms and tools that govern network structures/topologies, network functionalities, security and privacy, network behaviors, information diffusions and influence, social recommendation systems which are applicable to all types of social networks and social media. Topics include (but are not limited to) the following: -Social network design and architecture -Mathematical modeling and analysis -Real-world complex networks -Information retrieval in social contexts, political analysts -Network structure analysis -Network dynamics optimization -Complex network robustness and vulnerability -Information diffusion models and analysis -Security and privacy -Searching in complex networks -Efficient algorithms -Network behaviors -Trust and reputation -Social Influence -Social Recommendation -Social media analysis -Big data analysis on online social networks This journal publishes rigorously refereed papers dealing with all mathematical, computational and applied aspects of social computing. The journal also includes reviews of appropriate books as special issues on hot topics.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


