{"title":"高通量分析时代:我们准备好迎接数据大战了吗?","authors":"Valeria D'Argenio","doi":"10.3390/ht7010008","DOIUrl":null,"url":null,"abstract":"<p><p>Recent and rapid technological advances in molecular sciences have dramatically increased the ability to carry out high-throughput studies characterized by big data production. This, in turn, led to the consequent negative effect of highlighting the presence of a gap between data yield and their analysis. Indeed, big data management is becoming an increasingly important aspect of many fields of molecular research including the study of human diseases. Now, the challenge is to identify, within the huge amount of data obtained, that which is of clinical relevance. In this context, issues related to data interpretation, sharing and storage need to be assessed and standardized. Once this is achieved, the integration of data from different -omic approaches will improve the diagnosis, monitoring and therapy of diseases by allowing the identification of novel, potentially actionably biomarkers in view of personalized medicine.</p>","PeriodicalId":53433,"journal":{"name":"High-Throughput","volume":"7 1","pages":""},"PeriodicalIF":0.0000,"publicationDate":"2018-03-02","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.3390/ht7010008","citationCount":"45","resultStr":"{\"title\":\"The High-Throughput Analyses Era: Are We Ready for the Data Struggle?\",\"authors\":\"Valeria D'Argenio\",\"doi\":\"10.3390/ht7010008\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Recent and rapid technological advances in molecular sciences have dramatically increased the ability to carry out high-throughput studies characterized by big data production. This, in turn, led to the consequent negative effect of highlighting the presence of a gap between data yield and their analysis. Indeed, big data management is becoming an increasingly important aspect of many fields of molecular research including the study of human diseases. Now, the challenge is to identify, within the huge amount of data obtained, that which is of clinical relevance. In this context, issues related to data interpretation, sharing and storage need to be assessed and standardized. Once this is achieved, the integration of data from different -omic approaches will improve the diagnosis, monitoring and therapy of diseases by allowing the identification of novel, potentially actionably biomarkers in view of personalized medicine.</p>\",\"PeriodicalId\":53433,\"journal\":{\"name\":\"High-Throughput\",\"volume\":\"7 1\",\"pages\":\"\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2018-03-02\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.3390/ht7010008\",\"citationCount\":\"45\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"High-Throughput\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.3390/ht7010008\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Biochemistry, Genetics and Molecular Biology\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"High-Throughput","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.3390/ht7010008","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Biochemistry, Genetics and Molecular Biology","Score":null,"Total":0}
The High-Throughput Analyses Era: Are We Ready for the Data Struggle?
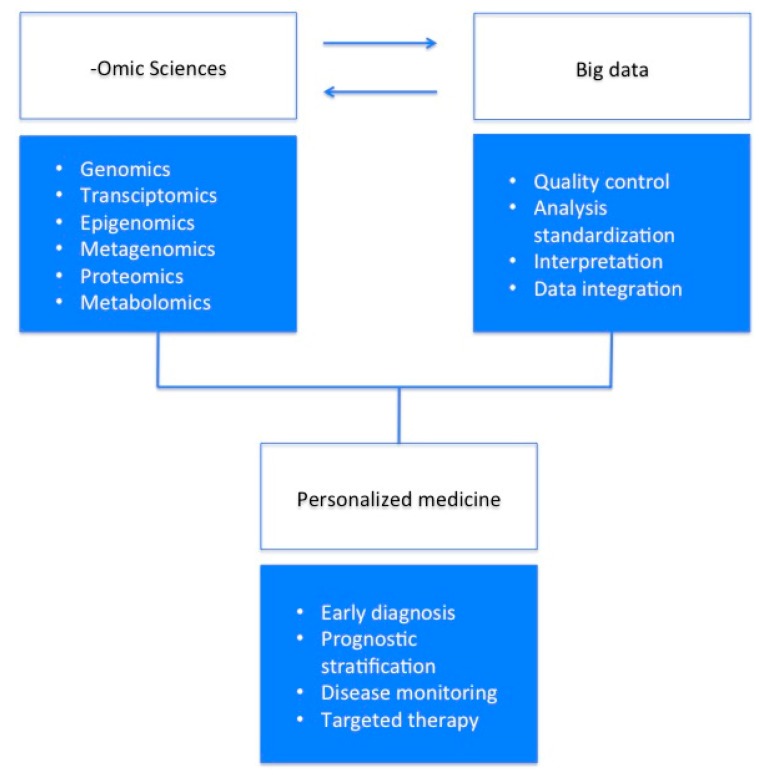
Recent and rapid technological advances in molecular sciences have dramatically increased the ability to carry out high-throughput studies characterized by big data production. This, in turn, led to the consequent negative effect of highlighting the presence of a gap between data yield and their analysis. Indeed, big data management is becoming an increasingly important aspect of many fields of molecular research including the study of human diseases. Now, the challenge is to identify, within the huge amount of data obtained, that which is of clinical relevance. In this context, issues related to data interpretation, sharing and storage need to be assessed and standardized. Once this is achieved, the integration of data from different -omic approaches will improve the diagnosis, monitoring and therapy of diseases by allowing the identification of novel, potentially actionably biomarkers in view of personalized medicine.
High-ThroughputBiochemistry, Genetics and Molecular Biology-Biotechnology
CiteScore
3.60
自引率
0.00%
发文量
0
审稿时长
9 weeks
期刊介绍:
High-Throughput (formerly Microarrays, ISSN 2076-3905) is a multidisciplinary peer-reviewed scientific journal that provides an advanced forum for the publication of studies reporting high-dimensional approaches and developments in Life Sciences, Chemistry and related fields. Our aim is to encourage scientists to publish their experimental and theoretical results based on high-throughput techniques as well as computational and statistical tools for data analysis and interpretation. The full experimental or methodological details must be provided so that the results can be reproduced. There is no restriction on the length of the papers. High-Throughput invites submissions covering several topics, including, but not limited to: -Microarrays -DNA Sequencing -RNA Sequencing -Protein Identification and Quantification -Cell-based Approaches -Omics Technologies -Imaging -Bioinformatics -Computational Biology/Chemistry -Statistics -Integrative Omics -Drug Discovery and Development -Microfluidics -Lab-on-a-chip -Data Mining -Databases -Multiplex Assays

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


