{"title":"2012年NAMCS医师工作流程邮件调查中不同缺失数据部分的缺失信息比例(γ)","authors":"Qiyuan Pan, Rong Wei","doi":"10.4236/am.2016.710093","DOIUrl":null,"url":null,"abstract":"<p><p>In his 1987 classic book on multiple imputation (MI), Rubin used the fraction of missing information, <i>γ</i>, to define the relative efficiency (RE) of MI as RE = (1 + <i>γ</i>/<i>m</i>)<sup>-1/2</sup>, where <i>m</i> is the number of imputations, leading to the conclusion that a small <i>m</i> (≤5) would be sufficient for MI. However, evidence has been accumulating that many more imputations are needed. Why would the apparently sufficient <i>m</i> deduced from the RE be actually too small? The answer may lie with <i>γ</i>. In this research, <i>γ</i> was determined at the fractions of missing data (<i>δ</i>) of 4%, 10%, 20%, and 29% using the 2012 Physician Workflow Mail Survey of the National Ambulatory Medical Care Survey (NAMCS). The <i>γ</i> values were strikingly small, ranging in the order of 10<sup>-6</sup> to 0.01. As <i>δ</i> increased, <i>γ</i> usually increased but sometimes decreased. How the data were analysed had the dominating effects on <i>γ</i>, overshadowing the effect of <i>δ</i>. The results suggest that it is impossible to predict <i>γ</i> using <i>δ</i> and that it may not be appropriate to use the <i>γ</i>-based RE to determine sufficient <i>m</i>.</p>","PeriodicalId":64940,"journal":{"name":"应用数学(英文)","volume":"7 10","pages":"1057-1067"},"PeriodicalIF":0.0000,"publicationDate":"2016-06-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4934387/pdf/","citationCount":"0","resultStr":"{\"title\":\"Fraction of Missing Information (<i>γ</i>) at Different Missing Data Fractions in the 2012 NAMCS Physician Workflow Mail Survey.\",\"authors\":\"Qiyuan Pan, Rong Wei\",\"doi\":\"10.4236/am.2016.710093\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>In his 1987 classic book on multiple imputation (MI), Rubin used the fraction of missing information, <i>γ</i>, to define the relative efficiency (RE) of MI as RE = (1 + <i>γ</i>/<i>m</i>)<sup>-1/2</sup>, where <i>m</i> is the number of imputations, leading to the conclusion that a small <i>m</i> (≤5) would be sufficient for MI. However, evidence has been accumulating that many more imputations are needed. Why would the apparently sufficient <i>m</i> deduced from the RE be actually too small? The answer may lie with <i>γ</i>. In this research, <i>γ</i> was determined at the fractions of missing data (<i>δ</i>) of 4%, 10%, 20%, and 29% using the 2012 Physician Workflow Mail Survey of the National Ambulatory Medical Care Survey (NAMCS). The <i>γ</i> values were strikingly small, ranging in the order of 10<sup>-6</sup> to 0.01. As <i>δ</i> increased, <i>γ</i> usually increased but sometimes decreased. How the data were analysed had the dominating effects on <i>γ</i>, overshadowing the effect of <i>δ</i>. The results suggest that it is impossible to predict <i>γ</i> using <i>δ</i> and that it may not be appropriate to use the <i>γ</i>-based RE to determine sufficient <i>m</i>.</p>\",\"PeriodicalId\":64940,\"journal\":{\"name\":\"应用数学(英文)\",\"volume\":\"7 10\",\"pages\":\"1057-1067\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2016-06-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4934387/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"应用数学(英文)\",\"FirstCategoryId\":\"1089\",\"ListUrlMain\":\"https://doi.org/10.4236/am.2016.710093\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2016/6/15 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"应用数学(英文)","FirstCategoryId":"1089","ListUrlMain":"https://doi.org/10.4236/am.2016.710093","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2016/6/15 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
Fraction of Missing Information (γ) at Different Missing Data Fractions in the 2012 NAMCS Physician Workflow Mail Survey.
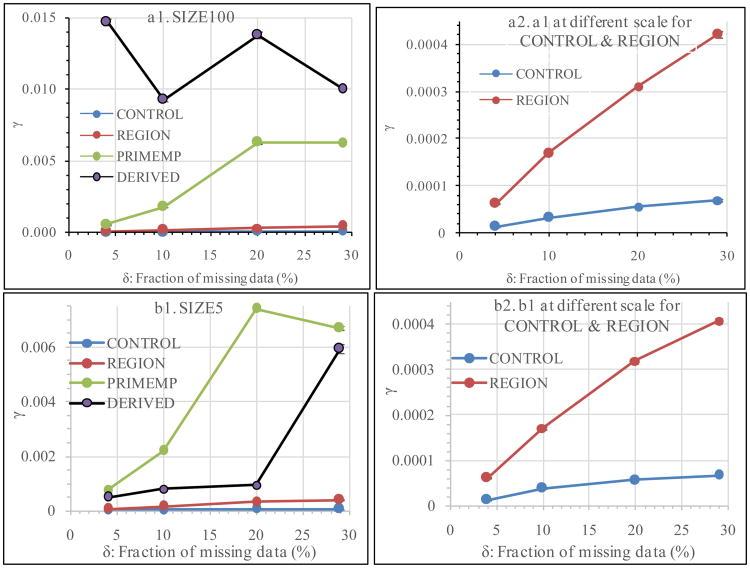
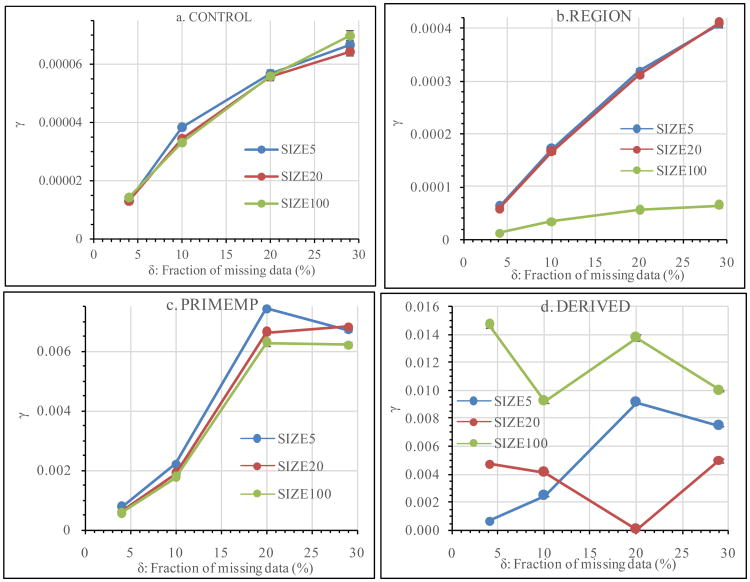
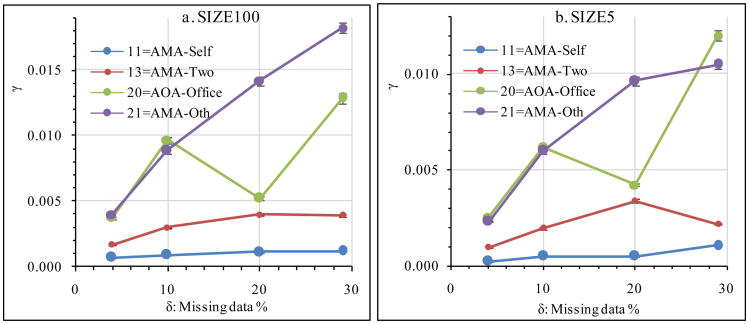
In his 1987 classic book on multiple imputation (MI), Rubin used the fraction of missing information, γ, to define the relative efficiency (RE) of MI as RE = (1 + γ/m)-1/2, where m is the number of imputations, leading to the conclusion that a small m (≤5) would be sufficient for MI. However, evidence has been accumulating that many more imputations are needed. Why would the apparently sufficient m deduced from the RE be actually too small? The answer may lie with γ. In this research, γ was determined at the fractions of missing data (δ) of 4%, 10%, 20%, and 29% using the 2012 Physician Workflow Mail Survey of the National Ambulatory Medical Care Survey (NAMCS). The γ values were strikingly small, ranging in the order of 10-6 to 0.01. As δ increased, γ usually increased but sometimes decreased. How the data were analysed had the dominating effects on γ, overshadowing the effect of δ. The results suggest that it is impossible to predict γ using δ and that it may not be appropriate to use the γ-based RE to determine sufficient m.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


