Ahmed Izzidien, Stephen Fitz, Peter Romero, Bao S Loe, David Stillwell
{"title":"利用词嵌入开发句子级公平度量。","authors":"Ahmed Izzidien, Stephen Fitz, Peter Romero, Bao S Loe, David Stillwell","doi":"10.1007/s42803-022-00049-4","DOIUrl":null,"url":null,"abstract":"<p><p>Fairness is a principal social value that is observable in civilisations around the world. Yet, a fairness metric for digital texts that describe even a simple social interaction, e.g., 'The boy hurt the girl' has not been developed. We address this by employing word embeddings that use factors found in a new social psychology literature review on the topic. We use these factors to build fairness vectors. These vectors are used as sentence level measures, whereby each dimension reflects a fairness component. The approach is employed to approximate human perceptions of fairness. The method leverages a pro-social bias within word embeddings, for which we obtain an F1 = 79.8 on a list of sentences using the Universal Sentence Encoder (USE). A second approach, using principal component analysis (PCA) and machine learning (ML), produces an F1 = 86.2. Repeating these tests using Sentence Bidirectional Encoder Representations from Transformers (SBERT) produces an F1 = 96.9 and F1 = 100 respectively. Improvements using subspace representations are further suggested. By proposing a first-principles approach, the paper contributes to the analysis of digital texts along an ethical dimension.</p>","PeriodicalId":91018,"journal":{"name":"International journal of digital humanities","volume":" ","pages":"1-36"},"PeriodicalIF":0.0000,"publicationDate":"2022-10-10","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9549858/pdf/","citationCount":"0","resultStr":"{\"title\":\"Developing a sentence level fairness metric using word embeddings.\",\"authors\":\"Ahmed Izzidien, Stephen Fitz, Peter Romero, Bao S Loe, David Stillwell\",\"doi\":\"10.1007/s42803-022-00049-4\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Fairness is a principal social value that is observable in civilisations around the world. Yet, a fairness metric for digital texts that describe even a simple social interaction, e.g., 'The boy hurt the girl' has not been developed. We address this by employing word embeddings that use factors found in a new social psychology literature review on the topic. We use these factors to build fairness vectors. These vectors are used as sentence level measures, whereby each dimension reflects a fairness component. The approach is employed to approximate human perceptions of fairness. The method leverages a pro-social bias within word embeddings, for which we obtain an F1 = 79.8 on a list of sentences using the Universal Sentence Encoder (USE). A second approach, using principal component analysis (PCA) and machine learning (ML), produces an F1 = 86.2. Repeating these tests using Sentence Bidirectional Encoder Representations from Transformers (SBERT) produces an F1 = 96.9 and F1 = 100 respectively. Improvements using subspace representations are further suggested. By proposing a first-principles approach, the paper contributes to the analysis of digital texts along an ethical dimension.</p>\",\"PeriodicalId\":91018,\"journal\":{\"name\":\"International journal of digital humanities\",\"volume\":\" \",\"pages\":\"1-36\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2022-10-10\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9549858/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"International journal of digital humanities\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1007/s42803-022-00049-4\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"International journal of digital humanities","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1007/s42803-022-00049-4","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
引用次数: 0
摘要
公平是一种主要的社会价值观,在世界各地的文明中都可以看到。然而,即使是描述简单社会互动(如 "男孩伤害了女孩")的数字文本,也尚未开发出公平度量标准。为了解决这个问题,我们采用了词嵌入技术,使用了在有关该主题的最新社会心理学文献综述中发现的因素。我们利用这些因素来构建公平性向量。这些向量被用作句子级别的衡量标准,其中每个维度都反映了公平性的组成部分。该方法可用于近似人类对公平性的感知。该方法利用了词嵌入中的亲社会偏差,我们在使用通用句子编码器(USE)的句子列表中获得了 F1 = 79.8 的结果。第二种方法使用主成分分析(PCA)和机器学习(ML),得出的 F1 = 86.2。使用来自变换器的句子双向编码器表示法(SBERT)重复这些测试,F1 = 96.9,F1 = 100。我们还提出了使用子空间表示法进行改进的建议。通过提出第一原理方法,本文为从伦理维度分析数字文本做出了贡献。
Developing a sentence level fairness metric using word embeddings.
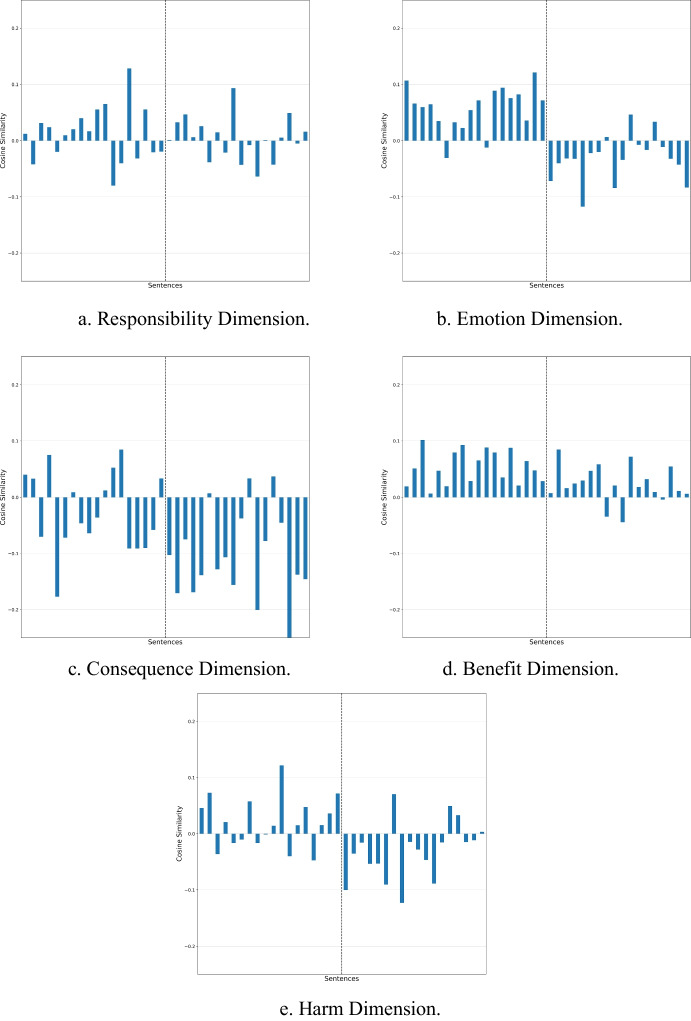
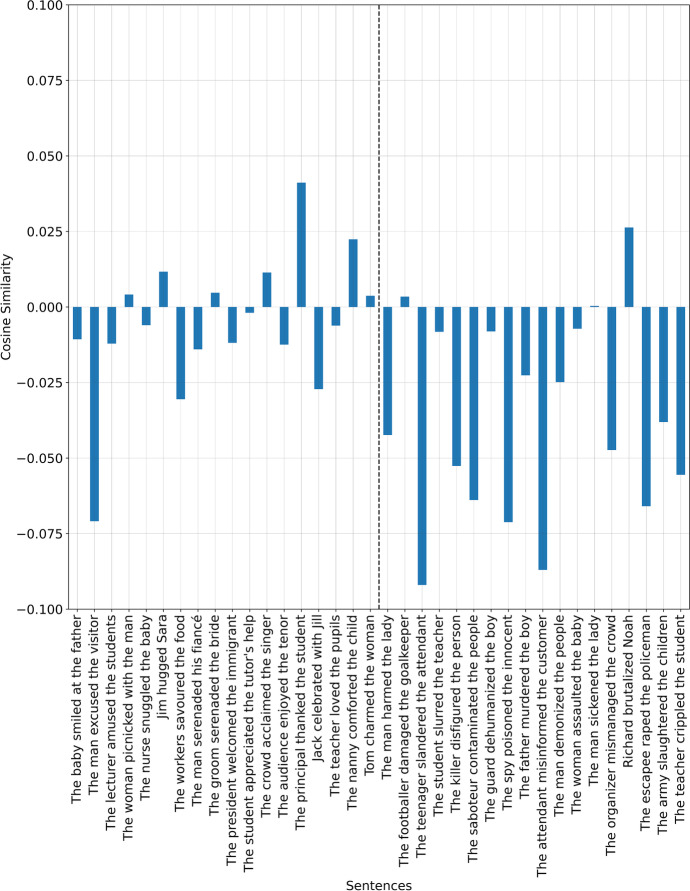
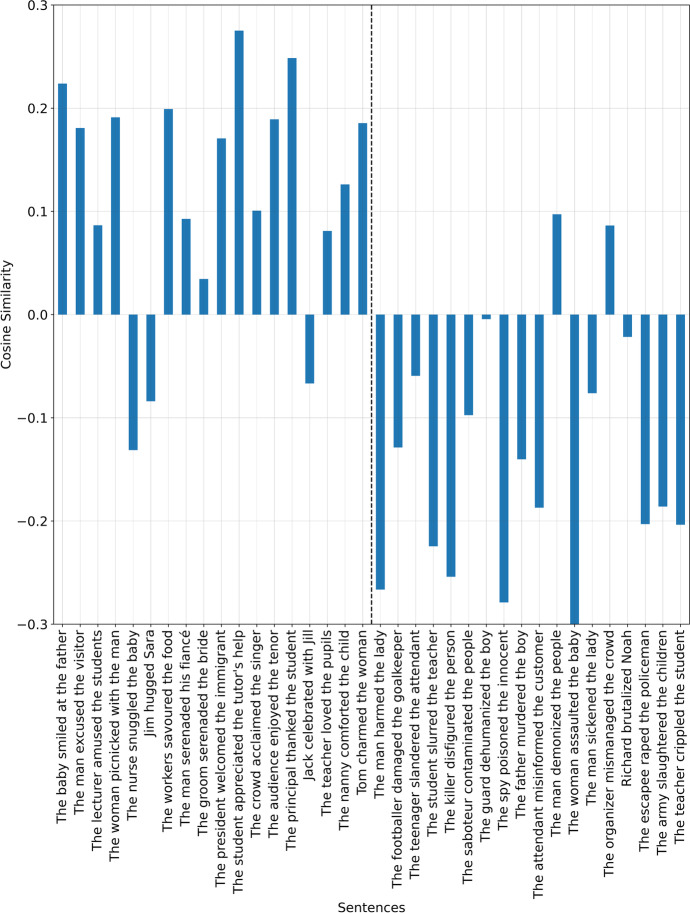
Fairness is a principal social value that is observable in civilisations around the world. Yet, a fairness metric for digital texts that describe even a simple social interaction, e.g., 'The boy hurt the girl' has not been developed. We address this by employing word embeddings that use factors found in a new social psychology literature review on the topic. We use these factors to build fairness vectors. These vectors are used as sentence level measures, whereby each dimension reflects a fairness component. The approach is employed to approximate human perceptions of fairness. The method leverages a pro-social bias within word embeddings, for which we obtain an F1 = 79.8 on a list of sentences using the Universal Sentence Encoder (USE). A second approach, using principal component analysis (PCA) and machine learning (ML), produces an F1 = 86.2. Repeating these tests using Sentence Bidirectional Encoder Representations from Transformers (SBERT) produces an F1 = 96.9 and F1 = 100 respectively. Improvements using subspace representations are further suggested. By proposing a first-principles approach, the paper contributes to the analysis of digital texts along an ethical dimension.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


