Kevin Zhan, Yutong Li, Rafay Osmani, Xiaoyu Wang, Bo Cao
{"title":"新闻文章可靠性的数据挖掘与分类:深度学习研究。","authors":"Kevin Zhan, Yutong Li, Rafay Osmani, Xiaoyu Wang, Bo Cao","doi":"10.2196/38839","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>During the ongoing COVID-19 pandemic, we are being exposed to large amounts of information each day. This \"infodemic\" is defined by the World Health Organization as the mass spread of misleading or false information during a pandemic. This spread of misinformation during the infodemic ultimately leads to misunderstandings of public health orders or direct opposition against public policies. Although there have been efforts to combat misinformation spread, current manual fact-checking methods are insufficient to combat the infodemic.</p><p><strong>Objective: </strong>We propose the use of natural language processing (NLP) and machine learning (ML) techniques to build a model that can be used to identify unreliable news articles online.</p><p><strong>Methods: </strong>First, we preprocessed the ReCOVery data set to obtain 2029 English news articles tagged with COVID-19 keywords from January to May 2020, which are labeled as reliable or unreliable. Data exploration was conducted to determine major differences between reliable and unreliable articles. We built an ensemble deep learning model using the body text, as well as features, such as sentiment, Empath-derived lexical categories, and readability, to classify the reliability.</p><p><strong>Results: </strong>We found that reliable news articles have a higher proportion of neutral sentiment, while unreliable articles have a higher proportion of negative sentiment. Additionally, our analysis demonstrated that reliable articles are easier to read than unreliable articles, in addition to having different lexical categories and keywords. Our new model was evaluated to achieve the following performance metrics: 0.906 area under the curve (AUC), 0.835 specificity, and 0.945 sensitivity. These values are above the baseline performance of the original ReCOVery model.</p><p><strong>Conclusions: </strong>This paper identified novel differences between reliable and unreliable news articles; moreover, the model was trained using state-of-the-art deep learning techniques. We aim to be able to use our findings to help researchers and the public audience more easily identify false information and unreliable media in their everyday lives.</p>","PeriodicalId":73554,"journal":{"name":"JMIR infodemiology","volume":null,"pages":null},"PeriodicalIF":3.5000,"publicationDate":"2022-09-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9516811/pdf/","citationCount":"0","resultStr":"{\"title\":\"Data Exploration and Classification of News Article Reliability: Deep Learning Study.\",\"authors\":\"Kevin Zhan, Yutong Li, Rafay Osmani, Xiaoyu Wang, Bo Cao\",\"doi\":\"10.2196/38839\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>During the ongoing COVID-19 pandemic, we are being exposed to large amounts of information each day. This \\\"infodemic\\\" is defined by the World Health Organization as the mass spread of misleading or false information during a pandemic. This spread of misinformation during the infodemic ultimately leads to misunderstandings of public health orders or direct opposition against public policies. Although there have been efforts to combat misinformation spread, current manual fact-checking methods are insufficient to combat the infodemic.</p><p><strong>Objective: </strong>We propose the use of natural language processing (NLP) and machine learning (ML) techniques to build a model that can be used to identify unreliable news articles online.</p><p><strong>Methods: </strong>First, we preprocessed the ReCOVery data set to obtain 2029 English news articles tagged with COVID-19 keywords from January to May 2020, which are labeled as reliable or unreliable. Data exploration was conducted to determine major differences between reliable and unreliable articles. We built an ensemble deep learning model using the body text, as well as features, such as sentiment, Empath-derived lexical categories, and readability, to classify the reliability.</p><p><strong>Results: </strong>We found that reliable news articles have a higher proportion of neutral sentiment, while unreliable articles have a higher proportion of negative sentiment. Additionally, our analysis demonstrated that reliable articles are easier to read than unreliable articles, in addition to having different lexical categories and keywords. Our new model was evaluated to achieve the following performance metrics: 0.906 area under the curve (AUC), 0.835 specificity, and 0.945 sensitivity. These values are above the baseline performance of the original ReCOVery model.</p><p><strong>Conclusions: </strong>This paper identified novel differences between reliable and unreliable news articles; moreover, the model was trained using state-of-the-art deep learning techniques. We aim to be able to use our findings to help researchers and the public audience more easily identify false information and unreliable media in their everyday lives.</p>\",\"PeriodicalId\":73554,\"journal\":{\"name\":\"JMIR infodemiology\",\"volume\":null,\"pages\":null},\"PeriodicalIF\":3.5000,\"publicationDate\":\"2022-09-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC9516811/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"JMIR infodemiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.2196/38839\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2022/7/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q1\",\"JCRName\":\"HEALTH CARE SCIENCES & SERVICES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"JMIR infodemiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.2196/38839","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2022/7/1 0:00:00","PubModel":"eCollection","JCR":"Q1","JCRName":"HEALTH CARE SCIENCES & SERVICES","Score":null,"Total":0}
Data Exploration and Classification of News Article Reliability: Deep Learning Study.
Background: During the ongoing COVID-19 pandemic, we are being exposed to large amounts of information each day. This "infodemic" is defined by the World Health Organization as the mass spread of misleading or false information during a pandemic. This spread of misinformation during the infodemic ultimately leads to misunderstandings of public health orders or direct opposition against public policies. Although there have been efforts to combat misinformation spread, current manual fact-checking methods are insufficient to combat the infodemic.
Objective: We propose the use of natural language processing (NLP) and machine learning (ML) techniques to build a model that can be used to identify unreliable news articles online.
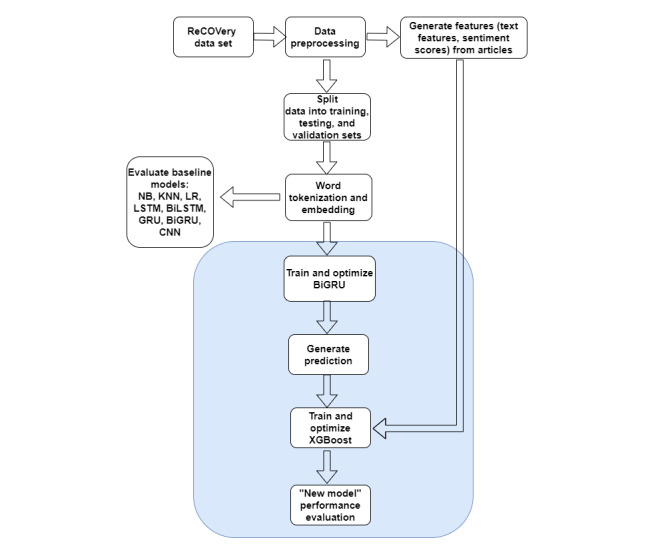
Methods: First, we preprocessed the ReCOVery data set to obtain 2029 English news articles tagged with COVID-19 keywords from January to May 2020, which are labeled as reliable or unreliable. Data exploration was conducted to determine major differences between reliable and unreliable articles. We built an ensemble deep learning model using the body text, as well as features, such as sentiment, Empath-derived lexical categories, and readability, to classify the reliability.
Results: We found that reliable news articles have a higher proportion of neutral sentiment, while unreliable articles have a higher proportion of negative sentiment. Additionally, our analysis demonstrated that reliable articles are easier to read than unreliable articles, in addition to having different lexical categories and keywords. Our new model was evaluated to achieve the following performance metrics: 0.906 area under the curve (AUC), 0.835 specificity, and 0.945 sensitivity. These values are above the baseline performance of the original ReCOVery model.
Conclusions: This paper identified novel differences between reliable and unreliable news articles; moreover, the model was trained using state-of-the-art deep learning techniques. We aim to be able to use our findings to help researchers and the public audience more easily identify false information and unreliable media in their everyday lives.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


