{"title":"什么是时间精细结构,为什么它很重要?","authors":"Il Joon Moon, Sung Hwa Hong","doi":"10.7874/kja.2014.18.1.1","DOIUrl":null,"url":null,"abstract":"<p><p>Complex sound like speech can be characterized as the sum of number of amplitude-modulated signals representing the outputs of an array of narrow frequency bands. Temporal information at the output of each band can be separated into temporal fine structure (TFS), the rapid oscillations close to the center frequency and temporal envelope (ENV), slower amplitude modulations superimposed on the TFS. TFS information can be carried in the pattern of phase locking to the stimulus waveform, while ENV by the changes in firing rate over time. The relative importance of temporal ENV and TFS information in understanding speech has been studied using various sound-processing techniques. A number of studies demonstrated that ENV cues are associated with speech recognition in quiet, while TFS cues are possibly linked to melody/pitch perception and listening to speech in a competing background. However, there are evidences that recovered ENV from TFS as well as TFS itself may be partially responsible for speech recognition. Current technologies used in cochlear implants (CI) are not efficient in delivering the TFS cues, and new attempts have been made to deliver TFS information into sound-processing strategy in CI. We herein discuss the current updated findings of TFS with a literature review. </p>","PeriodicalId":90252,"journal":{"name":"Korean journal of audiology","volume":"18 1","pages":"1-7"},"PeriodicalIF":0.0000,"publicationDate":"2014-04-01","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.7874/kja.2014.18.1.1","citationCount":"41","resultStr":"{\"title\":\"What is temporal fine structure and why is it important?\",\"authors\":\"Il Joon Moon, Sung Hwa Hong\",\"doi\":\"10.7874/kja.2014.18.1.1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Complex sound like speech can be characterized as the sum of number of amplitude-modulated signals representing the outputs of an array of narrow frequency bands. Temporal information at the output of each band can be separated into temporal fine structure (TFS), the rapid oscillations close to the center frequency and temporal envelope (ENV), slower amplitude modulations superimposed on the TFS. TFS information can be carried in the pattern of phase locking to the stimulus waveform, while ENV by the changes in firing rate over time. The relative importance of temporal ENV and TFS information in understanding speech has been studied using various sound-processing techniques. A number of studies demonstrated that ENV cues are associated with speech recognition in quiet, while TFS cues are possibly linked to melody/pitch perception and listening to speech in a competing background. However, there are evidences that recovered ENV from TFS as well as TFS itself may be partially responsible for speech recognition. Current technologies used in cochlear implants (CI) are not efficient in delivering the TFS cues, and new attempts have been made to deliver TFS information into sound-processing strategy in CI. We herein discuss the current updated findings of TFS with a literature review. </p>\",\"PeriodicalId\":90252,\"journal\":{\"name\":\"Korean journal of audiology\",\"volume\":\"18 1\",\"pages\":\"1-7\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2014-04-01\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.7874/kja.2014.18.1.1\",\"citationCount\":\"41\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Korean journal of audiology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.7874/kja.2014.18.1.1\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2014/4/14 0:00:00\",\"PubModel\":\"Epub\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Korean journal of audiology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.7874/kja.2014.18.1.1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2014/4/14 0:00:00","PubModel":"Epub","JCR":"","JCRName":"","Score":null,"Total":0}
What is temporal fine structure and why is it important?
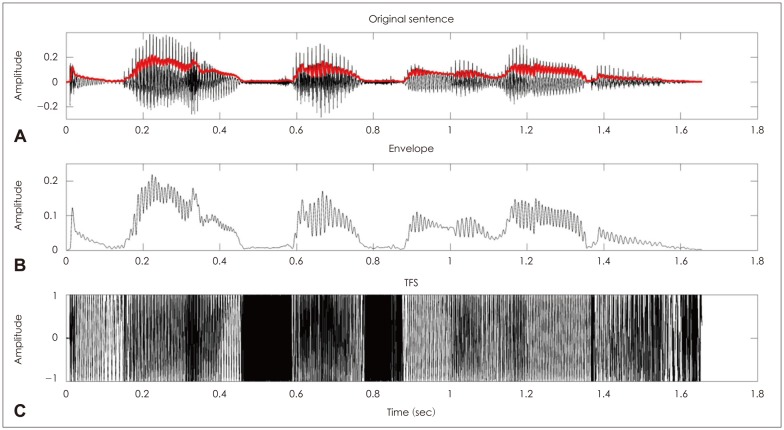
Complex sound like speech can be characterized as the sum of number of amplitude-modulated signals representing the outputs of an array of narrow frequency bands. Temporal information at the output of each band can be separated into temporal fine structure (TFS), the rapid oscillations close to the center frequency and temporal envelope (ENV), slower amplitude modulations superimposed on the TFS. TFS information can be carried in the pattern of phase locking to the stimulus waveform, while ENV by the changes in firing rate over time. The relative importance of temporal ENV and TFS information in understanding speech has been studied using various sound-processing techniques. A number of studies demonstrated that ENV cues are associated with speech recognition in quiet, while TFS cues are possibly linked to melody/pitch perception and listening to speech in a competing background. However, there are evidences that recovered ENV from TFS as well as TFS itself may be partially responsible for speech recognition. Current technologies used in cochlear implants (CI) are not efficient in delivering the TFS cues, and new attempts have been made to deliver TFS information into sound-processing strategy in CI. We herein discuss the current updated findings of TFS with a literature review.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


