Mindy K Ross, Ko-Wei Lin, Karen Truong, Abhishek Kumar, Mike Conway
{"title":"利用n-图和元数据特征在基因型和表型数据库(dbGaP)中对心脏、肺和血液研究的文本分类。","authors":"Mindy K Ross, Ko-Wei Lin, Karen Truong, Abhishek Kumar, Mike Conway","doi":"10.4137/BII.S11987","DOIUrl":null,"url":null,"abstract":"<p><p>The database of Genotypes and Phenotypes (dbGaP) allows researchers to understand phenotypic contribution to genetic conditions, generate new hypotheses, confirm previous study results, and identify control populations. However, effective use of the database is hindered by suboptimal study retrieval. Our objective is to evaluate text classification techniques to improve study retrieval in the context of the dbGaP database. We utilized standard machine learning algorithms (naive Bayes, support vector machines, and the C4.5 decision tree) trained on dbGaP study text and incorporated n-gram features and study metadata to identify heart, lung, and blood studies. We used the χ(2) feature selection algorithm to identify features that contributed most to classification performance and experimented with dbGaP associated PubMed papers as a proxy for topicality. Classifier performance was favorable in comparison to keyword-based search results. It was determined that text categorization is a useful complement to document retrieval techniques in the dbGaP. </p>","PeriodicalId":88397,"journal":{"name":"Biomedical informatics insights","volume":"6 ","pages":"35-45"},"PeriodicalIF":0.0000,"publicationDate":"2013-07-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4137/BII.S11987","citationCount":"5","resultStr":"{\"title\":\"Text Categorization of Heart, Lung, and Blood Studies in the Database of Genotypes and Phenotypes (dbGaP) Utilizing n-grams and Metadata Features.\",\"authors\":\"Mindy K Ross, Ko-Wei Lin, Karen Truong, Abhishek Kumar, Mike Conway\",\"doi\":\"10.4137/BII.S11987\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>The database of Genotypes and Phenotypes (dbGaP) allows researchers to understand phenotypic contribution to genetic conditions, generate new hypotheses, confirm previous study results, and identify control populations. However, effective use of the database is hindered by suboptimal study retrieval. Our objective is to evaluate text classification techniques to improve study retrieval in the context of the dbGaP database. We utilized standard machine learning algorithms (naive Bayes, support vector machines, and the C4.5 decision tree) trained on dbGaP study text and incorporated n-gram features and study metadata to identify heart, lung, and blood studies. We used the χ(2) feature selection algorithm to identify features that contributed most to classification performance and experimented with dbGaP associated PubMed papers as a proxy for topicality. Classifier performance was favorable in comparison to keyword-based search results. It was determined that text categorization is a useful complement to document retrieval techniques in the dbGaP. </p>\",\"PeriodicalId\":88397,\"journal\":{\"name\":\"Biomedical informatics insights\",\"volume\":\"6 \",\"pages\":\"35-45\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2013-07-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.4137/BII.S11987\",\"citationCount\":\"5\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biomedical informatics insights\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4137/BII.S11987\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2013/1/1 0:00:00\",\"PubModel\":\"Print\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical informatics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4137/BII.S11987","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2013/1/1 0:00:00","PubModel":"Print","JCR":"","JCRName":"","Score":null,"Total":0}
Text Categorization of Heart, Lung, and Blood Studies in the Database of Genotypes and Phenotypes (dbGaP) Utilizing n-grams and Metadata Features.
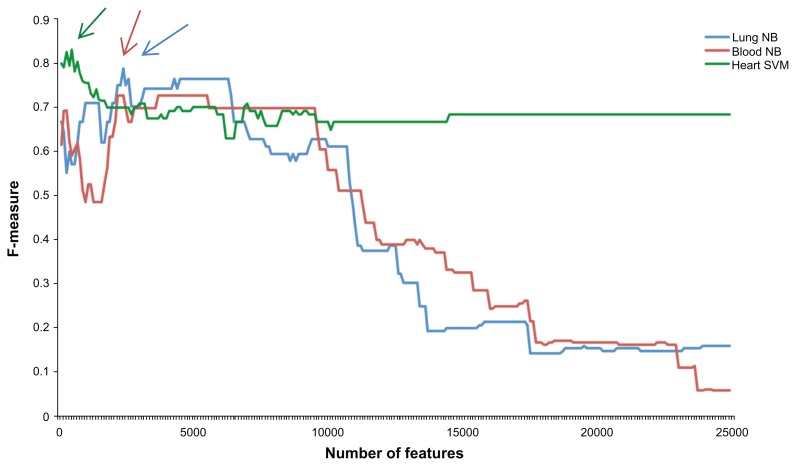
The database of Genotypes and Phenotypes (dbGaP) allows researchers to understand phenotypic contribution to genetic conditions, generate new hypotheses, confirm previous study results, and identify control populations. However, effective use of the database is hindered by suboptimal study retrieval. Our objective is to evaluate text classification techniques to improve study retrieval in the context of the dbGaP database. We utilized standard machine learning algorithms (naive Bayes, support vector machines, and the C4.5 decision tree) trained on dbGaP study text and incorporated n-gram features and study metadata to identify heart, lung, and blood studies. We used the χ(2) feature selection algorithm to identify features that contributed most to classification performance and experimented with dbGaP associated PubMed papers as a proxy for topicality. Classifier performance was favorable in comparison to keyword-based search results. It was determined that text categorization is a useful complement to document retrieval techniques in the dbGaP.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


