Siddhartha Jonnalagadda, Trevor Cohen, Stephen Wu, Hongfang Liu, Graciela Gonzalez
{"title":"使用经验构建的词汇资源进行命名实体识别。","authors":"Siddhartha Jonnalagadda, Trevor Cohen, Stephen Wu, Hongfang Liu, Graciela Gonzalez","doi":"10.4137/BII.S11664","DOIUrl":null,"url":null,"abstract":"<p><p>Because of privacy concerns and the expense involved in creating an annotated corpus, the existing small-annotated corpora might not have sufficient examples for learning to statistically extract all the named-entities precisely. In this work, we evaluate what value may lie in automatically generated features based on distributional semantics when using machine-learning named entity recognition (NER). The features we generated and experimented with include n-nearest words, support vector machine (SVM)-regions, and term clustering, all of which are considered distributional semantic features. The addition of the n-nearest words feature resulted in a greater increase in F-score than by using a manually constructed lexicon to a baseline system. Although the need for relatively small-annotated corpora for retraining is not obviated, lexicons empirically derived from unannotated text can not only supplement manually created lexicons, but also replace them. This phenomenon is observed in extracting concepts from both biomedical literature and clinical notes. </p>","PeriodicalId":88397,"journal":{"name":"Biomedical informatics insights","volume":"6 Suppl 1","pages":"17-27"},"PeriodicalIF":0.0000,"publicationDate":"2013-06-24","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4137/BII.S11664","citationCount":"16","resultStr":"{\"title\":\"Using empirically constructed lexical resources for named entity recognition.\",\"authors\":\"Siddhartha Jonnalagadda, Trevor Cohen, Stephen Wu, Hongfang Liu, Graciela Gonzalez\",\"doi\":\"10.4137/BII.S11664\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Because of privacy concerns and the expense involved in creating an annotated corpus, the existing small-annotated corpora might not have sufficient examples for learning to statistically extract all the named-entities precisely. In this work, we evaluate what value may lie in automatically generated features based on distributional semantics when using machine-learning named entity recognition (NER). The features we generated and experimented with include n-nearest words, support vector machine (SVM)-regions, and term clustering, all of which are considered distributional semantic features. The addition of the n-nearest words feature resulted in a greater increase in F-score than by using a manually constructed lexicon to a baseline system. Although the need for relatively small-annotated corpora for retraining is not obviated, lexicons empirically derived from unannotated text can not only supplement manually created lexicons, but also replace them. This phenomenon is observed in extracting concepts from both biomedical literature and clinical notes. </p>\",\"PeriodicalId\":88397,\"journal\":{\"name\":\"Biomedical informatics insights\",\"volume\":\"6 Suppl 1\",\"pages\":\"17-27\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2013-06-24\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.4137/BII.S11664\",\"citationCount\":\"16\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biomedical informatics insights\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4137/BII.S11664\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2013/1/1 0:00:00\",\"PubModel\":\"Print\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical informatics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4137/BII.S11664","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2013/1/1 0:00:00","PubModel":"Print","JCR":"","JCRName":"","Score":null,"Total":0}
Using empirically constructed lexical resources for named entity recognition.
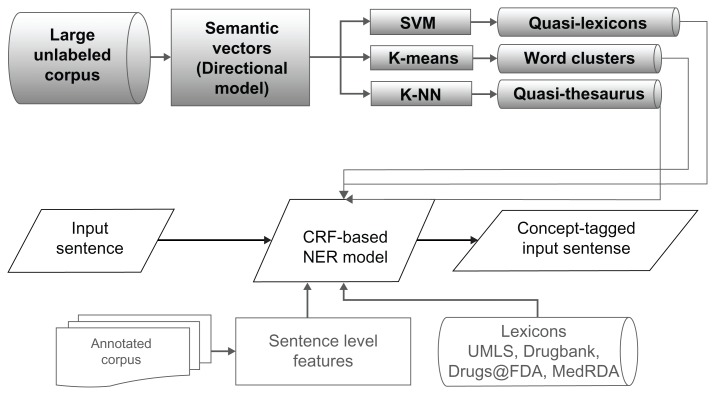
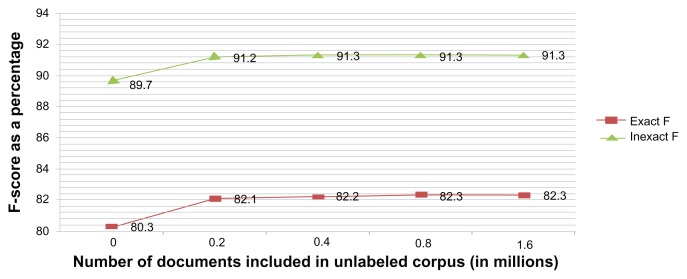
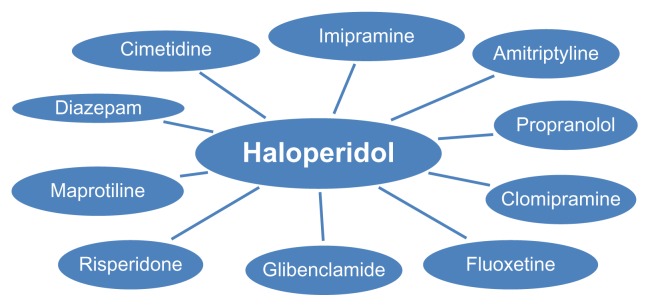
Because of privacy concerns and the expense involved in creating an annotated corpus, the existing small-annotated corpora might not have sufficient examples for learning to statistically extract all the named-entities precisely. In this work, we evaluate what value may lie in automatically generated features based on distributional semantics when using machine-learning named entity recognition (NER). The features we generated and experimented with include n-nearest words, support vector machine (SVM)-regions, and term clustering, all of which are considered distributional semantic features. The addition of the n-nearest words feature resulted in a greater increase in F-score than by using a manually constructed lexicon to a baseline system. Although the need for relatively small-annotated corpora for retraining is not obviated, lexicons empirically derived from unannotated text can not only supplement manually created lexicons, but also replace them. This phenomenon is observed in extracting concepts from both biomedical literature and clinical notes.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


