Sylvia Halász, Philip Brown, Cem Oktay, Arif Alper Cevik, Isa Kılıçaslan, Colin Goodall, Dennis G Cochrane, Thomas R Fowler, Guy Jacobson, Simon Tse, John R Allegra
{"title":"在没有英文翻译的土耳其急诊科使用n-Grams进行综合征监测:可行性研究。","authors":"Sylvia Halász, Philip Brown, Cem Oktay, Arif Alper Cevik, Isa Kılıçaslan, Colin Goodall, Dennis G Cochrane, Thomas R Fowler, Guy Jacobson, Simon Tse, John R Allegra","doi":"10.4137/BII.S11334","DOIUrl":null,"url":null,"abstract":"<p><strong>Introduction: </strong>Syndromic surveillance is designed for early detection of disease outbreaks. An important data source for syndromic surveillance is free-text chief complaints (CCs), which are generally recorded in the local language. For automated syndromic surveillance, CCs must be classified into predefined syndromic categories. The n-gram classifier is created by using text fragments to measure associations between chief complaints (CC) and a syndromic grouping of ICD codes.</p><p><strong>Objectives: </strong>The objective was to create a Turkish n-gram CC classifier for the respiratory syndrome and then compare daily volumes between the n-gram CC classifier and a respiratory ICD-10 code grouping on a test set of data.</p><p><strong>Methods: </strong>The design was a feasibility study based on retrospective cohort data. The setting was a university hospital emergency department (ED) in Turkey. Included were all ED visits in the 2002 database of this hospital. Two of the authors created a respiratory grouping of International Classification of Diseases, 10th Revision ICD-10-CM codes by consensus, chosen to be similar to a standard respiratory (RESP) grouping of ICD codes created by the Electronic Surveillance System for Early Notification of Community-based Epidemics (ESSENCE), a project of the Centers for Disease Control and Prevention. An n-gram method adapted from AT&T Labs' technologies was applied to the first 10 months of data as a training set to create a Turkish CC RESP classifier. The classifier was then tested on the subsequent 2 months of visits to generate a time series graph and determine the correlation with daily volumes measured by the CC classifier versus the RESP ICD-10 grouping.</p><p><strong>Results: </strong>The Turkish ED database contained 30,157 visits. The correlation (R (2)) of n-gram versus ICD-10 for the test set was 0.78.</p><p><strong>Conclusion: </strong>The n-gram method automatically created a CC RESP classifier of the Turkish CCs that performed similarly to the ICD-10 RESP grouping. The n-gram technique has the advantage of systematic, consistent, and rapid deployment as well as language independence.</p>","PeriodicalId":88397,"journal":{"name":"Biomedical informatics insights","volume":"6 ","pages":"29-33"},"PeriodicalIF":0.0000,"publicationDate":"2013-04-25","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.4137/BII.S11334","citationCount":"0","resultStr":"{\"title\":\"Using n-Grams for Syndromic Surveillance in a Turkish Emergency Department Without English Translation: A Feasibility Study.\",\"authors\":\"Sylvia Halász, Philip Brown, Cem Oktay, Arif Alper Cevik, Isa Kılıçaslan, Colin Goodall, Dennis G Cochrane, Thomas R Fowler, Guy Jacobson, Simon Tse, John R Allegra\",\"doi\":\"10.4137/BII.S11334\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Introduction: </strong>Syndromic surveillance is designed for early detection of disease outbreaks. An important data source for syndromic surveillance is free-text chief complaints (CCs), which are generally recorded in the local language. For automated syndromic surveillance, CCs must be classified into predefined syndromic categories. The n-gram classifier is created by using text fragments to measure associations between chief complaints (CC) and a syndromic grouping of ICD codes.</p><p><strong>Objectives: </strong>The objective was to create a Turkish n-gram CC classifier for the respiratory syndrome and then compare daily volumes between the n-gram CC classifier and a respiratory ICD-10 code grouping on a test set of data.</p><p><strong>Methods: </strong>The design was a feasibility study based on retrospective cohort data. The setting was a university hospital emergency department (ED) in Turkey. Included were all ED visits in the 2002 database of this hospital. Two of the authors created a respiratory grouping of International Classification of Diseases, 10th Revision ICD-10-CM codes by consensus, chosen to be similar to a standard respiratory (RESP) grouping of ICD codes created by the Electronic Surveillance System for Early Notification of Community-based Epidemics (ESSENCE), a project of the Centers for Disease Control and Prevention. An n-gram method adapted from AT&T Labs' technologies was applied to the first 10 months of data as a training set to create a Turkish CC RESP classifier. The classifier was then tested on the subsequent 2 months of visits to generate a time series graph and determine the correlation with daily volumes measured by the CC classifier versus the RESP ICD-10 grouping.</p><p><strong>Results: </strong>The Turkish ED database contained 30,157 visits. The correlation (R (2)) of n-gram versus ICD-10 for the test set was 0.78.</p><p><strong>Conclusion: </strong>The n-gram method automatically created a CC RESP classifier of the Turkish CCs that performed similarly to the ICD-10 RESP grouping. The n-gram technique has the advantage of systematic, consistent, and rapid deployment as well as language independence.</p>\",\"PeriodicalId\":88397,\"journal\":{\"name\":\"Biomedical informatics insights\",\"volume\":\"6 \",\"pages\":\"29-33\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2013-04-25\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.4137/BII.S11334\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Biomedical informatics insights\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.4137/BII.S11334\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2013/1/1 0:00:00\",\"PubModel\":\"Print\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Biomedical informatics insights","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.4137/BII.S11334","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2013/1/1 0:00:00","PubModel":"Print","JCR":"","JCRName":"","Score":null,"Total":0}
Using n-Grams for Syndromic Surveillance in a Turkish Emergency Department Without English Translation: A Feasibility Study.
Introduction: Syndromic surveillance is designed for early detection of disease outbreaks. An important data source for syndromic surveillance is free-text chief complaints (CCs), which are generally recorded in the local language. For automated syndromic surveillance, CCs must be classified into predefined syndromic categories. The n-gram classifier is created by using text fragments to measure associations between chief complaints (CC) and a syndromic grouping of ICD codes.
Objectives: The objective was to create a Turkish n-gram CC classifier for the respiratory syndrome and then compare daily volumes between the n-gram CC classifier and a respiratory ICD-10 code grouping on a test set of data.
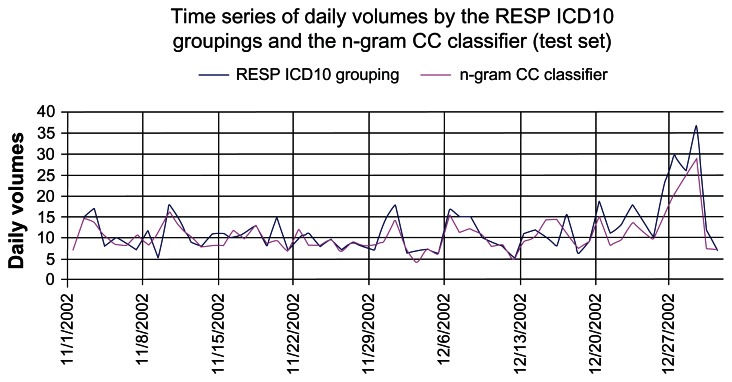
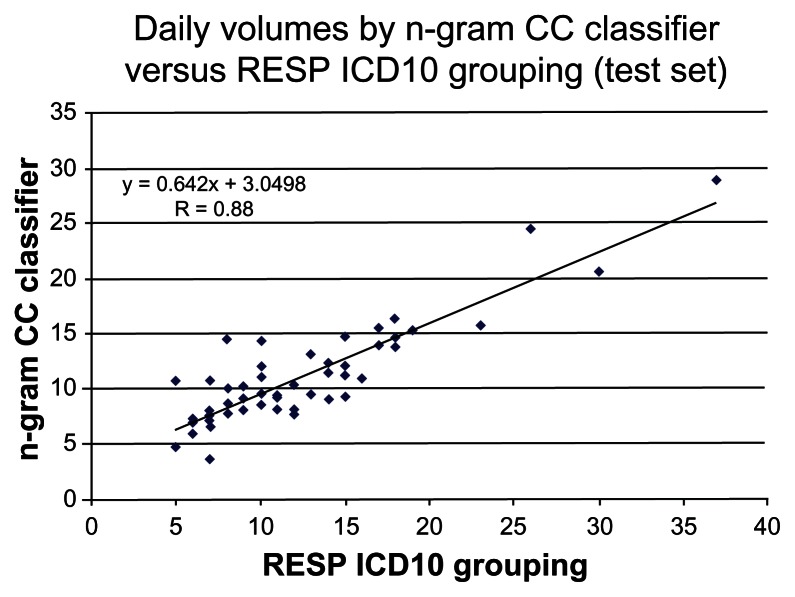
Methods: The design was a feasibility study based on retrospective cohort data. The setting was a university hospital emergency department (ED) in Turkey. Included were all ED visits in the 2002 database of this hospital. Two of the authors created a respiratory grouping of International Classification of Diseases, 10th Revision ICD-10-CM codes by consensus, chosen to be similar to a standard respiratory (RESP) grouping of ICD codes created by the Electronic Surveillance System for Early Notification of Community-based Epidemics (ESSENCE), a project of the Centers for Disease Control and Prevention. An n-gram method adapted from AT&T Labs' technologies was applied to the first 10 months of data as a training set to create a Turkish CC RESP classifier. The classifier was then tested on the subsequent 2 months of visits to generate a time series graph and determine the correlation with daily volumes measured by the CC classifier versus the RESP ICD-10 grouping.
Results: The Turkish ED database contained 30,157 visits. The correlation (R (2)) of n-gram versus ICD-10 for the test set was 0.78.
Conclusion: The n-gram method automatically created a CC RESP classifier of the Turkish CCs that performed similarly to the ICD-10 RESP grouping. The n-gram technique has the advantage of systematic, consistent, and rapid deployment as well as language independence.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


