{"title":"基于高通量化学生物学筛选数据集的分子体外抗结核活性计算模型。","authors":"Vinita Periwal, Shireesha Kishtapuram, Vinod Scaria","doi":"10.1186/1471-2210-12-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>The emergence of Multi-drug resistant tuberculosis in pandemic proportions throughout the world and the paucity of novel therapeutics for tuberculosis have re-iterated the need to accelerate the discovery of novel molecules with anti-tubercular activity. Though high-throughput screens for anti-tubercular activity are available, they are expensive, tedious and time-consuming to be performed on large scales. Thus, there remains an unmet need to prioritize the molecules that are taken up for biological screens to save on cost and time. Computational methods including Machine Learning have been widely employed to build classifiers for high-throughput virtual screens to prioritize molecules for further analysis. The availability of datasets based on high-throughput biological screens or assays in public domain makes computational methods a plausible proposition for building predictive models. In addition, this approach would save significantly on the cost, effort and time required to run high throughput screens.</p><p><strong>Results: </strong>We show that by using four supervised state-of-the-art classifiers (SMO, Random Forest, Naive Bayes and J48) we are able to generate in-silico predictive models on an extremely imbalanced (minority class ratio: 0.6%) large dataset of anti-tubercular molecules with reasonable AROC (0.6-0.75) and BCR (60-66%) values. Moreover, these models are able to provide 3-4 fold enrichment over random selection.</p><p><strong>Conclusions: </strong>In the present study, we have used the data from in-vitro screens for anti-tubercular activity from a high-throughput screen available in public domain to build highly accurate classifiers based on molecular descriptors of the molecules. We show that Machine Learning tools can be used to build highly effective predictive models for virtual high-throughput screens to prioritize molecules from large molecular libraries.</p>","PeriodicalId":48846,"journal":{"name":"BMC Pharmacology & Toxicology","volume":"12 ","pages":"1"},"PeriodicalIF":2.9000,"publicationDate":"2012-03-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1471-2210-12-1","citationCount":"34","resultStr":"{\"title\":\"Computational models for in-vitro anti-tubercular activity of molecules based on high-throughput chemical biology screening datasets.\",\"authors\":\"Vinita Periwal, Shireesha Kishtapuram, Vinod Scaria\",\"doi\":\"10.1186/1471-2210-12-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>The emergence of Multi-drug resistant tuberculosis in pandemic proportions throughout the world and the paucity of novel therapeutics for tuberculosis have re-iterated the need to accelerate the discovery of novel molecules with anti-tubercular activity. Though high-throughput screens for anti-tubercular activity are available, they are expensive, tedious and time-consuming to be performed on large scales. Thus, there remains an unmet need to prioritize the molecules that are taken up for biological screens to save on cost and time. Computational methods including Machine Learning have been widely employed to build classifiers for high-throughput virtual screens to prioritize molecules for further analysis. The availability of datasets based on high-throughput biological screens or assays in public domain makes computational methods a plausible proposition for building predictive models. In addition, this approach would save significantly on the cost, effort and time required to run high throughput screens.</p><p><strong>Results: </strong>We show that by using four supervised state-of-the-art classifiers (SMO, Random Forest, Naive Bayes and J48) we are able to generate in-silico predictive models on an extremely imbalanced (minority class ratio: 0.6%) large dataset of anti-tubercular molecules with reasonable AROC (0.6-0.75) and BCR (60-66%) values. Moreover, these models are able to provide 3-4 fold enrichment over random selection.</p><p><strong>Conclusions: </strong>In the present study, we have used the data from in-vitro screens for anti-tubercular activity from a high-throughput screen available in public domain to build highly accurate classifiers based on molecular descriptors of the molecules. We show that Machine Learning tools can be used to build highly effective predictive models for virtual high-throughput screens to prioritize molecules from large molecular libraries.</p>\",\"PeriodicalId\":48846,\"journal\":{\"name\":\"BMC Pharmacology & Toxicology\",\"volume\":\"12 \",\"pages\":\"1\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2012-03-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/1471-2210-12-1\",\"citationCount\":\"34\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"BMC Pharmacology & Toxicology\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/1471-2210-12-1\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q2\",\"JCRName\":\"Medicine\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"BMC Pharmacology & Toxicology","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1471-2210-12-1","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q2","JCRName":"Medicine","Score":null,"Total":0}
Computational models for in-vitro anti-tubercular activity of molecules based on high-throughput chemical biology screening datasets.
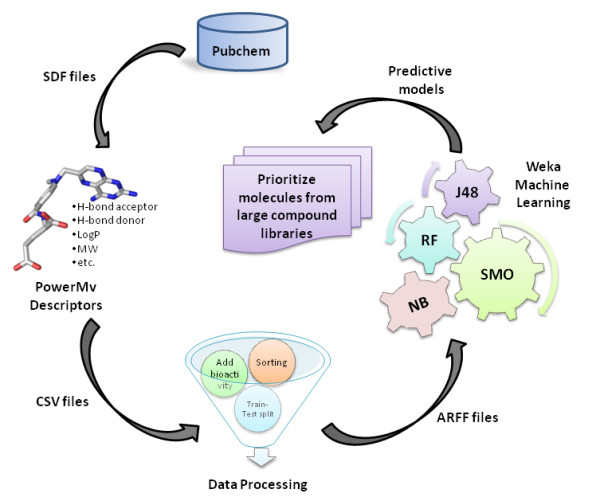
Background: The emergence of Multi-drug resistant tuberculosis in pandemic proportions throughout the world and the paucity of novel therapeutics for tuberculosis have re-iterated the need to accelerate the discovery of novel molecules with anti-tubercular activity. Though high-throughput screens for anti-tubercular activity are available, they are expensive, tedious and time-consuming to be performed on large scales. Thus, there remains an unmet need to prioritize the molecules that are taken up for biological screens to save on cost and time. Computational methods including Machine Learning have been widely employed to build classifiers for high-throughput virtual screens to prioritize molecules for further analysis. The availability of datasets based on high-throughput biological screens or assays in public domain makes computational methods a plausible proposition for building predictive models. In addition, this approach would save significantly on the cost, effort and time required to run high throughput screens.
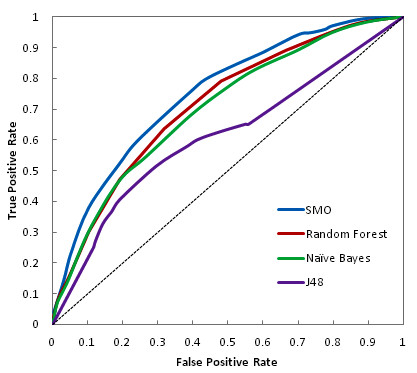
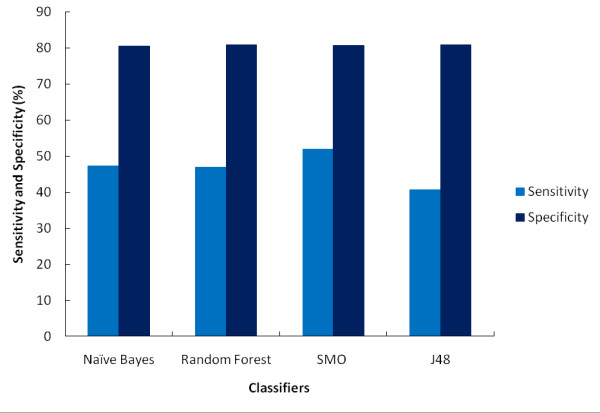
Results: We show that by using four supervised state-of-the-art classifiers (SMO, Random Forest, Naive Bayes and J48) we are able to generate in-silico predictive models on an extremely imbalanced (minority class ratio: 0.6%) large dataset of anti-tubercular molecules with reasonable AROC (0.6-0.75) and BCR (60-66%) values. Moreover, these models are able to provide 3-4 fold enrichment over random selection.
Conclusions: In the present study, we have used the data from in-vitro screens for anti-tubercular activity from a high-throughput screen available in public domain to build highly accurate classifiers based on molecular descriptors of the molecules. We show that Machine Learning tools can be used to build highly effective predictive models for virtual high-throughput screens to prioritize molecules from large molecular libraries.
期刊介绍:
BMC Pharmacology and Toxicology is an open access, peer-reviewed journal that considers articles on all aspects of chemically defined therapeutic and toxic agents. The journal welcomes submissions from all fields of experimental and clinical pharmacology including clinical trials and toxicology.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


