Marco Schorlemmer, Joaquín Abián, Carles Sierra, David de la Cruz, Lorenzo Bernacchioni, Enric Jaén, Adrian Perreau de Pinninck, Manuel Atencia
{"title":"P2P蛋白质组学——用于增强蛋白质鉴定的数据共享。","authors":"Marco Schorlemmer, Joaquín Abián, Carles Sierra, David de la Cruz, Lorenzo Bernacchioni, Enric Jaén, Adrian Perreau de Pinninck, Manuel Atencia","doi":"10.1186/1759-4499-4-1","DOIUrl":null,"url":null,"abstract":"<p><strong>Background: </strong>In order to tackle the important and challenging problem in proteomics of identifying known and new protein sequences using high-throughput methods, we propose a data-sharing platform that uses fully distributed P2P technologies to share specifications of peer-interaction protocols and service components. By using such a platform, information to be searched is no longer centralised in a few repositories but gathered from experiments in peer proteomics laboratories, which can subsequently be searched by fellow researchers.</p><p><strong>Methods: </strong>The system distributively runs a data-sharing protocol specified in the Lightweight Communication Calculus underlying the system through which researchers interact via message passing. For this, researchers interact with the system through particular components that link to database querying systems based on BLAST and/or OMSSA and GUI-based visualisation environments. We have tested the proposed platform with data drawn from preexisting MS/MS data reservoirs from the 2006 ABRF (Association of Biomolecular Resource Facilities) test sample, which was extensively tested during the ABRF Proteomics Standards Research Group 2006 worldwide survey. In particular we have taken the data available from a subset of proteomics laboratories of Spain's National Institute for Proteomics, ProteoRed, a network for the coordination, integration and development of the Spanish proteomics facilities.</p><p><strong>Results and discussion: </strong>We performed queries against nine databases including seven ProteoRed proteomics laboratories, the NCBI Swiss-Prot database and the local database of the CSIC/UAB Proteomics Laboratory. A detailed analysis of the results indicated the presence of a protein that was supported by other NCBI matches and highly scored matches in several proteomics labs. The analysis clearly indicated that the protein was a relatively high concentrated contaminant that could be present in the ABRF sample. This fact is evident from the information that could be derived from the proposed P2P proteomics system, however it is not straightforward to arrive to the same conclusion by conventional means as it is difficult to discard organic contamination of samples. The actual presence of this contaminant was only stated after the ABRF study of all the identifications reported by the laboratories.</p>","PeriodicalId":88390,"journal":{"name":"Automated experimentation","volume":"4 1","pages":"1"},"PeriodicalIF":0.0000,"publicationDate":"2012-01-31","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://sci-hub-pdf.com/10.1186/1759-4499-4-1","citationCount":"2","resultStr":"{\"title\":\"P2P proteomics -- data sharing for enhanced protein identification.\",\"authors\":\"Marco Schorlemmer, Joaquín Abián, Carles Sierra, David de la Cruz, Lorenzo Bernacchioni, Enric Jaén, Adrian Perreau de Pinninck, Manuel Atencia\",\"doi\":\"10.1186/1759-4499-4-1\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><strong>Background: </strong>In order to tackle the important and challenging problem in proteomics of identifying known and new protein sequences using high-throughput methods, we propose a data-sharing platform that uses fully distributed P2P technologies to share specifications of peer-interaction protocols and service components. By using such a platform, information to be searched is no longer centralised in a few repositories but gathered from experiments in peer proteomics laboratories, which can subsequently be searched by fellow researchers.</p><p><strong>Methods: </strong>The system distributively runs a data-sharing protocol specified in the Lightweight Communication Calculus underlying the system through which researchers interact via message passing. For this, researchers interact with the system through particular components that link to database querying systems based on BLAST and/or OMSSA and GUI-based visualisation environments. We have tested the proposed platform with data drawn from preexisting MS/MS data reservoirs from the 2006 ABRF (Association of Biomolecular Resource Facilities) test sample, which was extensively tested during the ABRF Proteomics Standards Research Group 2006 worldwide survey. In particular we have taken the data available from a subset of proteomics laboratories of Spain's National Institute for Proteomics, ProteoRed, a network for the coordination, integration and development of the Spanish proteomics facilities.</p><p><strong>Results and discussion: </strong>We performed queries against nine databases including seven ProteoRed proteomics laboratories, the NCBI Swiss-Prot database and the local database of the CSIC/UAB Proteomics Laboratory. A detailed analysis of the results indicated the presence of a protein that was supported by other NCBI matches and highly scored matches in several proteomics labs. The analysis clearly indicated that the protein was a relatively high concentrated contaminant that could be present in the ABRF sample. This fact is evident from the information that could be derived from the proposed P2P proteomics system, however it is not straightforward to arrive to the same conclusion by conventional means as it is difficult to discard organic contamination of samples. The actual presence of this contaminant was only stated after the ABRF study of all the identifications reported by the laboratories.</p>\",\"PeriodicalId\":88390,\"journal\":{\"name\":\"Automated experimentation\",\"volume\":\"4 1\",\"pages\":\"1\"},\"PeriodicalIF\":0.0000,\"publicationDate\":\"2012-01-31\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://sci-hub-pdf.com/10.1186/1759-4499-4-1\",\"citationCount\":\"2\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Automated experimentation\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1186/1759-4499-4-1\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"\",\"JCRName\":\"\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Automated experimentation","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1186/1759-4499-4-1","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"","JCRName":"","Score":null,"Total":0}
P2P proteomics -- data sharing for enhanced protein identification.
Background: In order to tackle the important and challenging problem in proteomics of identifying known and new protein sequences using high-throughput methods, we propose a data-sharing platform that uses fully distributed P2P technologies to share specifications of peer-interaction protocols and service components. By using such a platform, information to be searched is no longer centralised in a few repositories but gathered from experiments in peer proteomics laboratories, which can subsequently be searched by fellow researchers.
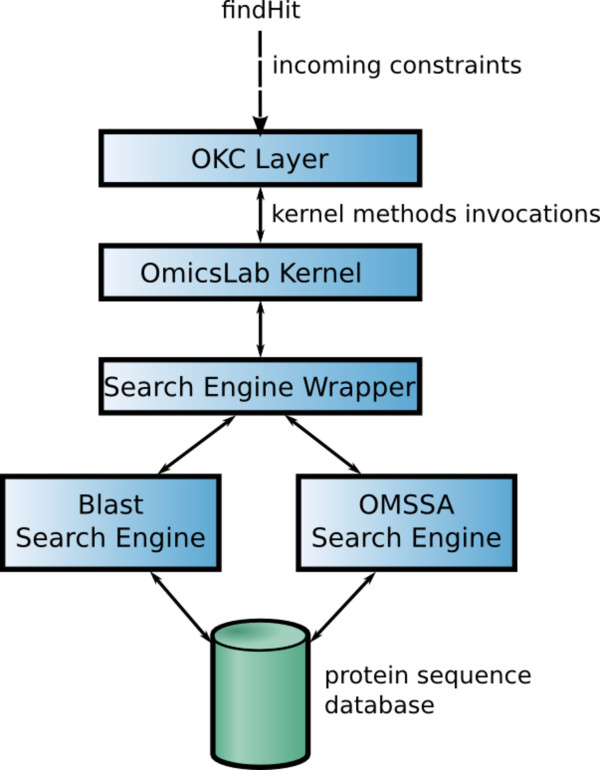
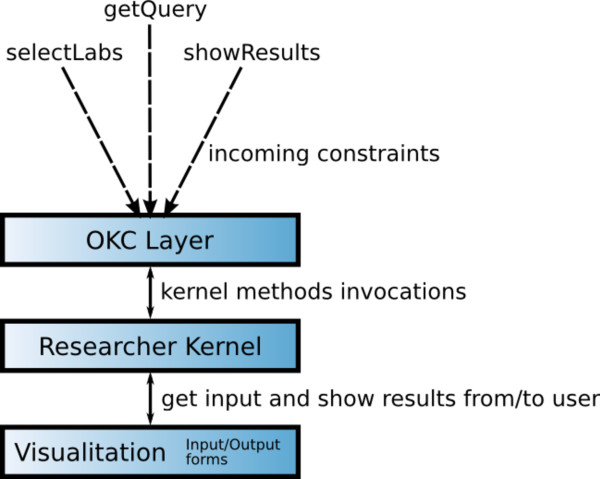
Methods: The system distributively runs a data-sharing protocol specified in the Lightweight Communication Calculus underlying the system through which researchers interact via message passing. For this, researchers interact with the system through particular components that link to database querying systems based on BLAST and/or OMSSA and GUI-based visualisation environments. We have tested the proposed platform with data drawn from preexisting MS/MS data reservoirs from the 2006 ABRF (Association of Biomolecular Resource Facilities) test sample, which was extensively tested during the ABRF Proteomics Standards Research Group 2006 worldwide survey. In particular we have taken the data available from a subset of proteomics laboratories of Spain's National Institute for Proteomics, ProteoRed, a network for the coordination, integration and development of the Spanish proteomics facilities.
Results and discussion: We performed queries against nine databases including seven ProteoRed proteomics laboratories, the NCBI Swiss-Prot database and the local database of the CSIC/UAB Proteomics Laboratory. A detailed analysis of the results indicated the presence of a protein that was supported by other NCBI matches and highly scored matches in several proteomics labs. The analysis clearly indicated that the protein was a relatively high concentrated contaminant that could be present in the ABRF sample. This fact is evident from the information that could be derived from the proposed P2P proteomics system, however it is not straightforward to arrive to the same conclusion by conventional means as it is difficult to discard organic contamination of samples. The actual presence of this contaminant was only stated after the ABRF study of all the identifications reported by the laboratories.


 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


