CDAF:点云补全的跨模态和双通道上样自适应融合网络
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
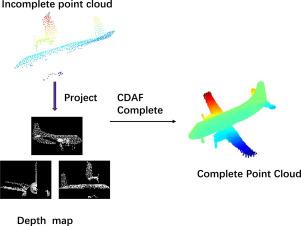
在现实场景中,由于传感器视点的限制、分辨率约束和自遮挡,点云数据往往存在不完整性,这阻碍了其在自动驾驶和机器人等领域的应用。为了解决这些挑战,本文提出了一种新的跨模态和双通道上样自适应融合网络(CDAF),我们的框架通过双通道关注和门控单元创新地将深度图与点云集成在一起,显著提高了补全精度和细节恢复。该框架包括两个核心模块:跨模态特征增强(CMFE)和双通道上采样自适应融合(DUAF)。CMFE通过利用空间激活通道关注模型通道依赖关系和Max-Sigmoid关注来对齐深度图和点云之间的跨模态特征来增强点云特征表示,DUAF通过并行结构分析和相似对齐分支逐步细化粗点云,实现局部几何先验和全局形状一致性的自适应融合。在多个基准数据集上的实验结果表明,CDAF在点云补全任务中优于现有的最先进的方法,展示了卓越的全局形状理解和细节恢复。本文章由计算机程序翻译,如有差异,请以英文原文为准。
CDAF: Cross-Modal and Dual-channel Upsample Adaptive Fusion network for Point Cloud Completion
In real-world scenarios, point cloud data often suffers from incompleteness due to limitations in sensor viewpoints, resolution constraints, and self-occlusions, which hinders its applications in domains such as autonomous driving and robotics. To address these challenges, this paper proposes a novel Cross-Modal and Dual-channel Upsample Adaptive Fusion network (CDAF), Our framework innovatively integrates depth maps with point clouds through dual-channel attention and gating units, significantly improving completion accuracy and detail recovery. The framework comprises two core modules: Cross-Modal Feature Enhancement (CMFE) and Dual-channel Upsampling Adaptive Fusion (DUAF). CMFE enhances point cloud feature representation by leveraging Spatial-activated Channel Attention to model channel-wise dependencies and Max-Sigmoid Attention to align cross-modal features between depth maps and point clouds, DUAF progressively refines coarse point clouds through a parallel structural analysis and similarity alignment branches, enabling adaptive fusion of local geometric priors and global shape consistency. Experimental results on multiple benchmark datasets demonstrate that CDAF surpasses existing state-of-the-art methods in point cloud completion tasks, showcasing superior global shape understanding and detail recovery.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


