预处理电子医疗记录中的叙事文本以识别医院不良事件:范围综述
IF 6.2
2区 医学
Q1 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
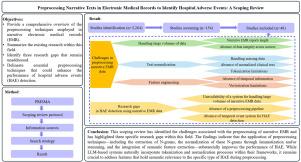
背景:叙述性电子病历(EMR)包括临床医生在医疗保健环境中创建的文本记录,是记录患者护理各个方面的重要资源。这种文本形式表现出明显的特点,如语法错误句子的出现、缩略语、频繁的首字母缩略词、具有特定含义的特殊字符、否定表达和零星的拼写错误。因此,处理这些文本注释的主要目标是实现有效的预处理技术,以提高数据质量并确保所有条目之间的一致性。在自然语言处理(NLP)、机器学习(ML)和大型语言模型(LLM)等领域,算法和方法的最新进展促使研究人员利用叙事EMR来检测医院不良事件(HAE)。方法:范围评价遵循PRISMA-ScR(系统评价和荟萃分析扩展范围评价的首选报告项目)指南。制定并使用了范围审查方案来指导研究过程,清楚地概述了资格标准、信息来源、搜索策略、数据管理、选择过程、数据收集程序、数据项目、结果和优先级、数据综合和元偏倚考虑。该搜索策略在9个工程和医疗电子数据库中实施。结果:结果表明,在总共3264项研究中,48项独特的研究被纳入了本综述。对研究问题的回答系统地从这些研究中提取出来。该综述确定了与EMR中用于HAE识别的叙事文本预处理相关的挑战。此外,已经确定了三个研究空白:(1)迫切需要一个管道来预处理叙事EMR以识别HAE,(2)需要一个能够管理大量叙事EMR数据的强大系统,以及(3)对时间事件系统的需求,这是有效检测HAE所必需的。该研究还强调了预处理任务在提高HAE检测性能方面的重要作用。该研究强调了从临床文本中提取n图的重要性,通过词源化和/或词干化将这些n图规范化,并在显著影响HAE检测性能的预处理任务中建立语义特征提取。虽然基于llm的系统在其框架中自然地包含了标记化和规范化过程,但在预处理期间处理与特定类型HAE具有语义相关性的特征仍然至关重要。结论:这一范围综述为研究人员利用叙事EMR数据检测HAE提供了有价值的见解。它阐明了预处理任务如何提高HAE检测的性能,并引起了对该领域被忽视的研究空白的关注。解决这些差距将需要在随后的研究工作中进一步调查。本文章由计算机程序翻译,如有差异,请以英文原文为准。
Preprocessing narrative texts in electronic medical records to identify hospital adverse events: A scoping review
Background:
Narrative electronic medical records (EMR), which include textual notes created by clinicians within healthcare environments, represent a significant resource for documenting various facets of patient care. This form of text exhibits distinctive characteristics, such as the occurrence of grammatically incorrect sentences, abbreviations, frequent acronyms, specialized characters with particular meanings, negation expressions, and sporadic misspellings. As a result, a primary goal in processing these textual notes is to implement effective preprocessing techniques that enhance data quality and ensure consistency across all entries. Recent advancements in algorithms and methodologies within the fields of natural language processing (NLP), machine learning (ML), and large language models (LLM) have prompted researchers to leverage narrative EMR for the detection of hospital adverse events (HAE).
Methods:
The scoping review adhered to the PRISMA-ScR (Preferred Reporting Items for Systematic Reviews and Meta-Analyses Extension for Scoping Reviews) guidelines. A scoping review protocol was developed and utilized to guide the research process, clearly outlining the eligibility criteria, information sources, search strategies, data management, selection process, data collection procedures, data items, outcomes and prioritization, data synthesis, and meta-bias considerations. The search strategy was implemented across nine engineering and medical electronic databases.
Results:
The results have indicated that from a total of 3,264 studies retrieved, 48 unique studies were included in the review. Responses to the research questions were systematically extracted from these studies. The review has identified challenges associated with the preprocessing of narrative texts in EMR for HAE identification. Additionally, three research gaps have been identified: (1) the imperative need for a pipeline to preprocess narrative EMR for the identification of HAE, (2) the necessity for a robust system capable of managing the extensive volume of narrative EMR data, and (3) the requirement for temporal event system, which are essential for effective HAE detection. The study also has underscored the essential role of preprocessing tasks in enhancing the performance of HAE detection. The study has emphasized the importance of extracting N-grams from clinical text, normalizing these N-grams through lemmatization and/or stemming, and establishing semantic feature extraction in preprocessing tasks that significantly affect HAE detection performance. While LLM-based systems naturally incorporate tokenization and normalization processes within their frameworks, it remains crucial to address features that hold semantic relevance to the specific type of HAE during preprocessing.
Conclusion:
This scoping review has provided valuable insights for researchers focused on HAE detection utilizing narrative EMR data. It has elucidated how preprocessing tasks can elevate the performance of HAE detection and draws attention to neglected research gaps within the field. Addressing these gaps will necessitate further investigation in subsequent research endeavors.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Artificial Intelligence in Medicine
工程技术-工程:生物医学
CiteScore
15.00
自引率
2.70%
发文量
143
审稿时长
6.3 months
期刊介绍:
Artificial Intelligence in Medicine publishes original articles from a wide variety of interdisciplinary perspectives concerning the theory and practice of artificial intelligence (AI) in medicine, medically-oriented human biology, and health care.
Artificial intelligence in medicine may be characterized as the scientific discipline pertaining to research studies, projects, and applications that aim at supporting decision-based medical tasks through knowledge- and/or data-intensive computer-based solutions that ultimately support and improve the performance of a human care provider.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


