AgileFormer:用于医学图像分割的空间敏捷和可扩展的转换器
IF 4.9
2区 医学
Q1 ENGINEERING, BIOMEDICAL
引用次数: 0
摘要
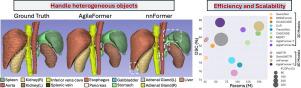
在过去的几十年里,深度神经网络,特别是卷积神经网络,已经在各种医学图像分割任务中取得了最先进的性能。最近,视觉转换器(ViTs)的引入显著地改变了深度分割模型的格局,因为它们能够捕获远程依赖关系。然而,我们认为目前基于viti的UNet (viti -UNet)分割模型的设计在处理医学图像分割任务中经常遇到的目标物体的异构外观(例如,不同形状和大小)方面受到限制。为了解决这一限制,我们提出了一种结构化的方法来将空间动态组件引入ViT-UNet。这使得模型能够有效地捕获具有不同外观的目标物体的特征。这是通过三个主要组成部分实现的:(i)可变形贴片嵌入;(ii)空间动态多头注意;(iii)多尺度可变形位置编码。这些组件被集成到一个新的体系结构中,称为AgileFormer,可以在viti - unet的每个阶段更有效地捕获异构对象。使用公开数据集(Synapse多器官、ACDC心脏和Decathlon脑肿瘤数据集)进行的三个分割任务实验证明了AgileFormer在2D和3D分割任务中的有效性。值得注意的是,我们的AgileFormer设置了一个新的最先进的性能,在Synapse上的2D和3D多器官分割的Dice Score分别为85.74%和87.43%,而没有显著的计算开销。我们的代码可在https://github.com/sotiraslab/AgileFormer上获得。本文章由计算机程序翻译,如有差异,请以英文原文为准。
AgileFormer: Spatially agile and scalable transformer for medical image segmentation
In the past decades, deep neural networks, particularly convolutional neural networks, have achieved state-of-the-art performance in various medical image segmentation tasks. Recently, the introduction of vision transformers (ViTs) has significantly altered the landscape of deep segmentation models, due to their ability to capture long-range dependencies. However, we argue that the current design of the ViT-based UNet (ViT-UNet) segmentation models is limited in handling the heterogeneous appearance (e.g., varying shapes and sizes) of target objects that are commonly encountered in medical image segmentation tasks. To tackle this limitation, we present a structured approach to introduce spatially dynamic components into a ViT-UNet. This enables the model to capture features of target objects with diverse appearances effectively. This is achieved by three main components: (i) deformable patch embedding; (ii) spatially dynamic multi-head attention; (iii) multi-scale deformable positional encoding. These components are integrated into a novel architecture, termed AgileFormer, enabling more effective capture of heterogeneous objects at every stage of a ViT-UNet. Experiments in three segmentation tasks using publicly available datasets (Synapse multi-organ, ACDC cardiac, and Decathlon brain tumor datasets) demonstrated the effectiveness of AgileFormer for 2D and 3D segmentation tasks. Remarkably, our AgileFormer sets a new state-of-the-art performance with a Dice Score of 85.74% and 87.43 % for 2D and 3D multi-organ segmentation on Synapse without significant computational overhead. Our code is avaliable at https://github.com/sotiraslab/AgileFormer.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Biomedical Signal Processing and Control
工程技术-工程:生物医学
CiteScore
9.80
自引率
13.70%
发文量
822
审稿时长
4 months
期刊介绍:
Biomedical Signal Processing and Control aims to provide a cross-disciplinary international forum for the interchange of information on research in the measurement and analysis of signals and images in clinical medicine and the biological sciences. Emphasis is placed on contributions dealing with the practical, applications-led research on the use of methods and devices in clinical diagnosis, patient monitoring and management.
Biomedical Signal Processing and Control reflects the main areas in which these methods are being used and developed at the interface of both engineering and clinical science. The scope of the journal is defined to include relevant review papers, technical notes, short communications and letters. Tutorial papers and special issues will also be published.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


