DECF-FGVC:一种细粒度鸟类视觉分类的判别增强和互补融合方法
IF 4.2
3区 计算机科学
Q2 COMPUTER SCIENCE, ARTIFICIAL INTELLIGENCE
引用次数: 0
摘要
细粒度鸟类图像识别在物种保护中起着重要作用。然而,现有的方法受到复杂背景干扰、判别特征提取不足和层次信息集成有限的限制。虽然视觉变换(ViTs)在细粒度分类任务中表现出优于cnn的性能,但它们仍然容易受到背景噪声的影响,类令牌通常无法捕获关键区域,从而忽略了低级细节和高级语义之间的互补性。本研究提出了DECF-FGVC,这是一个包含三个模块的新模型:斑块对比度增强(PCE),对比度令牌精炼(CTR)和分层令牌合成器(HTS)。这些模块通过关注加权图像重建、基于反事实学习的标记细化和分层标记融合,协同抑制背景噪声,强调关键区域,并整合多层特征。在CUB-200-2011、nabbirds和iNaturalist2017数据集上进行的大量实验分别实现了91.9%、91.4%和77.92%的分类准确率,始终优于最先进的方法。本文章由计算机程序翻译,如有差异,请以英文原文为准。
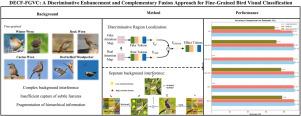
DECF-FGVC: A discriminative enhancement and complementary fusion approach for fine-grained bird visual classification
Fine-grained bird image recognition plays a critical role in species conservation. However, existing approaches are constrained by complex background interference, insufficient extraction of discriminative features, and limited integration of hierarchical information. While Vision Transformers (ViTs) demonstrate superior performance over CNNs in fine-grained classification tasks, they remain vulnerable to background noise, with class tokens often failing to capture key regions - overlooking the complementarity between low-level details and high-level semantics. This study proposes DECF-FGVC, a novel model incorporating three modules: Patch Contrast Enhancement (PCE), Contrast Token Refiner (CTR), and Hierarchical Token Synthesizer (HTS). These modules synergistically suppress background noise, emphasize key regions, and integrate multi-layer features through attention-weighted image reconstruction, counterfactual learning-based token refinement, and hierarchical token fusion. Extensive experiments on CUB-200-2011, NABirds, and iNaturalist2017 datasets achieve classification accuracies of 91.9%, 91.4%, and 77.92% respectively, consistently outperforming state-of-the-art methods.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Image and Vision Computing
工程技术-工程:电子与电气
CiteScore
8.50
自引率
8.50%
发文量
143
审稿时长
7.8 months
期刊介绍:
Image and Vision Computing has as a primary aim the provision of an effective medium of interchange for the results of high quality theoretical and applied research fundamental to all aspects of image interpretation and computer vision. The journal publishes work that proposes new image interpretation and computer vision methodology or addresses the application of such methods to real world scenes. It seeks to strengthen a deeper understanding in the discipline by encouraging the quantitative comparison and performance evaluation of the proposed methodology. The coverage includes: image interpretation, scene modelling, object recognition and tracking, shape analysis, monitoring and surveillance, active vision and robotic systems, SLAM, biologically-inspired computer vision, motion analysis, stereo vision, document image understanding, character and handwritten text recognition, face and gesture recognition, biometrics, vision-based human-computer interaction, human activity and behavior understanding, data fusion from multiple sensor inputs, image databases.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


