VTA编译指令流的数据访问和调度优化设计
IF 6.2
2区 计算机科学
Q1 COMPUTER SCIENCE, THEORY & METHODS
Future Generation Computer Systems-The International Journal of Escience
Pub Date : 2025-09-24
DOI:10.1016/j.future.2025.108165
引用次数: 0
摘要
近年来,卷积神经网络模型的开发和快速实现成为深度学习领域的一个重点研究领域,基于深度学习编译器的模型部署方案得到了广泛的研究。加速卷积运算过程和提高模型推理性能是深度学习编译器领域的重要研究方向之一。本文基于开源深度学习编译框架TVM和深度学习加速器VTA的架构,提出了一种基于输入优先调度和片上权重-内存复用方案的最小数据访问设计,为卷积神经网络推理加速提供了一种具有通用性的优化方案。采用优化后的调度方案,可以避免冗余的数据访问,使卷积计算具有合适的形状。对比实验表明,在硬件资源有限的情况下,YOLOv3的模型推理时间缩短了10%左右。本文章由计算机程序翻译,如有差异,请以英文原文为准。
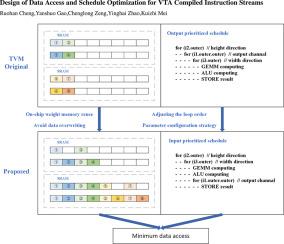
Design of data access and schedule optimization for VTA compiled instruction streams
In recent years, the development and rapid implementation of convolutional neural network models have become a key research area in the field of deep learning, and model deployment schemes based on deep learning compilers have been widely studied. Acceleration of the process of convolution operations and improvement of model inference performance is one of the important research areas in the field of deep learning compilers. In this paper, based on the open source deep learning compilation framework TVM and the architecture of the deep learning accelerator VTA, we propose a minimum data access design based on the input prioritized schedule and the on-chip weight-memory reuse scheme, which provides an optimization scheme with generality for inference acceleration of convolutional neural networks. By applying the optimized schedule scheme proposed, we can avoid redundant data accesses for convolutional computation with proper shape. Comparison experiments show that the model inference time of YOLOv3 is reduced by about 10 with limited hardware resources.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

CiteScore
19.90
自引率
2.70%
发文量
376
审稿时长
10.6 months
期刊介绍:
Computing infrastructures and systems are constantly evolving, resulting in increasingly complex and collaborative scientific applications. To cope with these advancements, there is a growing need for collaborative tools that can effectively map, control, and execute these applications.
Furthermore, with the explosion of Big Data, there is a requirement for innovative methods and infrastructures to collect, analyze, and derive meaningful insights from the vast amount of data generated. This necessitates the integration of computational and storage capabilities, databases, sensors, and human collaboration.
Future Generation Computer Systems aims to pioneer advancements in distributed systems, collaborative environments, high-performance computing, and Big Data analytics. It strives to stay at the forefront of developments in grids, clouds, and the Internet of Things (IoT) to effectively address the challenges posed by these wide-area, fully distributed sensing and computing systems.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


