“数字伪装”:基于llm的恶意软件检测中的LLVM挑战
IF 4.1
2区 计算机科学
Q1 COMPUTER SCIENCE, SOFTWARE ENGINEERING
引用次数: 0
摘要
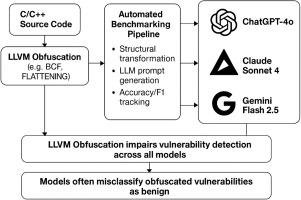
大型语言模型(llm)已经成为通过分析代码语义、识别漏洞和适应不断变化的威胁来检测恶意软件的有前途的工具。然而,它们在对抗编译器级混淆下的可靠性还有待发现。在本研究中,我们通过经验评估了三种最先进的llm: chatggt - 40、Gemini Flash 2.5和Claude Sonnet 4对通过LLVM基础架构实现的编译器级混淆技术的鲁棒性。这些方法包括控制流平坦化、虚假控制流注入、指令替换和分割基本块,这些方法广泛用于逃避检测,同时保留恶意行为。我们对来自design数据集的40个C函数(20个易受攻击,20个安全)进行了结构化评估,并使用LLVM通道进行了混淆。我们的研究结果表明,这些模型往往不能正确分类混淆的代码,转换后的精度、召回率和f1分数显著下降。这揭示了一个关键的限制:llm尽管具有语言理解能力,但很容易被基于编译器的混淆策略所误导。为了提高可重复性,我们在公共存储库中发布了所有的评估脚本、提示和混淆代码示例。我们还讨论了这些发现对对抗性威胁建模的影响,并概述了未来的发展方向,如软件水印、编译器感知防御和抗混淆模型设计。本文章由计算机程序翻译,如有差异,请以英文原文为准。
“Digital Camouflage”: The LLVM challenge in LLM-based malware detection
Large Language Models (LLMs) have emerged as promising tools for malware detection by analyzing code semantics, identifying vulnerabilities, and adapting to evolving threats. However, their reliability under adversarial compiler-level obfuscation is yet to be discovered. In this study, we empirically evaluate the robustness of three state-of-the-art LLMs: ChatGPT-4o, Gemini Flash 2.5, and Claude Sonnet 4 against compiler-level obfuscation techniques implemented via the LLVM infrastructure. These include control flow flattening, bogus control flow injection, instruction substitution, and split basic blocks, which are widely used to evade detection while preserving malicious behavior. We perform a structured evaluation on 40 C functions (20 vulnerable, 20 secure) sourced from the Devign dataset and obfuscated using LLVM passes. Our results show that these models often fail to correctly classify obfuscated code, with precision, recall, and F1-score dropping significantly after transformation. This reveals a critical limitation: LLMs, despite their language understanding capabilities, can be easily misled by compiler-based obfuscation strategies. To promote reproducibility, we release all evaluation scripts, prompts, and obfuscated code samples in a public repository. We also discuss the implications of these findings for adversarial threat modeling, and outline future directions such as software watermarking, compiler-aware defenses, and obfuscation-resilient model design.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Journal of Systems and Software
工程技术-计算机:理论方法
CiteScore
8.60
自引率
5.70%
发文量
193
审稿时长
16 weeks
期刊介绍:
The Journal of Systems and Software publishes papers covering all aspects of software engineering and related hardware-software-systems issues. All articles should include a validation of the idea presented, e.g. through case studies, experiments, or systematic comparisons with other approaches already in practice. Topics of interest include, but are not limited to:
•Methods and tools for, and empirical studies on, software requirements, design, architecture, verification and validation, maintenance and evolution
•Agile, model-driven, service-oriented, open source and global software development
•Approaches for mobile, multiprocessing, real-time, distributed, cloud-based, dependable and virtualized systems
•Human factors and management concerns of software development
•Data management and big data issues of software systems
•Metrics and evaluation, data mining of software development resources
•Business and economic aspects of software development processes
The journal welcomes state-of-the-art surveys and reports of practical experience for all of these topics.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


