近红外光谱数据的自动预处理框架
IF 3.8
2区 化学
Q2 AUTOMATION & CONTROL SYSTEMS
Chemometrics and Intelligent Laboratory Systems
Pub Date : 2025-09-28
DOI:10.1016/j.chemolab.2025.105542
引用次数: 0
摘要
预处理在近红外光谱(NIRS)数据分析中起着至关重要的作用,因为它旨在去除意外的伪影。这个过程包括一系列步骤,每个步骤都特别关注一个特定的工件。然而,由于近红外光谱的应用范围多样,选择最佳的预处理方法组合仍然是一个挑战。为了解决这个问题,我们提出了一个可以快速识别最佳预处理策略的自动化预处理框架。该框架首先构建了一个由多种预处理方法组成的工作流。然后,利用遗传算法(GA)技术优化最佳管道,避免了穷举搜索。此外,我们对遗传过程的损失函数施加惩罚,以获得一个简约的解。在三个真实数据集上的结果表明,我们的方法在预测误差方面优于几种最先进的集成预处理方法。与原始数据相比,最优预处理方法可使模型性能提高至少48%。此外,我们的框架能够识别最佳管道中包含的最有效的预处理方法。我们的方法的源代码可以在GitHub上获得,并且可以很容易地与其他现有的预处理技术集成。本文章由计算机程序翻译,如有差异,请以英文原文为准。
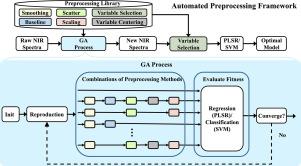
An automated preprocessing framework for near infrared spectroscopic data
Preprocessing plays a vital role in the analysis of Near-infrared spectroscopy (NIRS) data as it aims to remove unintended artifacts. This process involves a series of steps, each with a specific focus on a particular artifact. However, due to the diverse range of NIRS applications, selecting the optimal combination of preprocessing methods remains a challenge. To address this issue, we propose an automated preprocessing framework that can quickly identify the optimal preprocessing strategy. The framework initially constructs a workflow consisting of multiple types of preprocessing methods. Then, a genetic algorithm (GA) technique is used to optimize the best pipeline, avoiding exhaustive searches. In addition, we impose a penalty for the loss function of the GA process to obtain a parsimonious solution. Results on three real-world datasets demonstrate that our approach outperforms several state-of-the-art ensemble preprocessing methods in terms of prediction error. Compared to the raw data, the optimal preprocessing method can improve model performance by at least 48%. Furthermore, our framework enables the identification of the most effective preprocessing methods included in the best pipeline. The source code for our approach is available on GitHub and can be easily integrated with other existing preprocessing techniques.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

CiteScore
7.50
自引率
7.70%
发文量
169
审稿时长
3.4 months
期刊介绍:
Chemometrics and Intelligent Laboratory Systems publishes original research papers, short communications, reviews, tutorials and Original Software Publications reporting on development of novel statistical, mathematical, or computer techniques in Chemistry and related disciplines.
Chemometrics is the chemical discipline that uses mathematical and statistical methods to design or select optimal procedures and experiments, and to provide maximum chemical information by analysing chemical data.
The journal deals with the following topics:
1) Development of new statistical, mathematical and chemometrical methods for Chemistry and related fields (Environmental Chemistry, Biochemistry, Toxicology, System Biology, -Omics, etc.)
2) Novel applications of chemometrics to all branches of Chemistry and related fields (typical domains of interest are: process data analysis, experimental design, data mining, signal processing, supervised modelling, decision making, robust statistics, mixture analysis, multivariate calibration etc.) Routine applications of established chemometrical techniques will not be considered.
3) Development of new software that provides novel tools or truly advances the use of chemometrical methods.
4) Well characterized data sets to test performance for the new methods and software.
The journal complies with International Committee of Medical Journal Editors'' Uniform requirements for manuscripts.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


