{"title":"哈萨克斯坦HER2乳腺癌数字图像数据集:ADEL数据集。","authors":"Gauhar Dunenova, Aidos Sarsembayev, Alexandr Ivankov, Dilyara Kaidarova, Zhanna Kalmatayeva, Elvira Satbayeva, Natalya Glushkova","doi":"10.1016/j.dib.2025.112052","DOIUrl":null,"url":null,"abstract":"<p><p>Breast cancer remains a leading cause of cancer-related mortality among women worldwide, with HER2-positive subtypes requiring precise diagnostic approaches to guide targeted therapy. Digital pathology and AI-based tools offer promising solutions, but their development relies heavily on high-quality digital datasets, labelled or annotated. In this study, we present a dataset of digital images of breast cancer tissue samples with immunohistochemical expression of human epidermal growth factor receptor 2 (HER2) classes 0, 1+, 2+, and 3+. Breast cancer tissue samples were formalin-fixed and paraffin-embedded (FFPE), followed by the preparation of paraffin blocks and 5-µm sections. Immunohistochemical staining was performed using a Ventana Benchmark Ultra automated immunostainer with PATHWAY anti-HER2/neu (4B5) rabbit monoclonal antibodies and ULTRA VIEW detection system. Digital images were acquired via a fully automated digital system (KFB PRO 120 scanner) at INVIVO LLP with 40x magnification and one focusing layer, ranging in size from 50 MB to 2 GB, depending on the size of the tissue sample fixed on the original slide. The dataset consists of 418 subfolders with images, each corresponding to a source image and containing a different number of tiles depending on the size of the source image. The original images were preprocessed using a conversion script that transformed SVS files into sub-images with a 1:1 aspect ratio in JPEG format. A non-overlapping sliding window approach was applied to generate these sub-images, optimized for machine learning applications. A square window of 1000 × 1000 pixels was used to crop sub-images with a 1:1 aspect ratio. The stride of the sliding window was set to a value that was a multiple of the image resolution (as determined during preprocessing). As a result, a variable number of sub-images were generated from each original SVS image, depending on its size. The output file format was JPEG. Clinical labeling of the data was provided by reference laboratory pathologists with expertise in advanced oncological morphology evaluations. This dataset allows training and validation of machine learning models for the diagnosis, recognition, and classification of breast cancer using the available labeling, as well as for educational purposes for residents and pathologists.</p>","PeriodicalId":10973,"journal":{"name":"Data in Brief","volume":"62 ","pages":"112052"},"PeriodicalIF":1.4000,"publicationDate":"2025-09-11","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12478050/pdf/","citationCount":"0","resultStr":"{\"title\":\"Kazakhstani HER2 breast cancer digital image dataset: The ADEL dataset.\",\"authors\":\"Gauhar Dunenova, Aidos Sarsembayev, Alexandr Ivankov, Dilyara Kaidarova, Zhanna Kalmatayeva, Elvira Satbayeva, Natalya Glushkova\",\"doi\":\"10.1016/j.dib.2025.112052\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Breast cancer remains a leading cause of cancer-related mortality among women worldwide, with HER2-positive subtypes requiring precise diagnostic approaches to guide targeted therapy. Digital pathology and AI-based tools offer promising solutions, but their development relies heavily on high-quality digital datasets, labelled or annotated. In this study, we present a dataset of digital images of breast cancer tissue samples with immunohistochemical expression of human epidermal growth factor receptor 2 (HER2) classes 0, 1+, 2+, and 3+. Breast cancer tissue samples were formalin-fixed and paraffin-embedded (FFPE), followed by the preparation of paraffin blocks and 5-µm sections. Immunohistochemical staining was performed using a Ventana Benchmark Ultra automated immunostainer with PATHWAY anti-HER2/neu (4B5) rabbit monoclonal antibodies and ULTRA VIEW detection system. Digital images were acquired via a fully automated digital system (KFB PRO 120 scanner) at INVIVO LLP with 40x magnification and one focusing layer, ranging in size from 50 MB to 2 GB, depending on the size of the tissue sample fixed on the original slide. The dataset consists of 418 subfolders with images, each corresponding to a source image and containing a different number of tiles depending on the size of the source image. The original images were preprocessed using a conversion script that transformed SVS files into sub-images with a 1:1 aspect ratio in JPEG format. A non-overlapping sliding window approach was applied to generate these sub-images, optimized for machine learning applications. A square window of 1000 × 1000 pixels was used to crop sub-images with a 1:1 aspect ratio. The stride of the sliding window was set to a value that was a multiple of the image resolution (as determined during preprocessing). As a result, a variable number of sub-images were generated from each original SVS image, depending on its size. The output file format was JPEG. Clinical labeling of the data was provided by reference laboratory pathologists with expertise in advanced oncological morphology evaluations. This dataset allows training and validation of machine learning models for the diagnosis, recognition, and classification of breast cancer using the available labeling, as well as for educational purposes for residents and pathologists.</p>\",\"PeriodicalId\":10973,\"journal\":{\"name\":\"Data in Brief\",\"volume\":\"62 \",\"pages\":\"112052\"},\"PeriodicalIF\":1.4000,\"publicationDate\":\"2025-09-11\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12478050/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Data in Brief\",\"FirstCategoryId\":\"1085\",\"ListUrlMain\":\"https://doi.org/10.1016/j.dib.2025.112052\",\"RegionNum\":0,\"RegionCategory\":null,\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"2025/10/1 0:00:00\",\"PubModel\":\"eCollection\",\"JCR\":\"Q3\",\"JCRName\":\"MULTIDISCIPLINARY SCIENCES\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Data in Brief","FirstCategoryId":"1085","ListUrlMain":"https://doi.org/10.1016/j.dib.2025.112052","RegionNum":0,"RegionCategory":null,"ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"2025/10/1 0:00:00","PubModel":"eCollection","JCR":"Q3","JCRName":"MULTIDISCIPLINARY SCIENCES","Score":null,"Total":0}
Kazakhstani HER2 breast cancer digital image dataset: The ADEL dataset.
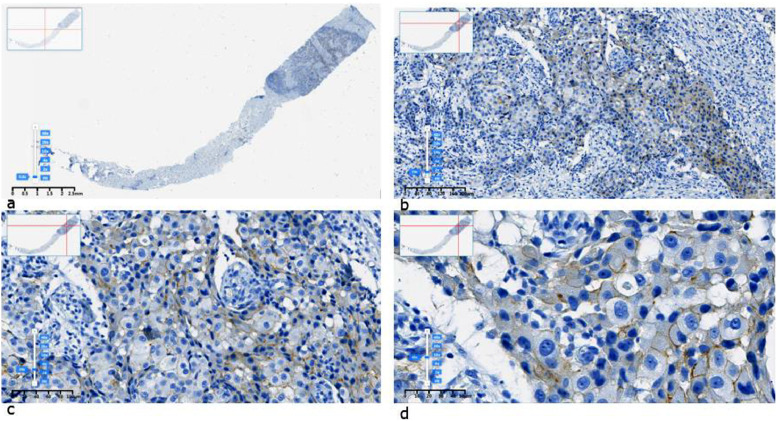
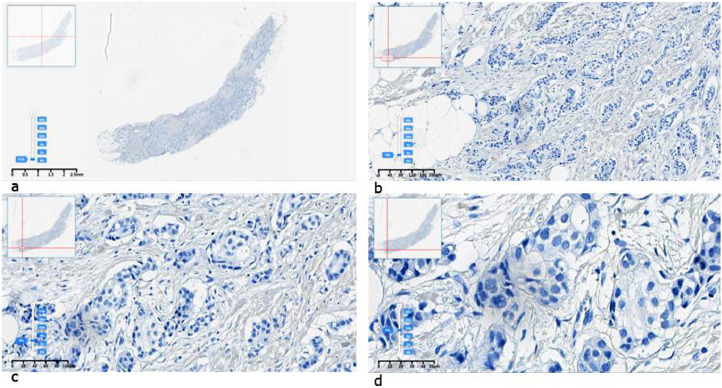
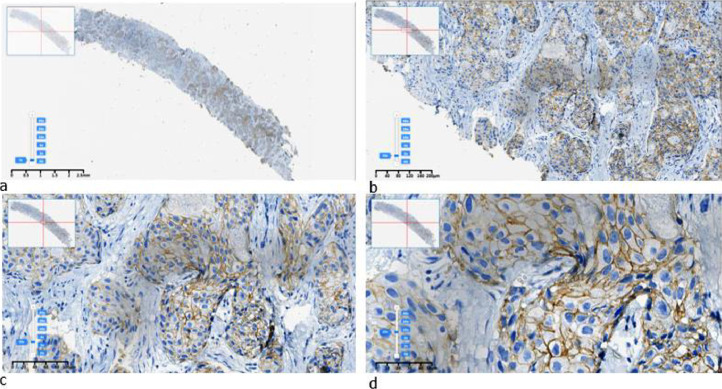
Breast cancer remains a leading cause of cancer-related mortality among women worldwide, with HER2-positive subtypes requiring precise diagnostic approaches to guide targeted therapy. Digital pathology and AI-based tools offer promising solutions, but their development relies heavily on high-quality digital datasets, labelled or annotated. In this study, we present a dataset of digital images of breast cancer tissue samples with immunohistochemical expression of human epidermal growth factor receptor 2 (HER2) classes 0, 1+, 2+, and 3+. Breast cancer tissue samples were formalin-fixed and paraffin-embedded (FFPE), followed by the preparation of paraffin blocks and 5-µm sections. Immunohistochemical staining was performed using a Ventana Benchmark Ultra automated immunostainer with PATHWAY anti-HER2/neu (4B5) rabbit monoclonal antibodies and ULTRA VIEW detection system. Digital images were acquired via a fully automated digital system (KFB PRO 120 scanner) at INVIVO LLP with 40x magnification and one focusing layer, ranging in size from 50 MB to 2 GB, depending on the size of the tissue sample fixed on the original slide. The dataset consists of 418 subfolders with images, each corresponding to a source image and containing a different number of tiles depending on the size of the source image. The original images were preprocessed using a conversion script that transformed SVS files into sub-images with a 1:1 aspect ratio in JPEG format. A non-overlapping sliding window approach was applied to generate these sub-images, optimized for machine learning applications. A square window of 1000 × 1000 pixels was used to crop sub-images with a 1:1 aspect ratio. The stride of the sliding window was set to a value that was a multiple of the image resolution (as determined during preprocessing). As a result, a variable number of sub-images were generated from each original SVS image, depending on its size. The output file format was JPEG. Clinical labeling of the data was provided by reference laboratory pathologists with expertise in advanced oncological morphology evaluations. This dataset allows training and validation of machine learning models for the diagnosis, recognition, and classification of breast cancer using the available labeling, as well as for educational purposes for residents and pathologists.
期刊介绍:
Data in Brief provides a way for researchers to easily share and reuse each other''s datasets by publishing data articles that: -Thoroughly describe your data, facilitating reproducibility. -Make your data, which is often buried in supplementary material, easier to find. -Increase traffic towards associated research articles and data, leading to more citations. -Open up doors for new collaborations. Because you never know what data will be useful to someone else, Data in Brief welcomes submissions that describe data from all research areas.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


