Daniela Raciti, Kimberly M Van Auken, Valerio Arnaboldi, Christopher J Tabone, Hans-Michael Muller, Paul W Sternberg
{"title":"生物医学文献中句子的表征和自动分类:基因表达和蛋白激酶活性的生物固化案例研究。","authors":"Daniela Raciti, Kimberly M Van Auken, Valerio Arnaboldi, Christopher J Tabone, Hans-Michael Muller, Paul W Sternberg","doi":"10.1093/database/baaf063","DOIUrl":null,"url":null,"abstract":"<p><p>Biological knowledgebases are essential resources for biomedical researchers, providing ready access to gene function and genomic data. Professional, manual curation of knowledgebases, however, is labour-intensive and thus high-performing machine learning (ML) methods that improve biocuration efficiency are needed. Here, we report on sentence-level classification to identify biocuration-relevant sentences in the full text of published references for two gene function data types: gene expression and protein kinase activity. We performed a detailed characterization of sentences from references in the WormBase bibliography and used this characterization to define three tasks for classifying sentences as either (i) fully curatable, (ii) fully and partially curatable, or (iii) all language-related. We evaluated various ML models applied to these tasks and found that GPT and BioBERT achieve the highest average performance, resulting in F1 performance scores ranging from 0.89 to 0.99 depending upon the task. Moreover, our inter-annotator agreement analyses and curator timing exercises demonstrated that curators readily converged on classification of high-quality training sentences that take a relatively short period of time to collect, making expansion of this approach to other data types a realistic addition to existing biocuration workflows. Our findings demonstrate the feasibility of extracting biocuration-relevant sentences from full text. Integrating these models into professional biocuration workflows, such as those used by the Alliance of Genome Resources and the ACKnowledge community curation platform, might well facilitate efficient and accurate annotation of the biomedical literature.</p>","PeriodicalId":10923,"journal":{"name":"Database: The Journal of Biological Databases and Curation","volume":"2025 ","pages":""},"PeriodicalIF":3.6000,"publicationDate":"2025-01-18","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12482909/pdf/","citationCount":"0","resultStr":"{\"title\":\"Characterization and automated classification of sentences in the biomedical literature: a case study for biocuration of gene expression and protein kinase activity.\",\"authors\":\"Daniela Raciti, Kimberly M Van Auken, Valerio Arnaboldi, Christopher J Tabone, Hans-Michael Muller, Paul W Sternberg\",\"doi\":\"10.1093/database/baaf063\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p>Biological knowledgebases are essential resources for biomedical researchers, providing ready access to gene function and genomic data. Professional, manual curation of knowledgebases, however, is labour-intensive and thus high-performing machine learning (ML) methods that improve biocuration efficiency are needed. Here, we report on sentence-level classification to identify biocuration-relevant sentences in the full text of published references for two gene function data types: gene expression and protein kinase activity. We performed a detailed characterization of sentences from references in the WormBase bibliography and used this characterization to define three tasks for classifying sentences as either (i) fully curatable, (ii) fully and partially curatable, or (iii) all language-related. We evaluated various ML models applied to these tasks and found that GPT and BioBERT achieve the highest average performance, resulting in F1 performance scores ranging from 0.89 to 0.99 depending upon the task. Moreover, our inter-annotator agreement analyses and curator timing exercises demonstrated that curators readily converged on classification of high-quality training sentences that take a relatively short period of time to collect, making expansion of this approach to other data types a realistic addition to existing biocuration workflows. Our findings demonstrate the feasibility of extracting biocuration-relevant sentences from full text. Integrating these models into professional biocuration workflows, such as those used by the Alliance of Genome Resources and the ACKnowledge community curation platform, might well facilitate efficient and accurate annotation of the biomedical literature.</p>\",\"PeriodicalId\":10923,\"journal\":{\"name\":\"Database: The Journal of Biological Databases and Curation\",\"volume\":\"2025 \",\"pages\":\"\"},\"PeriodicalIF\":3.6000,\"publicationDate\":\"2025-01-18\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12482909/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Database: The Journal of Biological Databases and Curation\",\"FirstCategoryId\":\"99\",\"ListUrlMain\":\"https://doi.org/10.1093/database/baaf063\",\"RegionNum\":4,\"RegionCategory\":\"生物学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MATHEMATICAL & COMPUTATIONAL BIOLOGY\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Database: The Journal of Biological Databases and Curation","FirstCategoryId":"99","ListUrlMain":"https://doi.org/10.1093/database/baaf063","RegionNum":4,"RegionCategory":"生物学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MATHEMATICAL & COMPUTATIONAL BIOLOGY","Score":null,"Total":0}
Characterization and automated classification of sentences in the biomedical literature: a case study for biocuration of gene expression and protein kinase activity.
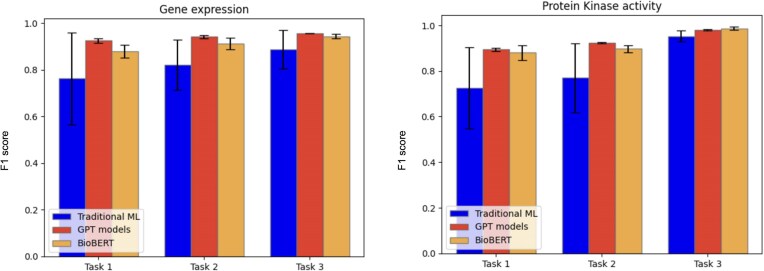
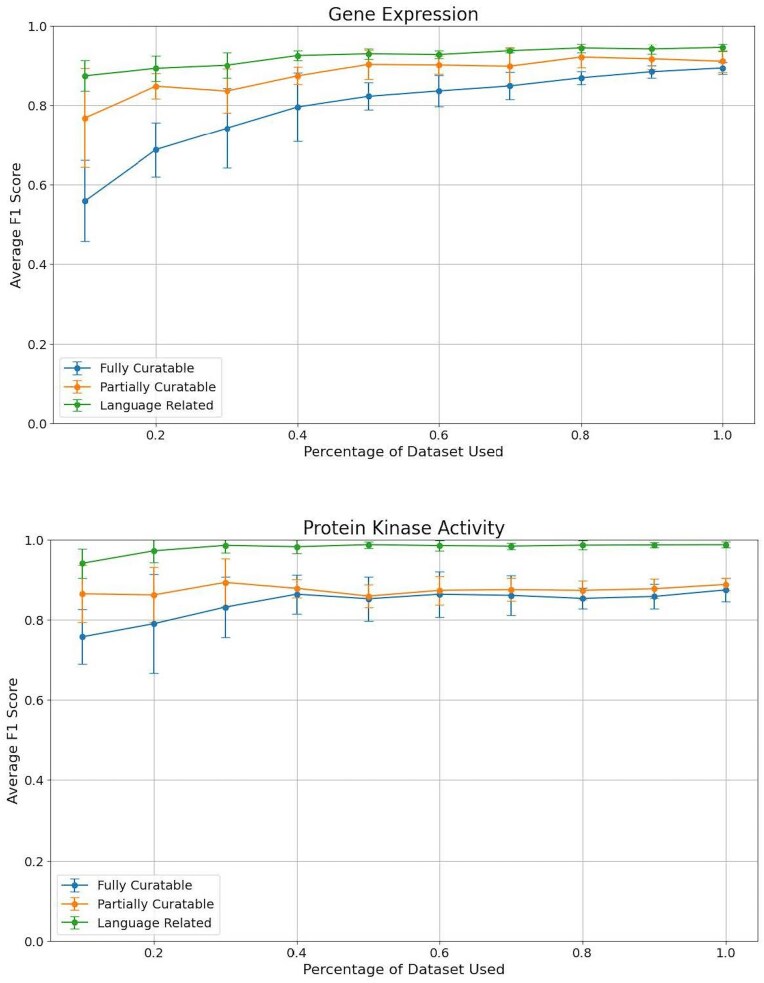
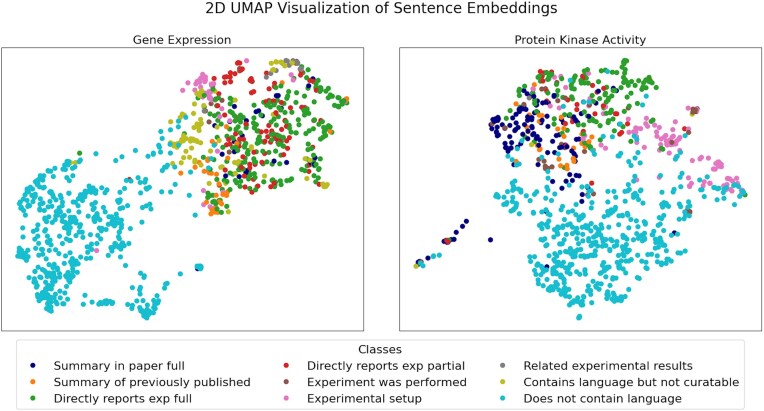
Biological knowledgebases are essential resources for biomedical researchers, providing ready access to gene function and genomic data. Professional, manual curation of knowledgebases, however, is labour-intensive and thus high-performing machine learning (ML) methods that improve biocuration efficiency are needed. Here, we report on sentence-level classification to identify biocuration-relevant sentences in the full text of published references for two gene function data types: gene expression and protein kinase activity. We performed a detailed characterization of sentences from references in the WormBase bibliography and used this characterization to define three tasks for classifying sentences as either (i) fully curatable, (ii) fully and partially curatable, or (iii) all language-related. We evaluated various ML models applied to these tasks and found that GPT and BioBERT achieve the highest average performance, resulting in F1 performance scores ranging from 0.89 to 0.99 depending upon the task. Moreover, our inter-annotator agreement analyses and curator timing exercises demonstrated that curators readily converged on classification of high-quality training sentences that take a relatively short period of time to collect, making expansion of this approach to other data types a realistic addition to existing biocuration workflows. Our findings demonstrate the feasibility of extracting biocuration-relevant sentences from full text. Integrating these models into professional biocuration workflows, such as those used by the Alliance of Genome Resources and the ACKnowledge community curation platform, might well facilitate efficient and accurate annotation of the biomedical literature.
期刊介绍:
Huge volumes of primary data are archived in numerous open-access databases, and with new generation technologies becoming more common in laboratories, large datasets will become even more prevalent. The archiving, curation, analysis and interpretation of all of these data are a challenge. Database development and biocuration are at the forefront of the endeavor to make sense of this mounting deluge of data.
Database: The Journal of Biological Databases and Curation provides an open access platform for the presentation of novel ideas in database research and biocuration, and aims to help strengthen the bridge between database developers, curators, and users.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


