Sergio Ayala-De la Cruz, Paola Elizabeth Arenas-Hernández, María Fernanda Fernández-Herrera, Rebeca Alejandrina Quiñones-Díaz, Jorge Martín Llaca-Díaz, Erik Alejandro Díaz-Chuc, Diana Guadalupe Robles-Espino, Erik Alejandro San Miguel-Garay
{"title":"llm辅助动脉血气解释的人在环性能:一项单中心回顾性研究。","authors":"Sergio Ayala-De la Cruz, Paola Elizabeth Arenas-Hernández, María Fernanda Fernández-Herrera, Rebeca Alejandrina Quiñones-Díaz, Jorge Martín Llaca-Díaz, Erik Alejandro Díaz-Chuc, Diana Guadalupe Robles-Espino, Erik Alejandro San Miguel-Garay","doi":"10.3390/jcm14186676","DOIUrl":null,"url":null,"abstract":"<p><p><b>Background and Objectives</b>: Interpreting acid-base disorders is challenging, particularly in complex or mixed cases. Given the growing potential of large language models (LLMs) to assist in cognitively demanding tasks, this study evaluated their performance in interpreting arterial blood gas (ABG) results. <b>Materials and Methods</b>: In this single-center retrospective study, 200 ABG datasets were curated to include 40 cases in each of five diagnostic categories: metabolic acidosis, respiratory acidosis, metabolic alkalosis, respiratory alkalosis, and no acid-base disorder. Three medical students, each assigned to one LLM (ChatGPT GPT-4o, Copilot GPT-4, or Gemini 1.5-flash/2.5-flash), perform ABG interpretation using two evaluation methods: interpretation (LLM-I) and interpretation with supervision model (LLM-S). Two clinical pathologists independently performed the conventional evaluation to serve as the reference standard. <b>Results</b>: Agreement for identifying the primary acid-base (APD) disorder was strong across all approaches (Cohen's κ ≥ 0.88). For identifying both primary and secondary disorders regardless of order (APSD), LLM-I showed moderate agreement (ChatGPT κ = 0.65, Copilot κ = 0.61, Gemini κ = 0.62), whereas LLM-S achieved strong agreement (ChatGPT κ = 0.91, Copilot κ = 0.81, Gemini κ = 0.81). <b>Conclusions</b>: LLM-assisted ABG interpretation demonstrates strong concordance with expert interpretation in detecting primary acid-base disorders. These tools may enhance the understanding of acid-base disorders while reducing calculation-related errors among medical students.</p>","PeriodicalId":15533,"journal":{"name":"Journal of Clinical Medicine","volume":"14 18","pages":""},"PeriodicalIF":2.9000,"publicationDate":"2025-09-22","publicationTypes":"Journal Article","fieldsOfStudy":null,"isOpenAccess":false,"openAccessPdf":"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12470526/pdf/","citationCount":"0","resultStr":"{\"title\":\"Human-in-the-Loop Performance of LLM-Assisted Arterial Blood Gas Interpretation: A Single-Center Retrospective Study.\",\"authors\":\"Sergio Ayala-De la Cruz, Paola Elizabeth Arenas-Hernández, María Fernanda Fernández-Herrera, Rebeca Alejandrina Quiñones-Díaz, Jorge Martín Llaca-Díaz, Erik Alejandro Díaz-Chuc, Diana Guadalupe Robles-Espino, Erik Alejandro San Miguel-Garay\",\"doi\":\"10.3390/jcm14186676\",\"DOIUrl\":null,\"url\":null,\"abstract\":\"<p><p><b>Background and Objectives</b>: Interpreting acid-base disorders is challenging, particularly in complex or mixed cases. Given the growing potential of large language models (LLMs) to assist in cognitively demanding tasks, this study evaluated their performance in interpreting arterial blood gas (ABG) results. <b>Materials and Methods</b>: In this single-center retrospective study, 200 ABG datasets were curated to include 40 cases in each of five diagnostic categories: metabolic acidosis, respiratory acidosis, metabolic alkalosis, respiratory alkalosis, and no acid-base disorder. Three medical students, each assigned to one LLM (ChatGPT GPT-4o, Copilot GPT-4, or Gemini 1.5-flash/2.5-flash), perform ABG interpretation using two evaluation methods: interpretation (LLM-I) and interpretation with supervision model (LLM-S). Two clinical pathologists independently performed the conventional evaluation to serve as the reference standard. <b>Results</b>: Agreement for identifying the primary acid-base (APD) disorder was strong across all approaches (Cohen's κ ≥ 0.88). For identifying both primary and secondary disorders regardless of order (APSD), LLM-I showed moderate agreement (ChatGPT κ = 0.65, Copilot κ = 0.61, Gemini κ = 0.62), whereas LLM-S achieved strong agreement (ChatGPT κ = 0.91, Copilot κ = 0.81, Gemini κ = 0.81). <b>Conclusions</b>: LLM-assisted ABG interpretation demonstrates strong concordance with expert interpretation in detecting primary acid-base disorders. These tools may enhance the understanding of acid-base disorders while reducing calculation-related errors among medical students.</p>\",\"PeriodicalId\":15533,\"journal\":{\"name\":\"Journal of Clinical Medicine\",\"volume\":\"14 18\",\"pages\":\"\"},\"PeriodicalIF\":2.9000,\"publicationDate\":\"2025-09-22\",\"publicationTypes\":\"Journal Article\",\"fieldsOfStudy\":null,\"isOpenAccess\":false,\"openAccessPdf\":\"https://www.ncbi.nlm.nih.gov/pmc/articles/PMC12470526/pdf/\",\"citationCount\":\"0\",\"resultStr\":null,\"platform\":\"Semanticscholar\",\"paperid\":null,\"PeriodicalName\":\"Journal of Clinical Medicine\",\"FirstCategoryId\":\"3\",\"ListUrlMain\":\"https://doi.org/10.3390/jcm14186676\",\"RegionNum\":3,\"RegionCategory\":\"医学\",\"ArticlePicture\":[],\"TitleCN\":null,\"AbstractTextCN\":null,\"PMCID\":null,\"EPubDate\":\"\",\"PubModel\":\"\",\"JCR\":\"Q1\",\"JCRName\":\"MEDICINE, GENERAL & INTERNAL\",\"Score\":null,\"Total\":0}","platform":"Semanticscholar","paperid":null,"PeriodicalName":"Journal of Clinical Medicine","FirstCategoryId":"3","ListUrlMain":"https://doi.org/10.3390/jcm14186676","RegionNum":3,"RegionCategory":"医学","ArticlePicture":[],"TitleCN":null,"AbstractTextCN":null,"PMCID":null,"EPubDate":"","PubModel":"","JCR":"Q1","JCRName":"MEDICINE, GENERAL & INTERNAL","Score":null,"Total":0}
Human-in-the-Loop Performance of LLM-Assisted Arterial Blood Gas Interpretation: A Single-Center Retrospective Study.
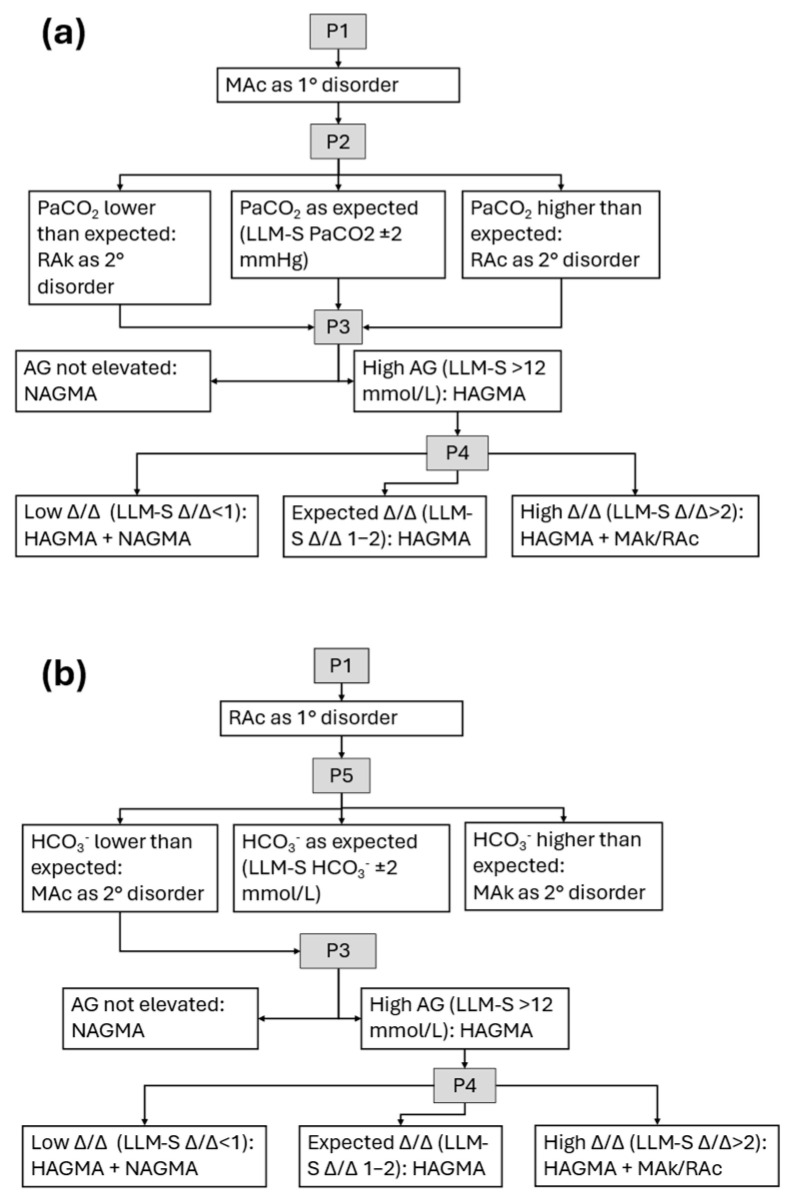
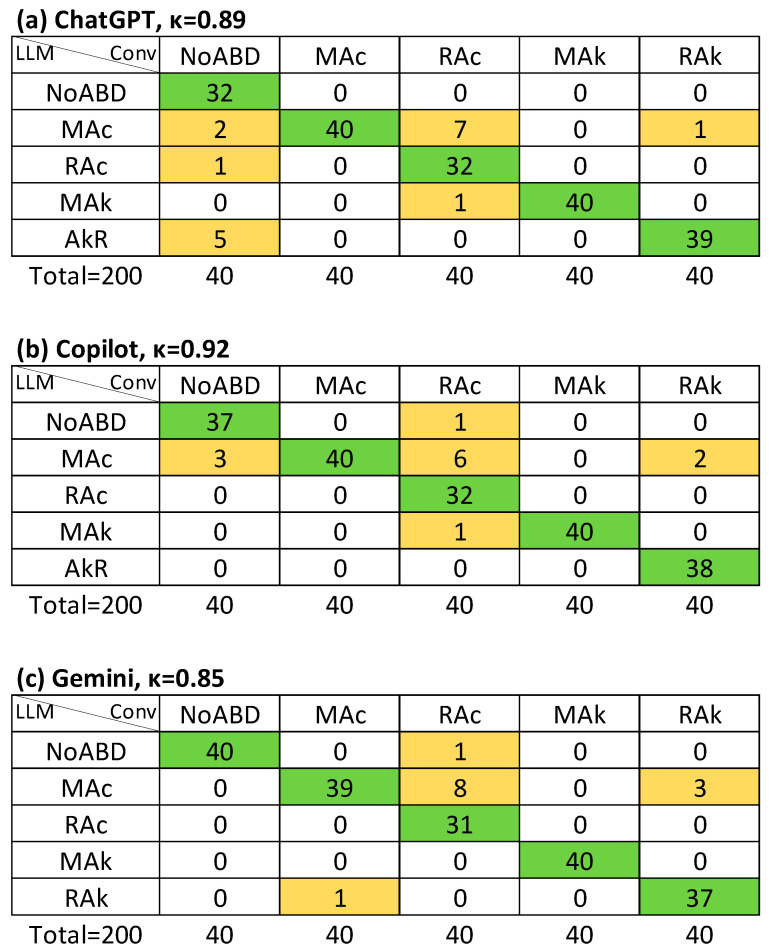
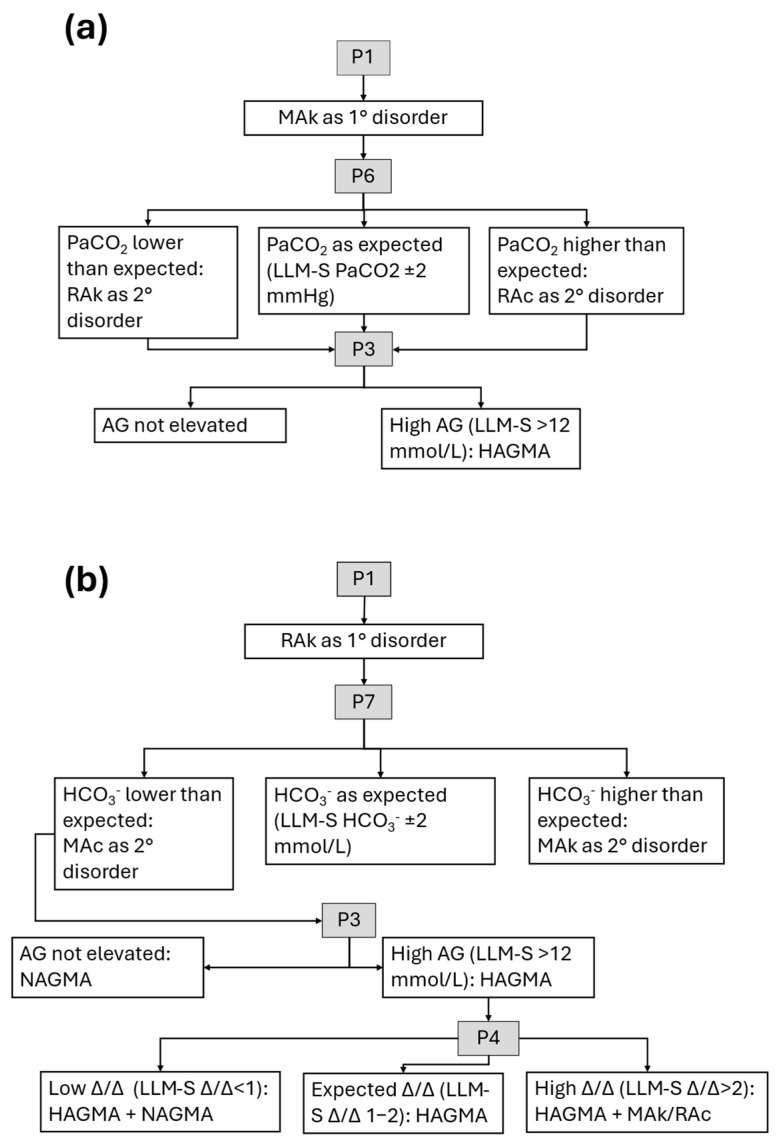
Background and Objectives: Interpreting acid-base disorders is challenging, particularly in complex or mixed cases. Given the growing potential of large language models (LLMs) to assist in cognitively demanding tasks, this study evaluated their performance in interpreting arterial blood gas (ABG) results. Materials and Methods: In this single-center retrospective study, 200 ABG datasets were curated to include 40 cases in each of five diagnostic categories: metabolic acidosis, respiratory acidosis, metabolic alkalosis, respiratory alkalosis, and no acid-base disorder. Three medical students, each assigned to one LLM (ChatGPT GPT-4o, Copilot GPT-4, or Gemini 1.5-flash/2.5-flash), perform ABG interpretation using two evaluation methods: interpretation (LLM-I) and interpretation with supervision model (LLM-S). Two clinical pathologists independently performed the conventional evaluation to serve as the reference standard. Results: Agreement for identifying the primary acid-base (APD) disorder was strong across all approaches (Cohen's κ ≥ 0.88). For identifying both primary and secondary disorders regardless of order (APSD), LLM-I showed moderate agreement (ChatGPT κ = 0.65, Copilot κ = 0.61, Gemini κ = 0.62), whereas LLM-S achieved strong agreement (ChatGPT κ = 0.91, Copilot κ = 0.81, Gemini κ = 0.81). Conclusions: LLM-assisted ABG interpretation demonstrates strong concordance with expert interpretation in detecting primary acid-base disorders. These tools may enhance the understanding of acid-base disorders while reducing calculation-related errors among medical students.
期刊介绍:
Journal of Clinical Medicine (ISSN 2077-0383), is an international scientific open access journal, providing a platform for advances in health care/clinical practices, the study of direct observation of patients and general medical research. This multi-disciplinary journal is aimed at a wide audience of medical researchers and healthcare professionals.
Unique features of this journal:
manuscripts regarding original research and ideas will be particularly welcomed.JCM also accepts reviews, communications, and short notes.
There is no limit to publication length: our aim is to encourage scientists to publish their experimental and theoretical results in as much detail as possible.

 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


