MP-CreditINT:通过基于信用的拥塞控制和带内网络遥测增强多路径RDMA传输
IF 4.6
2区 计算机科学
Q1 COMPUTER SCIENCE, HARDWARE & ARCHITECTURE
引用次数: 0
摘要
远程直接内存访问(RDMA)通过支持跨gpu的低延迟、高吞吐量通信,在最近的大语言模型(LLM)训练工作负载中发挥了关键作用。为了进一步提高网络效率,多径RDMA传输越来越受到人们的关注。考虑到RDMA网卡的片上资源有限,MP-RDMA通过采用内存高效机制来解决拥塞和乱序控制,从而脱颖而出,成为最先进的多路径传输。然而,MP-RDMA依赖于ECN,它只提供粗粒度的二进制拥塞信号,导致拥塞控制能力有限。我们的实验观察揭示了MP-RDMA固有的局限性,如缓慢的带宽探测,队列建立中的大振荡,以及瞬态拥塞等。这些限制降低了网络效率,特别是在All-To-All通信模式下,随着专家混合(MoE)模型和专家并行的发展,这种通信模式正变得越来越占主导地位。为了解决这些限制并保留MP-RDMA的内存效率特性,我们提出了MP-CreditINT。这种方法使用基于信用的拥塞控制和带内网络遥测(INT)重新构建MP-RDMA。我们系统地列举并解决了这种转变所带来的架构和算法挑战,包括显式路径控制和路径对称,基于int的数据时钟信用窗口控制,以及对反馈回路破坏的鲁棒性。然后,我们使用微基准测试、大量输入流量和LLM培训工作负载来评估MP-CreditINT。仿真结果表明,与MP-RDMA相比,MP-CreditINT的上升速度提高了6 - 38倍,公平性收敛速度提高了8 - 16倍,同时失序度保持在接近零的水平。在重铸场景下,它实现了优越的公平性和接近于零的队列构建,而MP-RDMA随着铸规模的增加呈现指数级的队列增长。最后,在两种具有代表性的LLM培训工作负载All-Reduce和All-To-All下,MP-CreditINT与MP-RDMA相比,完成时间分别减少了5%-8%和7%-13%,显示了其在LLM培训中的优势。本文章由计算机程序翻译,如有差异,请以英文原文为准。
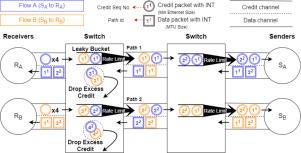
MP-CreditINT: Enhancing multi-path RDMA transport with credit-based congestion control and in-band network telemetry
Remote Direct Memory Access (RDMA) has played a critical role in recent Large-Language-Model (LLM) training workloads by enabling low-latency, high-throughput communication across GPUs. To further improve network efficiency, multi-path RDMA transport has received increasing attention. Given the limited on-chip resources of RDMA NICs, MP-RDMA stands out as a state-of-the-art multi-path transport by adopting memory-efficient mechanisms for congestion and out-of-order control. However, MP-RDMA relies on ECN, which provides only coarse-grained binary congestion signals, resulting in limited congestion control capabilities. Our experimental observations reveal intrinsic limitations of MP-RDMA, such as slow bandwidth probing, large oscillations in queue buildup, and transient congestion, etc. These limitations reduce the network efficiency, especially under All-To-All communication patterns that are becoming increasingly dominant with the evolution of Mixture-of-Experts (MoE) models and Expert Parallelism.
To address these limitations and retain the memory-efficient property of MP-RDMA, we propose the MP-CreditINT. This approach re-architects MP-RDMA using credit-based congestion control and in-band network telemetry (INT). We systematically enumerate and address the architectural and algorithmic challenges arising from this transformation, including explicit path control and path symmetry, INT-based data-clocking credit window control, and robustness against feedback loop breakage. Then, we evaluate MP-CreditINT using micro-benchmarks, heavy incast traffic, and LLM training workloads. Simulation results demonstrate that when compared to MP-RDMA, MP-CreditINT achieves 6–38× faster ramp-up speed and 8–16× faster fairness convergence, while maintaining near-zero out-of-order degree. In heavy incast scenarios, it achieves superior fairness and near-zero queue buildup, whereas MP-RDMA exhibits exponential queue growth with increasing incast scale. Finally, under two representative LLM training workloads, All-Reduce and All-To-All, MP-CreditINT reduces completion time by 5%–8% and 7%–13% respectively when compared to MP-RDMA, demonstrating its benefits in LLM training.
求助全文
通过发布文献求助,成功后即可免费获取论文全文。
去求助
来源期刊

Computer Networks
工程技术-电信学
CiteScore
10.80
自引率
3.60%
发文量
434
审稿时长
8.6 months
期刊介绍:
Computer Networks is an international, archival journal providing a publication vehicle for complete coverage of all topics of interest to those involved in the computer communications networking area. The audience includes researchers, managers and operators of networks as well as designers and implementors. The Editorial Board will consider any material for publication that is of interest to those groups.
 求助内容:
求助内容: 应助结果提醒方式:
应助结果提醒方式:


